 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Laws of Motion Forecasting and Planning -- A Technical Report
Jun 09, 2025We study the empirical scaling laws of a family of encoder-decoder autoregressive transformer models on the task of joint motion forecasting and planning in the autonomous driving domain. Using a 500 thousand hours driving dataset, we demonstrate that, similar to language modeling, model performance improves as a power-law function of the total compute budget, and we observe a strong correlation between model training loss and model evaluation metrics. Most interestingly, closed-loop metrics also improve with scaling, which has important implications for the suitability of open-loop metrics for model development and hill climbing. We also study the optimal scaling of the number of transformer parameters and the training data size for a training compute-optimal model. We find that as the training compute budget grows, optimal scaling requires increasing the model size 1.5x as fast as the dataset size. We also study inference-time compute scaling, where we observe that sampling and clustering the output of smaller models makes them competitive with larger models, up to a crossover point beyond which a larger models becomes more inference-compute efficient. Overall, our experimental results demonstrate that optimizing the training and inference-time scaling properties of motion forecasting and planning models is a key lever for improving their performance to address a wide variety of driving scenarios. Finally, we briefly study the utility of training on general logged driving data of other agents to improve the performance of the ego-agent, an important research area to address the scarcity of robotics data for large capacity models training.
EMMA: End-to-End Multimodal Model for Autonomous Driving
Oct 30, 2024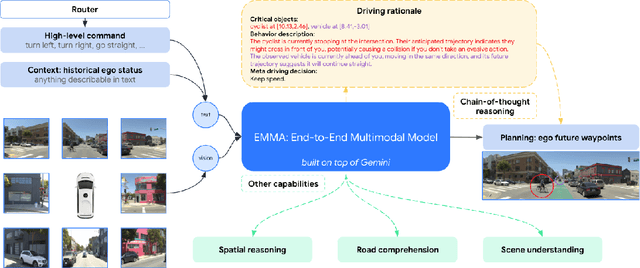
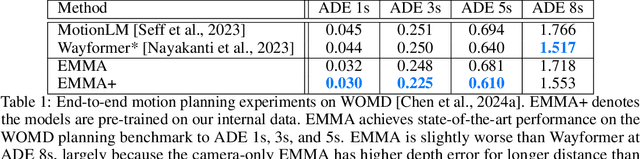
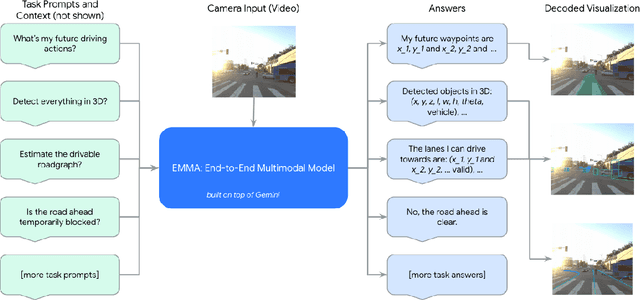
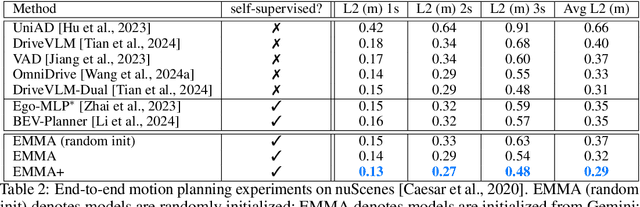
We introduce EMMA, an End-to-end Multimodal Model for Autonomous driving. Built on a multi-modal large language model foundation, EMMA directly maps raw camera sensor data into various driving-specific outputs, including planner trajectories, perception objects, and road graph elements. EMMA maximizes the utility of world knowledge from the pre-trained large language models, by representing all non-sensor inputs (e.g. navigation instructions and ego vehicle status) and outputs (e.g. trajectories and 3D locations) as natural language text. This approach allows EMMA to jointly process various driving tasks in a unified language space, and generate the outputs for each task using task-specific prompts. Empirically, we demonstrate EMMA's effectiveness by achieving state-of-the-art performance in motion planning on nuScenes as well as competitive results on the Waymo Open Motion Dataset (WOMD). EMMA also yields competitive results for camera-primary 3D object detection on the Waymo Open Dataset (WOD). We show that co-training EMMA with planner trajectories, object detection, and road graph tasks yields improvements across all three domains, highlighting EMMA's potential as a generalist model for autonomous driving applications. However, EMMA also exhibits certain limitations: it can process only a small amount of image frames, does not incorporate accurate 3D sensing modalities like LiDAR or radar and is computationally expensive. We hope that our results will inspire further research to mitigate these issues and to further evolve the state of the art in autonomous driving model architectures.
