 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStep-unrolled Denoising Autoencoders for Text Generation
Dec 13, 2021



In this paper we propose a new generative model of text, Step-unrolled Denoising Autoencoder (SUNDAE), that does not rely on autoregressive models. Similarly to denoising diffusion techniques, SUNDAE is repeatedly applied on a sequence of tokens, starting from random inputs and improving them each time until convergence. We present a simple new improvement operator that converges in fewer iterations than diffusion methods, while qualitatively producing better samples on natural language datasets. SUNDAE achieves state-of-the-art results (among non-autoregressive methods) on the WMT'14 English-to-German translation task and good qualitative results on unconditional language modeling on the Colossal Cleaned Common Crawl dataset and a dataset of Python code from GitHub. The non-autoregressive nature of SUNDAE opens up possibilities beyond left-to-right prompted generation, by filling in arbitrary blank patterns in a template.
Iterative Refinement of the Approximate Posterior for Directed Belief Networks
Feb 20, 2018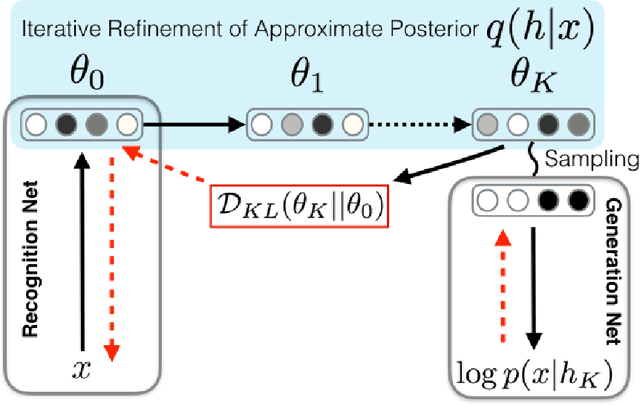
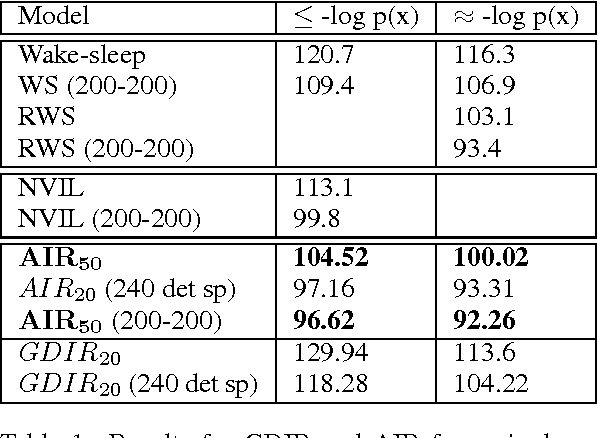

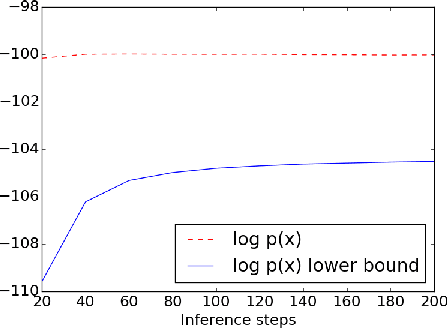
Variational methods that rely on a recognition network to approximate the posterior of directed graphical models offer better inference and learning than previous methods. Recent advances that exploit the capacity and flexibility in this approach have expanded what kinds of models can be trained. However, as a proposal for the posterior, the capacity of the recognition network is limited, which can constrain the representational power of the generative model and increase the variance of Monte Carlo estimates. To address these issues, we introduce an iterative refinement procedure for improving the approximate posterior of the recognition network and show that training with the refined posterior is competitive with state-of-the-art methods. The advantages of refinement are further evident in an increased effective sample size, which implies a lower variance of gradient estimates.
