 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Laws of Motion Forecasting and Planning -- A Technical Report
Jun 09, 2025We study the empirical scaling laws of a family of encoder-decoder autoregressive transformer models on the task of joint motion forecasting and planning in the autonomous driving domain. Using a 500 thousand hours driving dataset, we demonstrate that, similar to language modeling, model performance improves as a power-law function of the total compute budget, and we observe a strong correlation between model training loss and model evaluation metrics. Most interestingly, closed-loop metrics also improve with scaling, which has important implications for the suitability of open-loop metrics for model development and hill climbing. We also study the optimal scaling of the number of transformer parameters and the training data size for a training compute-optimal model. We find that as the training compute budget grows, optimal scaling requires increasing the model size 1.5x as fast as the dataset size. We also study inference-time compute scaling, where we observe that sampling and clustering the output of smaller models makes them competitive with larger models, up to a crossover point beyond which a larger models becomes more inference-compute efficient. Overall, our experimental results demonstrate that optimizing the training and inference-time scaling properties of motion forecasting and planning models is a key lever for improving their performance to address a wide variety of driving scenarios. Finally, we briefly study the utility of training on general logged driving data of other agents to improve the performance of the ego-agent, an important research area to address the scarcity of robotics data for large capacity models training.
Direct Post-Training Preference Alignment for Multi-Agent Motion Generation Models Using Implicit Feedback from Pre-training Demonstrations
Mar 25, 2025Recent advancements in LLMs have revolutionized motion generation models in embodied applications. While LLM-type auto-regressive motion generation models benefit from training scalability, there remains a discrepancy between their token prediction objectives and human preferences. As a result, models pre-trained solely with token-prediction objectives often generate behaviors that deviate from what humans would prefer, making post-training preference alignment crucial for producing human-preferred motions. Unfortunately, post-training alignment requires extensive preference rankings of motions generated by the pre-trained model, which are costly to annotate, especially in multi-agent settings. Recently, there has been growing interest in leveraging pre-training demonstrations to scalably generate preference data for post-training alignment. However, these methods often adopt an adversarial assumption, treating all pre-trained model-generated samples as unpreferred examples. This adversarial approach overlooks the valuable signal provided by preference rankings among the model's own generations, ultimately reducing alignment effectiveness and potentially leading to misaligned behaviors. In this work, instead of treating all generated samples as equally bad, we leverage implicit preferences encoded in pre-training demonstrations to construct preference rankings among the pre-trained model's generations, offering more nuanced preference alignment guidance with zero human cost. We apply our approach to large-scale traffic simulation and demonstrate its effectiveness in improving the realism of pre-trained model's generated behaviors, making a lightweight 1M motion generation model comparable to SOTA large imitation-based models by relying solely on implicit feedback from pre-training demonstrations, without additional post-training human preference annotations or high computational costs.