Waymax: An Accelerated, Data-Driven Simulator for Large-Scale Autonomous Driving Research
Oct 12, 2023
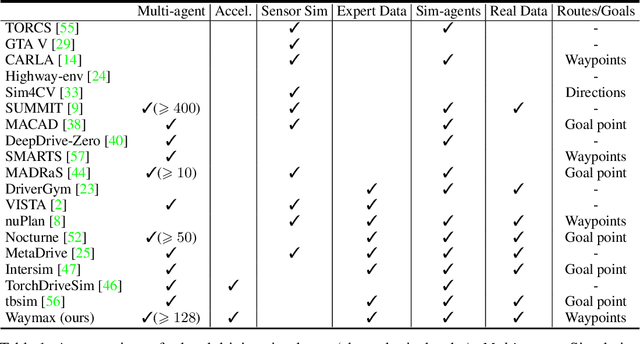
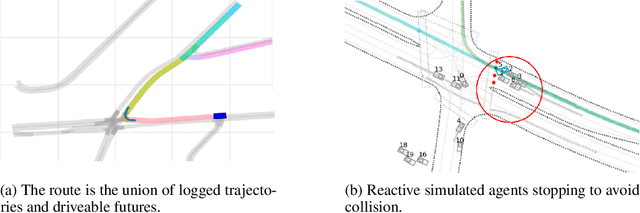
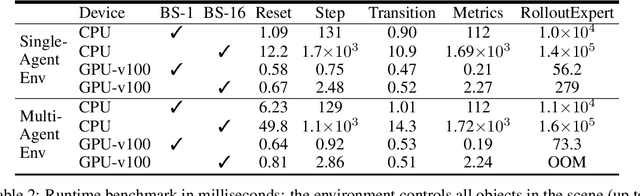
Simulation is an essential tool to develop and benchmark autonomous vehicle planning software in a safe and cost-effective manner. However, realistic simulation requires accurate modeling of nuanced and complex multi-agent interactive behaviors. To address these challenges, we introduce Waymax, a new data-driven simulator for autonomous driving in multi-agent scenes, designed for large-scale simulation and testing. Waymax uses publicly-released, real-world driving data (e.g., the Waymo Open Motion Dataset) to initialize or play back a diverse set of multi-agent simulated scenarios. It runs entirely on hardware accelerators such as TPUs/GPUs and supports in-graph simulation for training, making it suitable for modern large-scale, distributed machine learning workflows. To support online training and evaluation, Waymax includes several learned and hard-coded behavior models that allow for realistic interaction within simulation. To supplement Waymax, we benchmark a suite of popular imitation and reinforcement learning algorithms with ablation studies on different design decisions, where we highlight the effectiveness of routes as guidance for planning agents and the ability of RL to overfit against simulated agents.
MotionLM: Multi-Agent Motion Forecasting as Language Modeling
Sep 28, 2023Reliable forecasting of the future behavior of road agents is a critical component to safe planning in autonomous vehicles. Here, we represent continuous trajectories as sequences of discrete motion tokens and cast multi-agent motion prediction as a language modeling task over this domain. Our model, MotionLM, provides several advantages: First, it does not require anchors or explicit latent variable optimization to learn multimodal distributions. Instead, we leverage a single standard language modeling objective, maximizing the average log probability over sequence tokens. Second, our approach bypasses post-hoc interaction heuristics where individual agent trajectory generation is conducted prior to interactive scoring. Instead, MotionLM produces joint distributions over interactive agent futures in a single autoregressive decoding process. In addition, the model's sequential factorization enables temporally causal conditional rollouts. The proposed approach establishes new state-of-the-art performance for multi-agent motion prediction on the Waymo Open Motion Dataset, ranking 1st on the interactive challenge leaderboard.