Hierarchical Multiscale Recurrent Neural Networks
Mar 09, 2017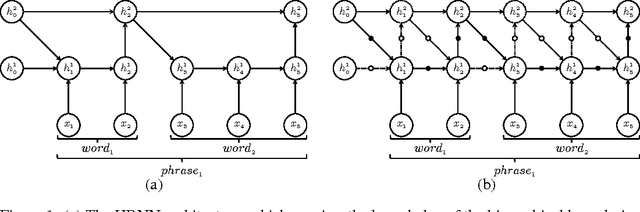
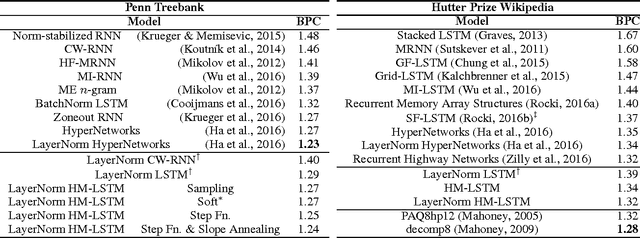


Learning both hierarchical and temporal representation has been among the long-standing challenges of recurrent neural networks. Multiscale recurrent neural networks have been considered as a promising approach to resolve this issue, yet there has been a lack of empirical evidence showing that this type of models can actually capture the temporal dependencies by discovering the latent hierarchical structure of the sequence. In this paper, we propose a novel multiscale approach, called the hierarchical multiscale recurrent neural networks, which can capture the latent hierarchical structure in the sequence by encoding the temporal dependencies with different timescales using a novel update mechanism. We show some evidence that our proposed multiscale architecture can discover underlying hierarchical structure in the sequences without using explicit boundary information. We evaluate our proposed model on character-level language modelling and handwriting sequence modelling.
A Character-Level Decoder without Explicit Segmentation for Neural Machine Translation
Jun 21, 2016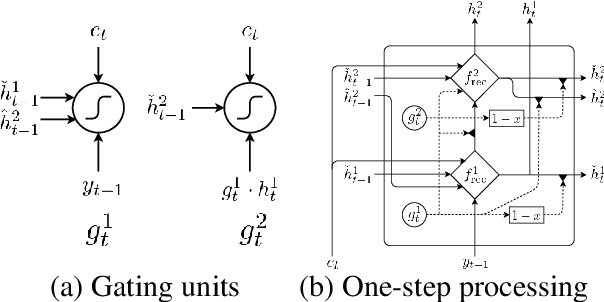
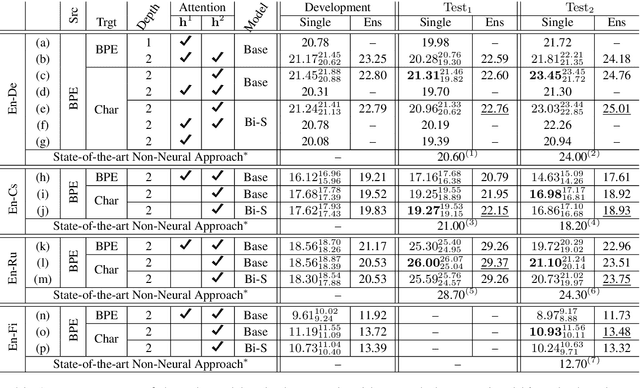
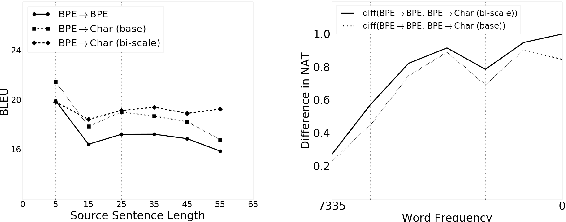

The existing machine translation systems, whether phrase-based or neural, have relied almost exclusively on word-level modelling with explicit segmentation. In this paper, we ask a fundamental question: can neural machine translation generate a character sequence without any explicit segmentation? To answer this question, we evaluate an attention-based encoder-decoder with a subword-level encoder and a character-level decoder on four language pairs--En-Cs, En-De, En-Ru and En-Fi-- using the parallel corpora from WMT'15. Our experiments show that the models with a character-level decoder outperform the ones with a subword-level decoder on all of the four language pairs. Furthermore, the ensembles of neural models with a character-level decoder outperform the state-of-the-art non-neural machine translation systems on En-Cs, En-De and En-Fi and perform comparably on En-Ru.
