 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHDMapGen: A Hierarchical Graph Generative Model of High Definition Maps
Jun 28, 2021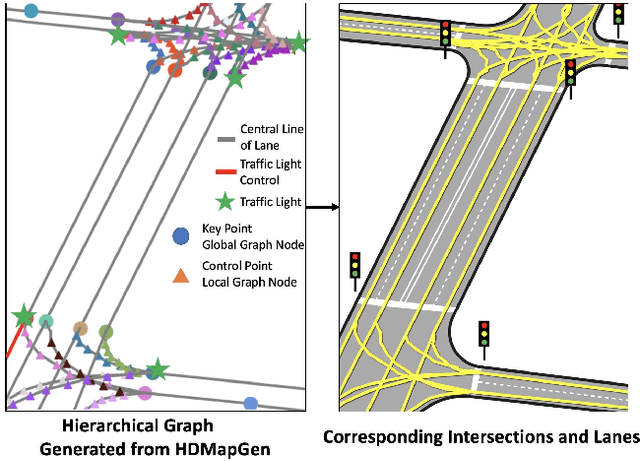
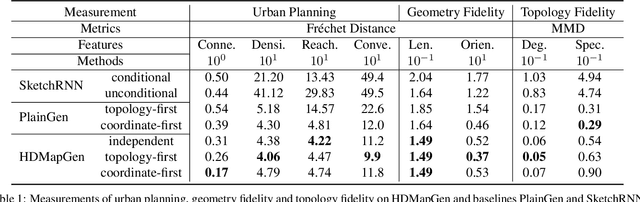
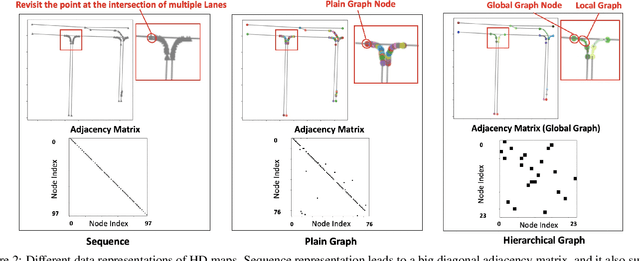

High Definition (HD) maps are maps with precise definitions of road lanes with rich semantics of the traffic rules. They are critical for several key stages in an autonomous driving system, including motion forecasting and planning. However, there are only a small amount of real-world road topologies and geometries, which significantly limits our ability to test out the self-driving stack to generalize onto new unseen scenarios. To address this issue, we introduce a new challenging task to generate HD maps. In this work, we explore several autoregressive models using different data representations, including sequence, plain graph, and hierarchical graph. We propose HDMapGen, a hierarchical graph generation model capable of producing high-quality and diverse HD maps through a coarse-to-fine approach. Experiments on the Argoverse dataset and an in-house dataset show that HDMapGen significantly outperforms baseline methods. Additionally, we demonstrate that HDMapGen achieves high scalability and efficiency.
TNT: Target-driveN Trajectory Prediction
Aug 21, 2020



Predicting the future behavior of moving agents is essential for real world applications. It is challenging as the intent of the agent and the corresponding behavior is unknown and intrinsically multimodal. Our key insight is that for prediction within a moderate time horizon, the future modes can be effectively captured by a set of target states. This leads to our target-driven trajectory prediction (TNT) framework. TNT has three stages which are trained end-to-end. It first predicts an agent's potential target states $T$ steps into the future, by encoding its interactions with the environment and the other agents. TNT then generates trajectory state sequences conditioned on targets. A final stage estimates trajectory likelihoods and a final compact set of trajectory predictions is selected. This is in contrast to previous work which models agent intents as latent variables, and relies on test-time sampling to generate diverse trajectories. We benchmark TNT on trajectory prediction of vehicles and pedestrians, where we outperform state-of-the-art on Argoverse Forecasting, INTERACTION, Stanford Drone and an in-house Pedestrian-at-Intersection dataset.
VectorNet: Encoding HD Maps and Agent Dynamics from Vectorized Representation
May 08, 2020