Imitation Is Not Enough: Robustifying Imitation with Reinforcement Learning for Challenging Driving Scenarios
Dec 21, 2022



Imitation learning (IL) is a simple and powerful way to use high-quality human driving data, which can be collected at scale, to identify driving preferences and produce human-like behavior. However, policies based on imitation learning alone often fail to sufficiently account for safety and reliability concerns. In this paper, we show how imitation learning combined with reinforcement learning using simple rewards can substantially improve the safety and reliability of driving policies over those learned from imitation alone. In particular, we use a combination of imitation and reinforcement learning to train a policy on over 100k miles of urban driving data, and measure its effectiveness in test scenarios grouped by different levels of collision risk. To our knowledge, this is the first application of a combined imitation and reinforcement learning approach in autonomous driving that utilizes large amounts of real-world human driving data.
JFP: Joint Future Prediction with Interactive Multi-Agent Modeling for Autonomous Driving
Dec 16, 2022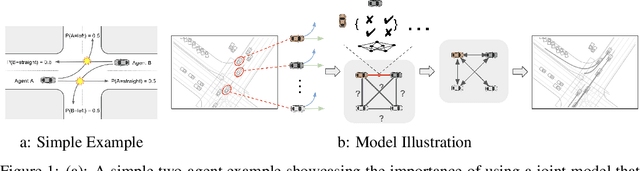
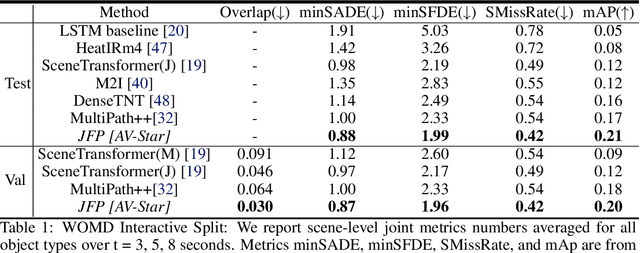
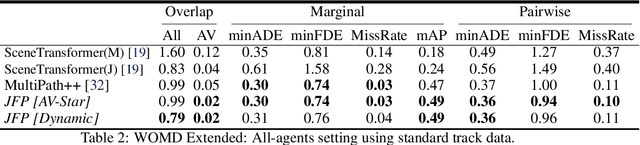
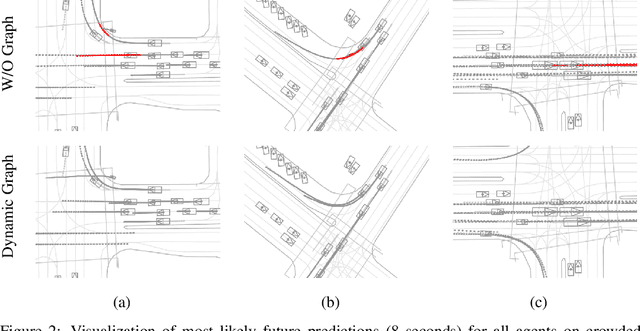
We propose JFP, a Joint Future Prediction model that can learn to generate accurate and consistent multi-agent future trajectories. For this task, many different methods have been proposed to capture social interactions in the encoding part of the model, however, considerably less focus has been placed on representing interactions in the decoder and output stages. As a result, the predicted trajectories are not necessarily consistent with each other, and often result in unrealistic trajectory overlaps. In contrast, we propose an end-to-end trainable model that learns directly the interaction between pairs of agents in a structured, graphical model formulation in order to generate consistent future trajectories. It sets new state-of-the-art results on Waymo Open Motion Dataset (WOMD) for the interactive setting. We also investigate a more complex multi-agent setting for both WOMD and a larger internal dataset, where our approach improves significantly on the trajectory overlap metrics while obtaining on-par or better performance on single-agent trajectory metrics.