MoST: Multi-modality Scene Tokenization for Motion Prediction
Apr 30, 2024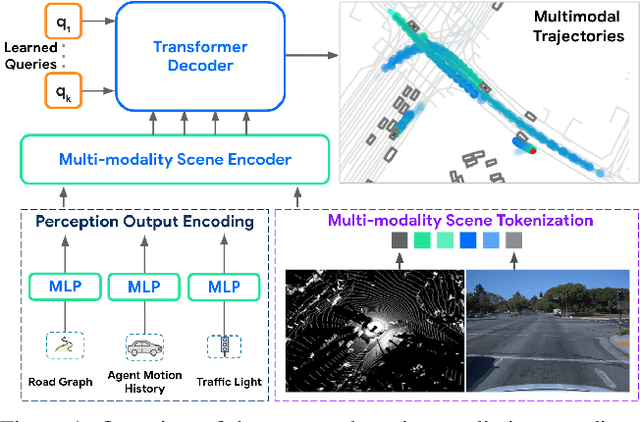

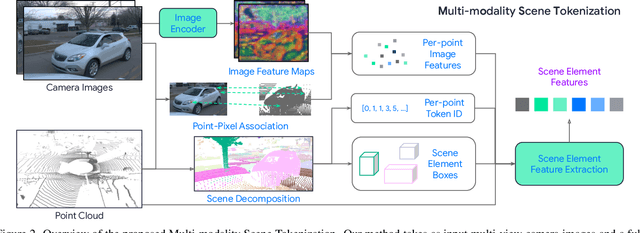
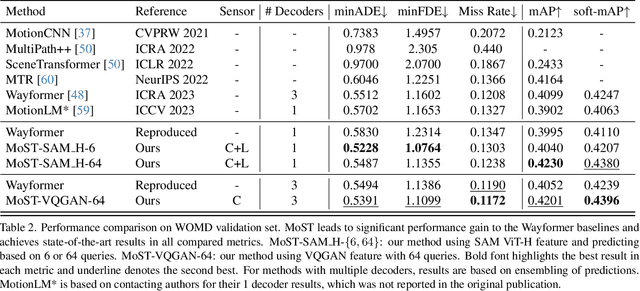
Many existing motion prediction approaches rely on symbolic perception outputs to generate agent trajectories, such as bounding boxes, road graph information and traffic lights. This symbolic representation is a high-level abstraction of the real world, which may render the motion prediction model vulnerable to perception errors (e.g., failures in detecting open-vocabulary obstacles) while missing salient information from the scene context (e.g., poor road conditions). An alternative paradigm is end-to-end learning from raw sensors. However, this approach suffers from the lack of interpretability and requires significantly more training resources. In this work, we propose tokenizing the visual world into a compact set of scene elements and then leveraging pre-trained image foundation models and LiDAR neural networks to encode all the scene elements in an open-vocabulary manner. The image foundation model enables our scene tokens to encode the general knowledge of the open world while the LiDAR neural network encodes geometry information. Our proposed representation can efficiently encode the multi-frame multi-modality observations with a few hundred tokens and is compatible with most transformer-based architectures. To evaluate our method, we have augmented Waymo Open Motion Dataset with camera embeddings. Experiments over Waymo Open Motion Dataset show that our approach leads to significant performance improvements over the state-of-the-art.
Scaling Motion Forecasting Models with Ensemble Distillation
Apr 05, 2024



Motion forecasting has become an increasingly critical component of autonomous robotic systems. Onboard compute budgets typically limit the accuracy of real-time systems. In this work we propose methods of improving motion forecasting systems subject to limited compute budgets by combining model ensemble and distillation techniques. The use of ensembles of deep neural networks has been shown to improve generalization accuracy in many application domains. We first demonstrate significant performance gains by creating a large ensemble of optimized single models. We then develop a generalized framework to distill motion forecasting model ensembles into small student models which retain high performance with a fraction of the computing cost. For this study we focus on the task of motion forecasting using real world data from autonomous driving systems. We develop ensemble models that are very competitive on the Waymo Open Motion Dataset (WOMD) and Argoverse leaderboards. From these ensembles, we train distilled student models which have high performance at a fraction of the compute costs. These experiments demonstrate distillation from ensembles as an effective method for improving accuracy of predictive models for robotic systems with limited compute budgets.