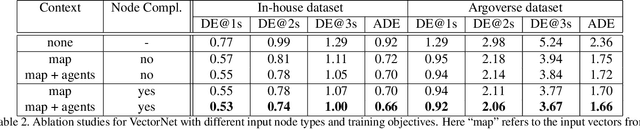
Behavior prediction in dynamic, multi-agent systems is an important problem in the context of self-driving cars, due to the complex representations and interactions of road components, including moving agents (e.g. pedestrians and vehicles) and road context information (e.g. lanes, traffic lights). This paper introduces VectorNet, a hierarchical graph neural network that first exploits the spatial locality of individual road components represented by vectors and then models the high-order interactions among all components. In contrast to most recent approaches, which render trajectories of moving agents and road context information as bird-eye images and encode them with convolutional neural networks (ConvNets), our approach operates on a vector representation. By operating on the vectorized high definition (HD) maps and agent trajectories, we avoid lossy rendering and computationally intensive ConvNet encoding steps. To further boost VectorNet's capability in learning context features, we propose a novel auxiliary task to recover the randomly masked out map entities and agent trajectories based on their context. We evaluate VectorNet on our in-house behavior prediction benchmark and the recently released Argoverse forecasting dataset. Our method achieves on par or better performance than the competitive rendering approach on both benchmarks while saving over 70% of the model parameters with an order of magnitude reduction in FLOPs. It also outperforms the state of the art on the Argoverse dataset.
STINet: Spatio-Temporal-Interactive Network for Pedestrian Detection and Trajectory Prediction
May 08, 2020

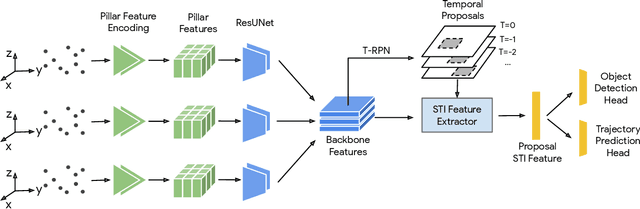
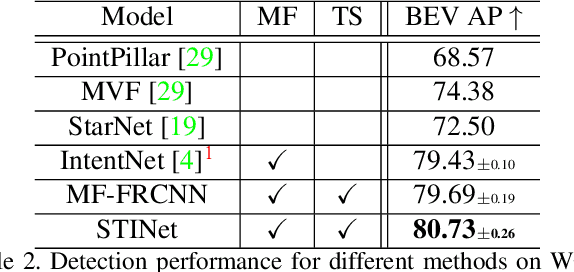
Detecting pedestrians and predicting future trajectories for them are critical tasks for numerous applications, such as autonomous driving. Previous methods either treat the detection and prediction as separate tasks or simply add a trajectory regression head on top of a detector. In this work, we present a novel end-to-end two-stage network: Spatio-Temporal-Interactive Network (STINet). In addition to 3D geometry modeling of pedestrians, we model the temporal information for each of the pedestrians. To do so, our method predicts both current and past locations in the first stage, so that each pedestrian can be linked across frames and the comprehensive spatio-temporal information can be captured in the second stage. Also, we model the interaction among objects with an interaction graph, to gather the information among the neighboring objects. Comprehensive experiments on the Lyft Dataset and the recently released large-scale Waymo Open Dataset for both object detection and future trajectory prediction validate the effectiveness of the proposed method. For the Waymo Open Dataset, we achieve a bird-eyes-view (BEV) detection AP of 80.73 and trajectory prediction average displacement error (ADE) of 33.67cm for pedestrians, which establish the state-of-the-art for both tasks.
CPARR: Category-based Proposal Analysis for Referring Relationships
Apr 17, 2020
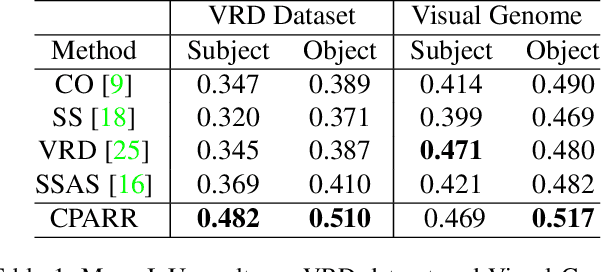
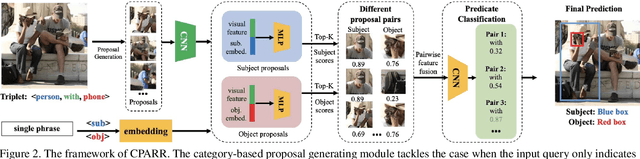
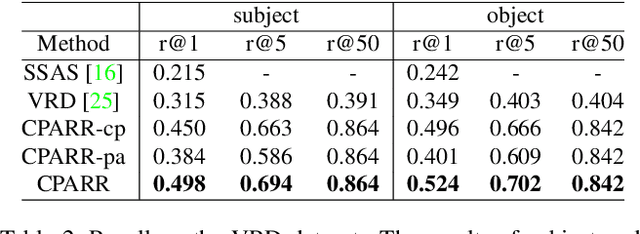
The task of referring relationships is to localize subject and object entities in an image satisfying a relationship query, which is given in the form of \texttt{<subject, predicate, object>}. This requires simultaneous localization of the subject and object entities in a specified relationship. We introduce a simple yet effective proposal-based method for referring relationships. Different from the existing methods such as SSAS, our method can generate a high-resolution result while reducing its complexity and ambiguity. Our method is composed of two modules: a category-based proposal generation module to select the proposals related to the entities and a predicate analysis module to score the compatibility of pairs of selected proposals. We show state-of-the-art performance on the referring relationship task on two public datasets: Visual Relationship Detection and Visual Genome.
End-to-End Multi-View Fusion for 3D Object Detection in LiDAR Point Clouds
Oct 23, 2019