Wayformer: Motion Forecasting via Simple & Efficient Attention Networks
Jul 12, 2022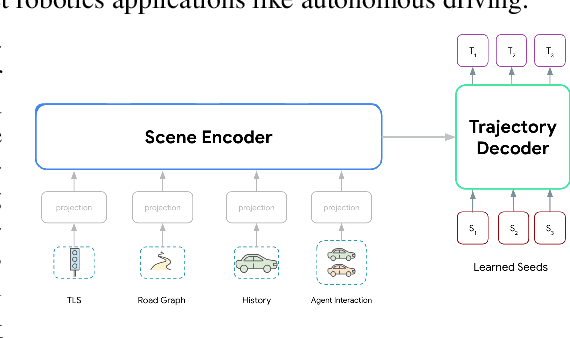
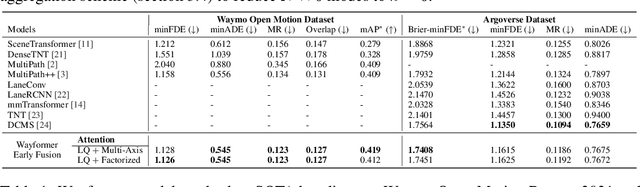
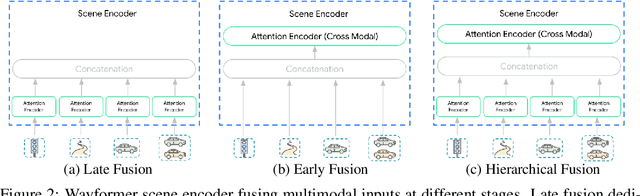
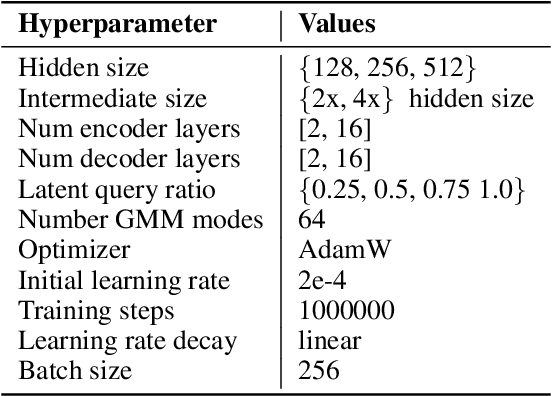
Motion forecasting for autonomous driving is a challenging task because complex driving scenarios result in a heterogeneous mix of static and dynamic inputs. It is an open problem how best to represent and fuse information about road geometry, lane connectivity, time-varying traffic light state, and history of a dynamic set of agents and their interactions into an effective encoding. To model this diverse set of input features, many approaches proposed to design an equally complex system with a diverse set of modality specific modules. This results in systems that are difficult to scale, extend, or tune in rigorous ways to trade off quality and efficiency. In this paper, we present Wayformer, a family of attention based architectures for motion forecasting that are simple and homogeneous. Wayformer offers a compact model description consisting of an attention based scene encoder and a decoder. In the scene encoder we study the choice of early, late and hierarchical fusion of the input modalities. For each fusion type we explore strategies to tradeoff efficiency and quality via factorized attention or latent query attention. We show that early fusion, despite its simplicity of construction, is not only modality agnostic but also achieves state-of-the-art results on both Waymo Open MotionDataset (WOMD) and Argoverse leaderboards, demonstrating the effectiveness of our design philosophy
Narrowing the Coordinate-frame Gap in Behavior Prediction Models: Distillation for Efficient and Accurate Scene-centric Motion Forecasting
Jun 10, 2022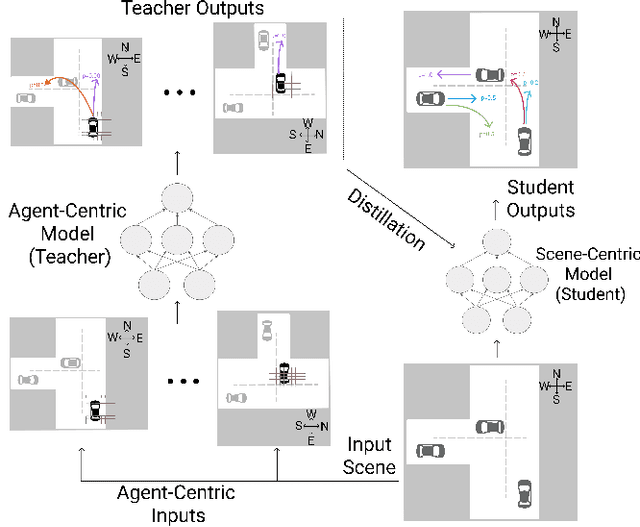
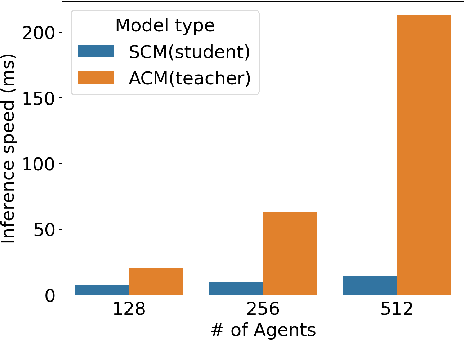
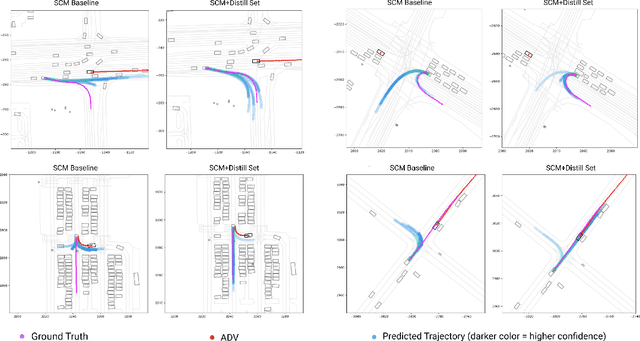
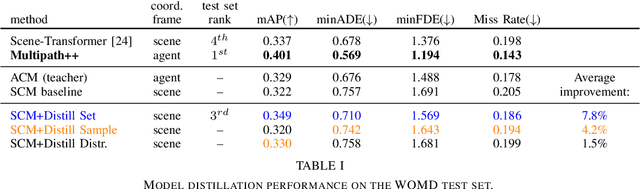
Behavior prediction models have proliferated in recent years, especially in the popular real-world robotics application of autonomous driving, where representing the distribution over possible futures of moving agents is essential for safe and comfortable motion planning. In these models, the choice of coordinate frames to represent inputs and outputs has crucial trade offs which broadly fall into one of two categories. Agent-centric models transform inputs and perform inference in agent-centric coordinates. These models are intrinsically invariant to translation and rotation between scene elements, are best-performing on public leaderboards, but scale quadratically with the number of agents and scene elements. Scene-centric models use a fixed