Wayformer: Motion Forecasting via Simple & Efficient Attention Networks
Jul 12, 2022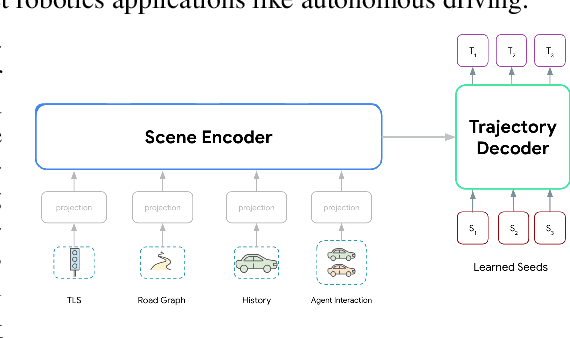
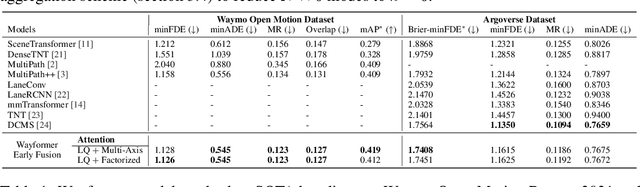
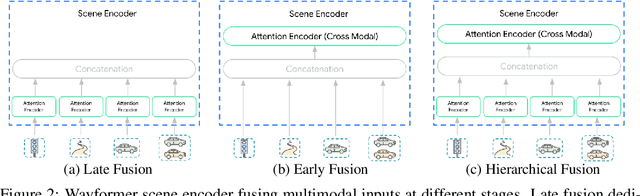
Motion forecasting for autonomous driving is a challenging task because complex driving scenarios result in a heterogeneous mix of static and dynamic inputs. It is an open problem how best to represent and fuse information about road geometry, lane connectivity, time-varying traffic light state, and history of a dynamic set of agents and their interactions into an effective encoding. To model this diverse set of input features, many approaches proposed to design an equally complex system with a diverse set of modality specific modules. This results in systems that are difficult to scale, extend, or tune in rigorous ways to trade off quality and efficiency. In this paper, we present Wayformer, a family of attention based architectures for motion forecasting that are simple and homogeneous. Wayformer offers a compact model description consisting of an attention based scene encoder and a decoder. In the scene encoder we study the choice of early, late and hierarchical fusion of the input modalities. For each fusion type we explore strategies to tradeoff efficiency and quality via factorized attention or latent query attention. We show that early fusion, despite its simplicity of construction, is not only modality agnostic but also achieves state-of-the-art results on both Waymo Open MotionDataset (WOMD) and Argoverse leaderboards, demonstrating the effectiveness of our design philosophy
A Recurrent Latent Variable Model for Sequential Data
Apr 06, 2016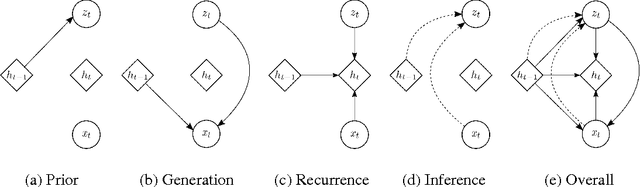
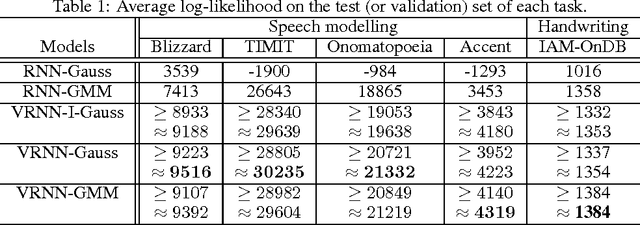
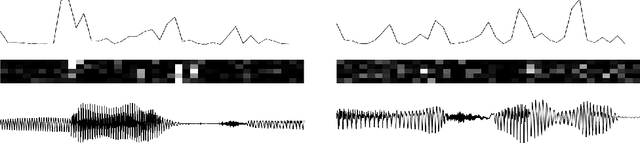
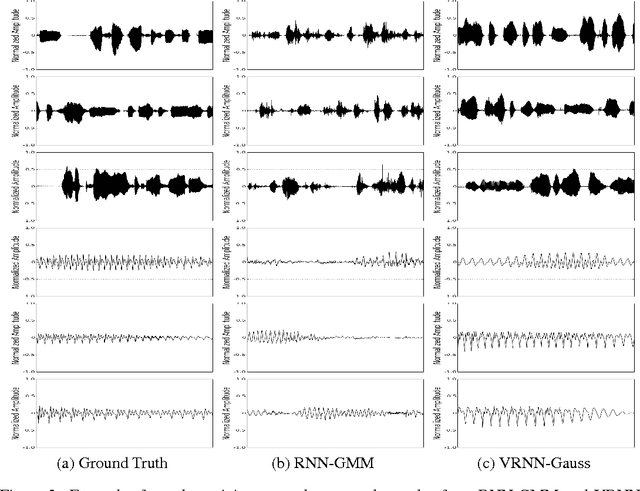
In this paper, we explore the inclusion of latent random variables into the dynamic hidden state of a recurrent neural network (RNN) by combining elements of the variational autoencoder. We argue that through the use of high-level latent random variables, the variational RNN (VRNN)1 can model the kind of variability observed in highly structured sequential data such as natural speech. We empirically evaluate the proposed model against related sequential models on four speech datasets and one handwriting dataset. Our results show the important roles that latent random variables can play in the RNN dynamic hidden state.