Recent work on 3D object detection advocates point cloud voxelization in birds-eye view, where objects preserve their physical dimensions and are naturally separable. When represented in this view, however, point clouds are sparse and have highly variable point density, which may cause detectors difficulties in detecting distant or small objects (pedestrians, traffic signs, etc.). On the other hand, perspective view provides dense observations, which could allow more favorable feature encoding for such cases. In this paper, we aim to synergize the birds-eye view and the perspective view and propose a novel end-to-end multi-view fusion (MVF) algorithm, which can effectively learn to utilize the complementary information from both. Specifically, we introduce dynamic voxelization, which has four merits compared to existing voxelization methods, i) removing the need of pre-allocating a tensor with fixed size; ii) overcoming the information loss due to stochastic point/voxel dropout; iii) yielding deterministic voxel embeddings and more stable detection outcomes; iv) establishing the bi-directional relationship between points and voxels, which potentially lays a natural foundation for cross-view feature fusion. By employing dynamic voxelization, the proposed feature fusion architecture enables each point to learn to fuse context information from different views. MVF operates on points and can be naturally extended to other approaches using LiDAR point clouds. We evaluate our MVF model extensively on the newly released Waymo Open Dataset and on the KITTI dataset and demonstrate that it significantly improves detection accuracy over the comparable single-view PointPillars baseline.
MAC: Mining Activity Concepts for Language-based Temporal Localization
Nov 21, 2018
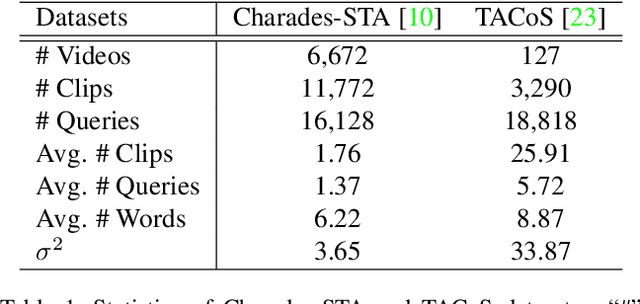