A Recurrent Latent Variable Model for Sequential Data
Apr 06, 2016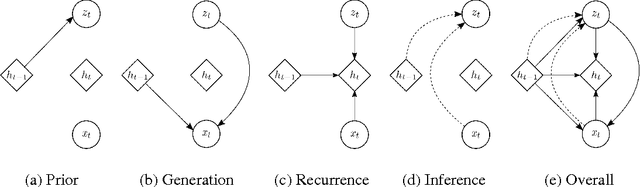
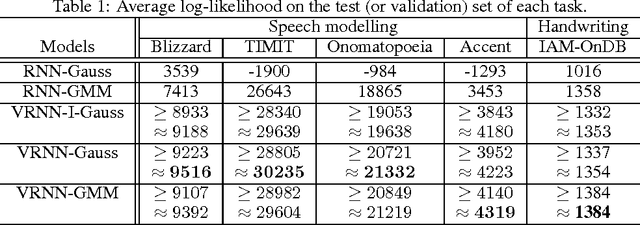
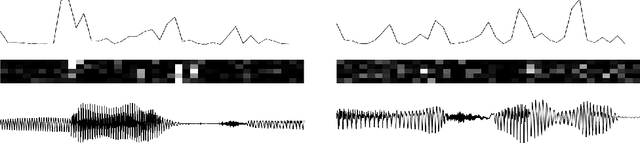
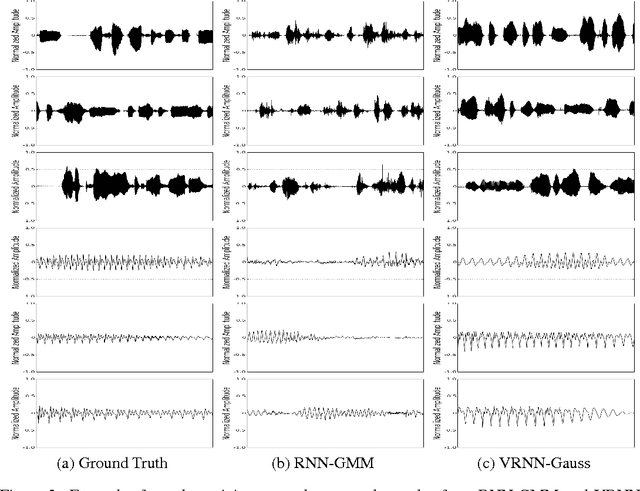
In this paper, we explore the inclusion of latent random variables into the dynamic hidden state of a recurrent neural network (RNN) by combining elements of the variational autoencoder. We argue that through the use of high-level latent random variables, the variational RNN (VRNN)1 can model the kind of variability observed in highly structured sequential data such as natural speech. We empirically evaluate the proposed model against related sequential models on four speech datasets and one handwriting dataset. Our results show the important roles that latent random variables can play in the RNN dynamic hidden state.
Detecting Interrogative Utterances with Recurrent Neural Networks
Nov 16, 2015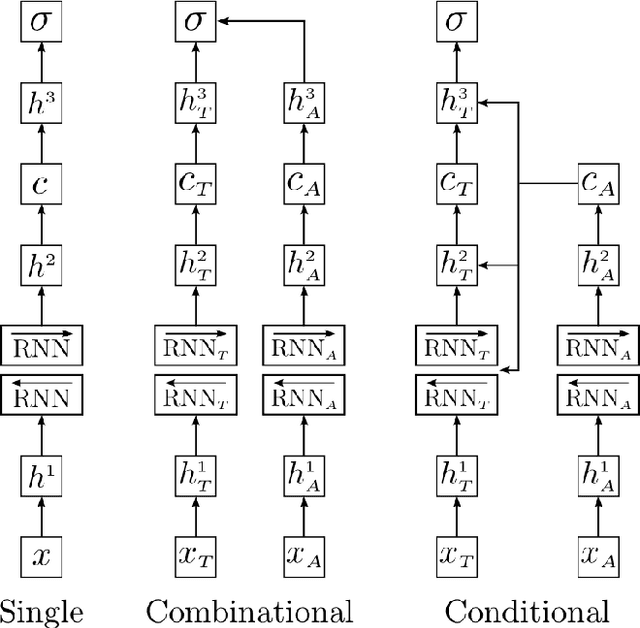
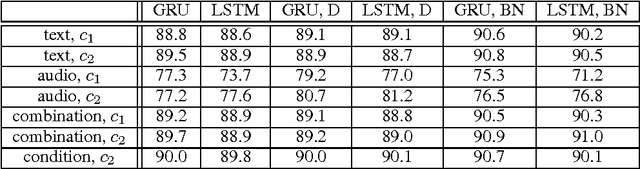
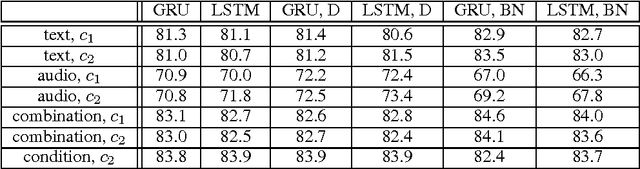

In this paper, we explore different neural network architectures that can predict if a speaker of a given utterance is asking a question or making a statement. We com- pare the outcomes of regularization methods that are popularly used to train deep neural networks and study how different context functions can affect the classification performance. We also compare the efficacy of gated activation functions that are favorably used in recurrent neural networks and study how to combine multimodal inputs. We evaluate our models on two multimodal datasets: MSR-Skype and CALLHOME.