A Novel Feature Selection and Extraction Technique for Classification
Dec 26, 2014
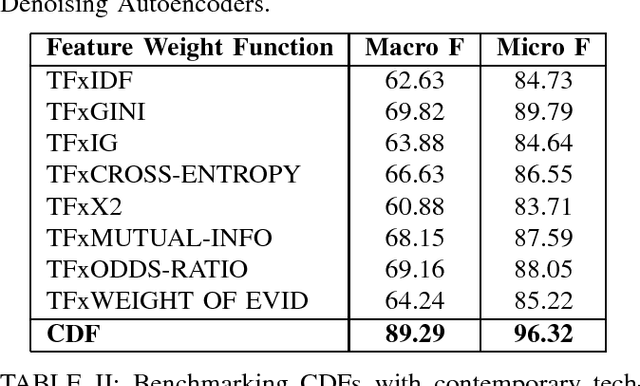
This paper presents a versatile technique for the purpose of feature selection and extraction - Class Dependent Features (CDFs). We use CDFs to improve the accuracy of classification and at the same time control computational expense by tackling the curse of dimensionality. In order to demonstrate the generality of this technique, it is applied to handwritten digit recognition and text categorization.
* 2 pages, 2 tables, published at IEEE SMC 2014
Polyphonic Music Generation by Modeling Temporal Dependencies Using a RNN-DBN
Dec 26, 2014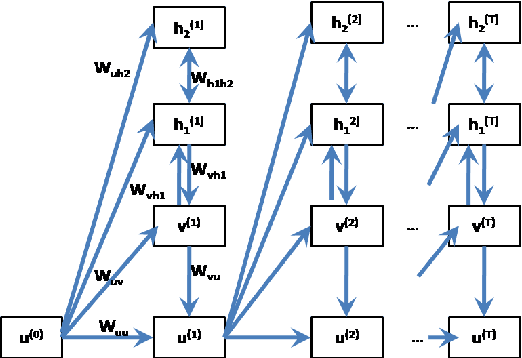
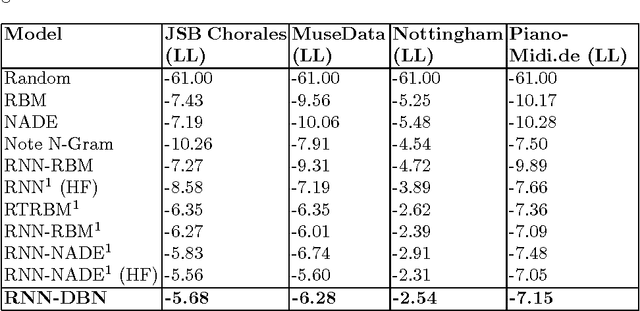
In this paper, we propose a generic technique to model temporal dependencies and sequences using a combination of a recurrent neural network and a Deep Belief Network. Our technique, RNN-DBN, is an amalgamation of the memory state of the RNN that allows it to provide temporal information and a multi-layer DBN that helps in high level representation of the data. This makes RNN-DBNs ideal for sequence generation. Further, the use of a DBN in conjunction with the RNN makes this model capable of significantly more complex data representation than an RBM. We apply this technique to the task of polyphonic music generation.