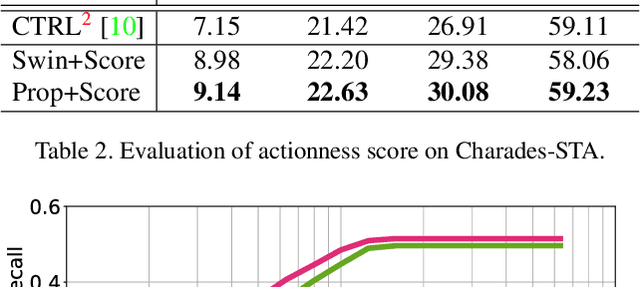
We address the problem of language-based temporal localization in untrimmed videos. Compared to temporal localization with fixed categories, this problem is more challenging as the language-based queries not only have no pre-defined activity list but also may contain complex descriptions. Previous methods address the problem by considering features from video sliding windows and language queries and learning a subspace to encode their correlation, which ignore rich semantic cues about activities in videos and queries. We propose to mine activity concepts from both video and language modalities by applying the actionness score enhanced Activity Concepts based Localizer (ACL). Specifically, the novel ACL encodes the semantic concepts from verb-obj pairs in language queries and leverages activity classifiers' prediction scores to encode visual concepts. Besides, ACL also has the capability to regress sliding windows as localization results. Experiments show that ACL significantly outperforms state-of-the-arts under the widely used metric, with more than 5% increase on both Charades-STA and TACoS datasets.
CTAP: Complementary Temporal Action Proposal Generation
Jul 18, 2018



Temporal action proposal generation is an important task, akin to object proposals, temporal action proposals are intended to capture "clips" or temporal intervals in videos that are likely to contain an action. Previous methods can be divided to two groups: sliding window ranking and actionness score grouping. Sliding windows uniformly cover all segments in videos, but the temporal boundaries are imprecise; grouping based method may have more precise boundaries but it may omit some proposals when the quality of actionness score is low. Based on the complementary characteristics of these two methods, we propose a novel Complementary Temporal Action Proposal (CTAP) generator. Specifically, we apply a Proposal-level Actionness Trustworthiness Estimator (PATE) on the sliding windows proposals to generate the probabilities indicating whether the actions can be correctly detected by actionness scores, the windows with high scores are collected. The collected sliding windows and actionness proposals are then processed by a temporal convolutional neural network for proposal ranking and boundary adjustment. CTAP outperforms state-of-the-art methods on average recall (AR) by a large margin on THUMOS-14 and ActivityNet 1.3 datasets. We further apply CTAP as a proposal generation method in an existing action detector, and show consistent significant improvements.
Revisiting Temporal Modeling for Video-based Person ReID
May 08, 2018



Video-based person reID is an important task, which has received much attention in recent years due to the increasing demand in surveillance and camera networks. A typical video-based person reID system consists of three parts: an image-level feature extractor (e.g. CNN), a temporal modeling method to aggregate temporal features and a loss function. Although many methods on temporal modeling have been proposed, it is hard to directly compare these methods, because the choice of feature extractor and loss function also have a large impact on the final performance. We comprehensively study and compare four different temporal modeling methods (temporal pooling, temporal attention, RNN and 3D convnets) for video-based person reID. We also propose a new attention generation network which adopts temporal convolution to extract temporal information among frames. The evaluation is done on the MARS dataset, and our methods outperform state-of-the-art methods by a large margin. Our source codes are released at https://github.com/jiyanggao/Video-Person-ReID.
Motion-Appearance Co-Memory Networks for Video Question Answering
Mar 29, 2018

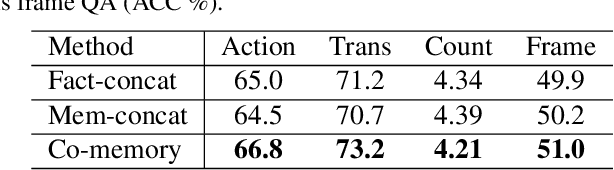

Video Question Answering (QA) is an important task in understanding video temporal structure. We observe that there are three unique attributes of video QA compared with image QA: (1) it deals with long sequences of images containing richer information not only in quantity but also in variety; (2) motion and appearance information are usually correlated with each other and able to provide useful attention cues to the other; (3) different questions require different number of frames to infer the answer. Based these observations, we propose a motion-appearance comemory network for video QA. Our networks are built on concepts from Dynamic Memory Network (DMN) and introduces new mechanisms for video QA. Specifically, there are three salient aspects: (1) a co-memory attention mechanism that utilizes cues from both motion and appearance to generate attention; (2) a temporal conv-deconv network to generate multi-level contextual facts; (3) a dynamic fact ensemble method to construct temporal representation dynamically for different questions. We evaluate our method on TGIF-QA dataset, and the results outperform state-of-the-art significantly on all four tasks of TGIF-QA.