coordinate system to process all agents. This gives them the advantage of sharing representations among all agents, offering efficient amortized inference computation which scales linearly with the number of agents. However, these models have to learn invariance to translation and rotation between scene elements, and typically underperform agent-centric models. In this work, we develop knowledge distillation techniques between probabilistic motion forecasting models, and apply these techniques to close the gap in performance between agent-centric and scene-centric models. This improves scene-centric model performance by 13.2% on the public Argoverse benchmark, 7.8% on Waymo Open Dataset and up to 9.4% on a large In-House dataset. These improved scene-centric models rank highly in public leaderboards and are up to 15 times more efficient than their agent-centric teacher counterparts in busy scenes.
MultiPath++: Efficient Information Fusion and Trajectory Aggregation for Behavior Prediction
Dec 22, 2021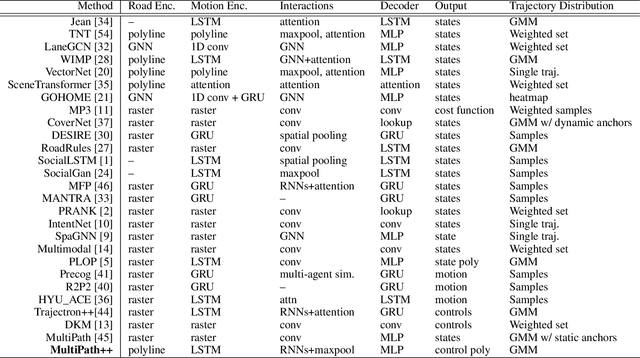
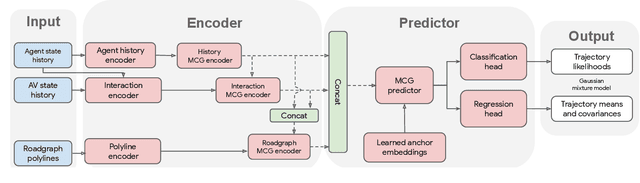
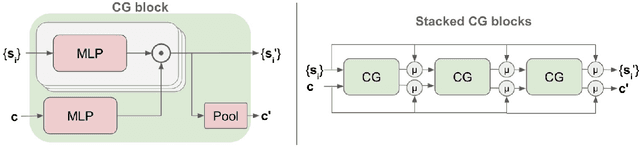
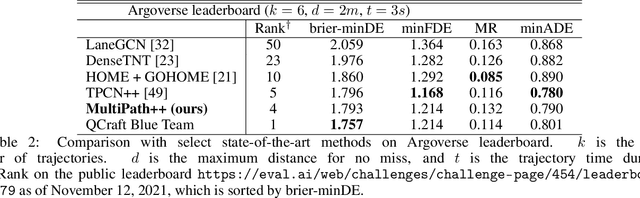
Predicting the future behavior of road users is one of the most challenging and important problems in autonomous driving. Applying deep learning to this problem requires fusing heterogeneous world state in the form of rich perception signals and map information, and inferring highly multi-modal distributions over possible futures. In this paper, we present MultiPath++, a future prediction model that achieves state-of-the-art performance on popular benchmarks. MultiPath++ improves the MultiPath architecture by revisiting many design choices. The first key design difference is a departure from dense image-based encoding of the input world state in favor of a sparse encoding of heterogeneous scene elements: MultiPath++ consumes compact and efficient polylines to describe road features, and raw agent state information directly (e.g., position, velocity, acceleration). We propose a context-aware fusion of these elements and develop a reusable multi-context gating fusion component. Second, we reconsider the choice of pre-defined, static anchors, and develop a way to learn latent anchor embeddings end-to-end in the model. Lastly, we explore ensembling and output aggregation techniques -- common in other ML domains -- and find effective variants for our probabilistic multimodal output representation. We perform an extensive ablation on these design choices, and show that our proposed model achieves state-of-the-art performance on the Argoverse Motion Forecasting Competition and the Waymo Open Dataset Motion Prediction Challenge.