* 8 pages, A4, 1 figure, 1 table, ICANN 2014 oral presentation. arXiv admin note: text overlap with arXiv:1206.6392 by other authors
Learning Temporal Dependencies in Data Using a DBN-BLSTM
Dec 23, 2014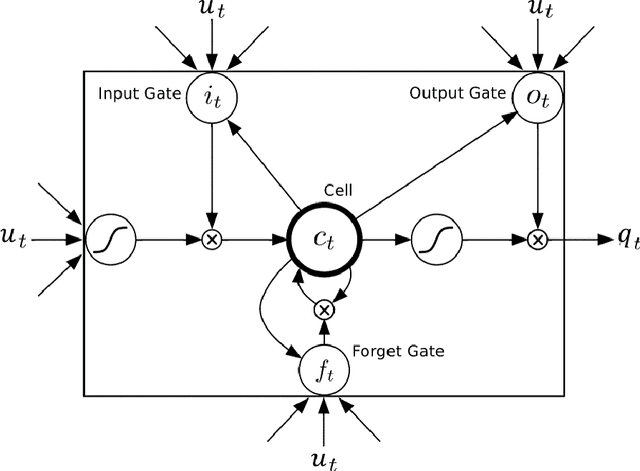
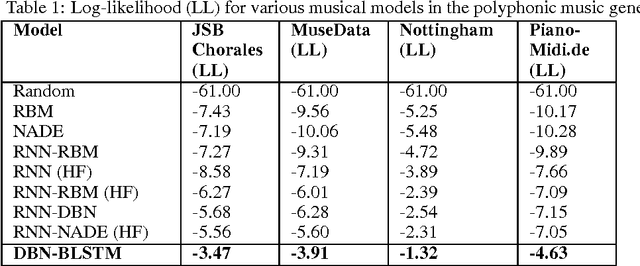
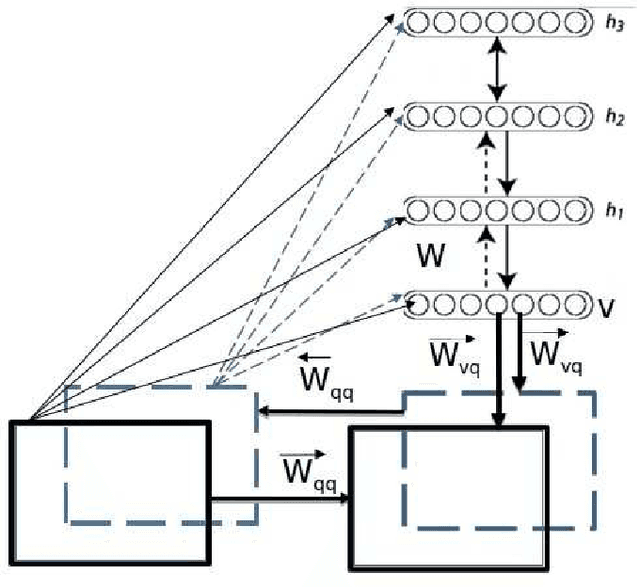
Since the advent of deep learning, it has been used to solve various problems using many different architectures. The application of such deep architectures to auditory data is also not uncommon. However, these architectures do not always adequately consider the temporal dependencies in data. We thus propose a new generic architecture called the Deep Belief Network - Bidirectional Long Short-Term Memory (DBN-BLSTM) network that models sequences by keeping track of the temporal information while enabling deep representations in the data. We demonstrate this new architecture by applying it to the task of music generation and obtain state-of-the-art results.