Gated Feedback Recurrent Neural Networks
Jun 17, 2015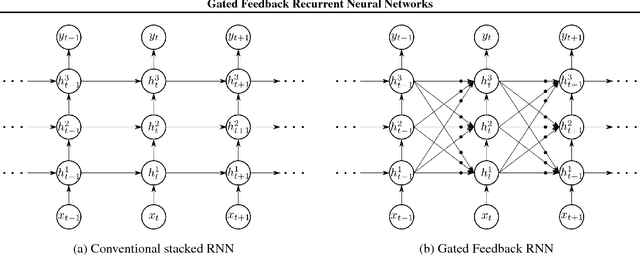

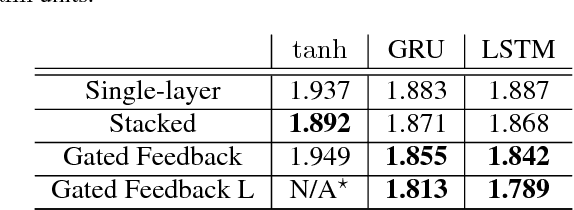

In this work, we propose a novel recurrent neural network (RNN) architecture. The proposed RNN, gated-feedback RNN (GF-RNN), extends the existing approach of stacking multiple recurrent layers by allowing and controlling signals flowing from upper recurrent layers to lower layers using a global gating unit for each pair of layers. The recurrent signals exchanged between layers are gated adaptively based on the previous hidden states and the current input. We evaluated the proposed GF-RNN with different types of recurrent units, such as tanh, long short-term memory and gated recurrent units, on the tasks of character-level language modeling and Python program evaluation. Our empirical evaluation of different RNN units, revealed that in both tasks, the GF-RNN outperforms the conventional approaches to build deep stacked RNNs. We suggest that the improvement arises because the GF-RNN can adaptively assign different layers to different timescales and layer-to-layer interactions (including the top-down ones which are not usually present in a stacked RNN) by learning to gate these interactions.
Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling
Dec 11, 2014

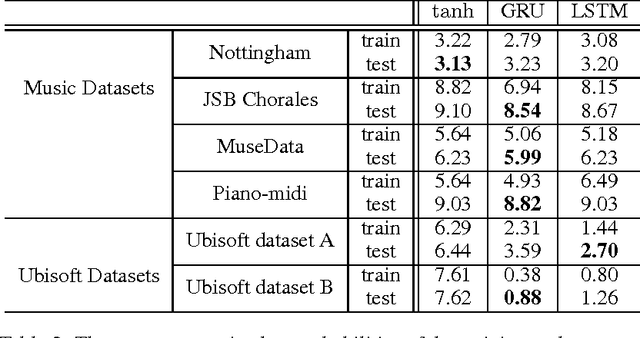
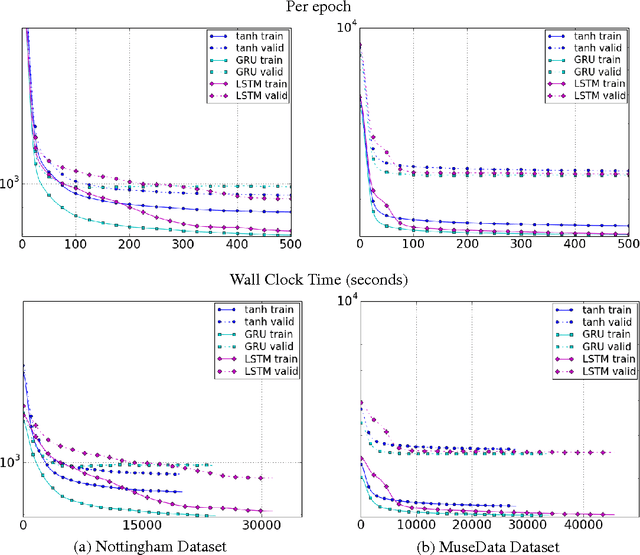
In this paper we compare different types of recurrent units in recurrent neural networks (RNNs). Especially, we focus on more sophisticated units that implement a gating mechanism, such as a long short-term memory (LSTM) unit and a recently proposed gated recurrent unit (GRU). We evaluate these recurrent units on the tasks of polyphonic music modeling and speech signal modeling. Our experiments revealed that these advanced recurrent units are indeed better than more traditional recurrent units such as tanh units. Also, we found GRU to be comparable to LSTM.
Deep Attribute Networks
Nov 28, 2012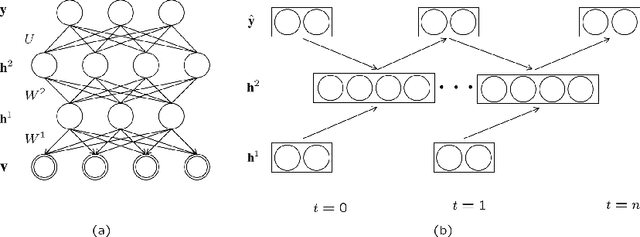
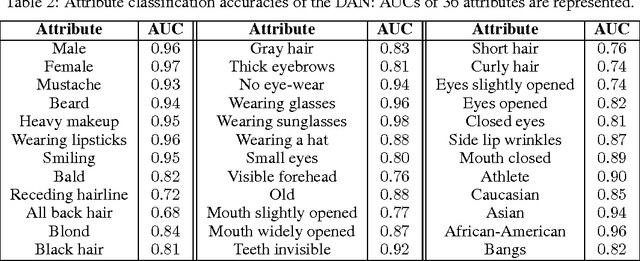
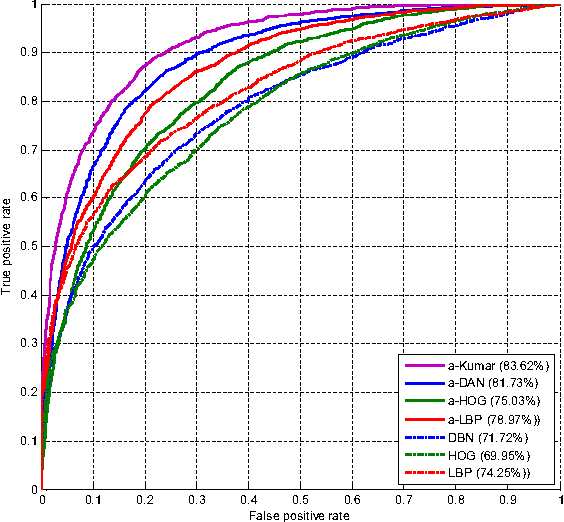
Obtaining compact and discriminative features is one of the major challenges in many of the real-world image classification tasks such as face verification and object recognition. One possible approach is to represent input image on the basis of high-level features that carry semantic meaning which humans can understand. In this paper, a model coined deep attribute network (DAN) is proposed to address this issue. For an input image, the model outputs the attributes of the input image without performing any classification. The efficacy of the proposed model is evaluated on unconstrained face verification and real-world object recognition tasks using the LFW and the a-PASCAL datasets. We demonstrate the potential of deep learning for attribute-based classification by showing comparable results with existing state-of-the-art results. Once properly trained, the DAN is fast and does away with calculating low-level features which are maybe unreliable and computationally expensive.