Identifying Driver Interactions via Conditional Behavior Prediction
Apr 20, 2021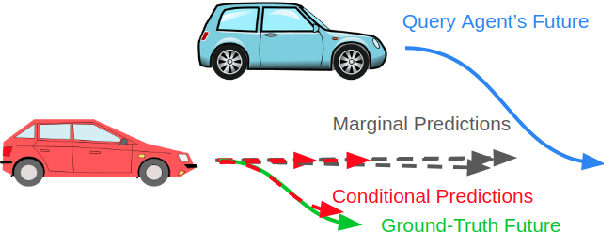
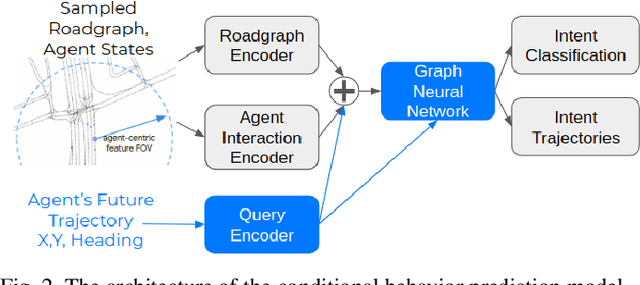
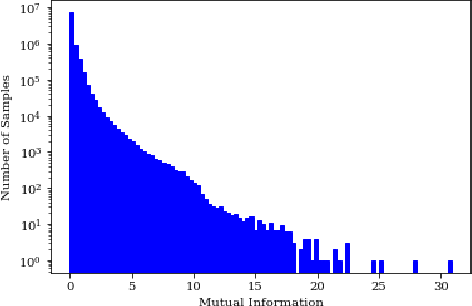
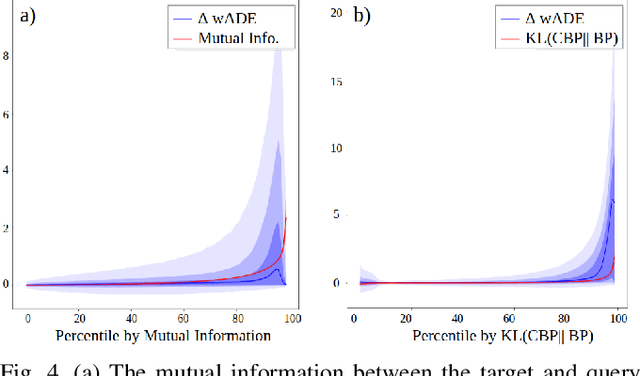
Interactive driving scenarios, such as lane changes, merges and unprotected turns, are some of the most challenging situations for autonomous driving. Planning in interactive scenarios requires accurately modeling the reactions of other agents to different future actions of the ego agent. We develop end-to-end models for conditional behavior prediction (CBP) that take as an input a query future trajectory for an ego-agent, and predict distributions over future trajectories for other agents conditioned on the query. Leveraging such a model, we develop a general-purpose agent interactivity score derived from probabilistic first principles. The interactivity score allows us to find interesting interactive scenarios for training and evaluating behavior prediction models. We further demonstrate that the proposed score is effective for agent prioritization under computational budget constraints.