 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStep-unrolled Denoising Autoencoders for Text Generation
Dec 13, 2021



In this paper we propose a new generative model of text, Step-unrolled Denoising Autoencoder (SUNDAE), that does not rely on autoregressive models. Similarly to denoising diffusion techniques, SUNDAE is repeatedly applied on a sequence of tokens, starting from random inputs and improving them each time until convergence. We present a simple new improvement operator that converges in fewer iterations than diffusion methods, while qualitatively producing better samples on natural language datasets. SUNDAE achieves state-of-the-art results (among non-autoregressive methods) on the WMT'14 English-to-German translation task and good qualitative results on unconditional language modeling on the Colossal Cleaned Common Crawl dataset and a dataset of Python code from GitHub. The non-autoregressive nature of SUNDAE opens up possibilities beyond left-to-right prompted generation, by filling in arbitrary blank patterns in a template.
Towards Learning Universal Audio Representations
Dec 01, 2021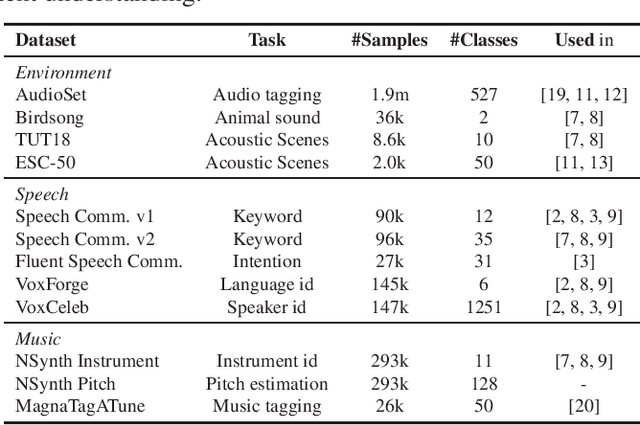
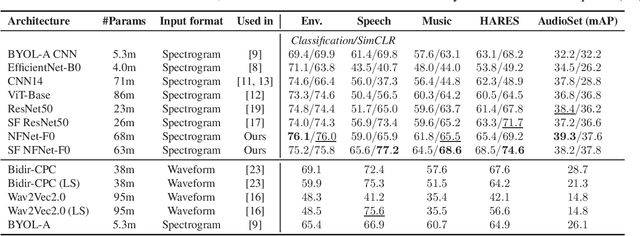
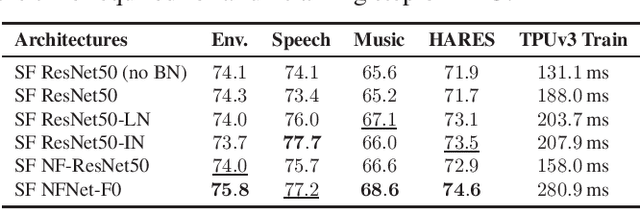
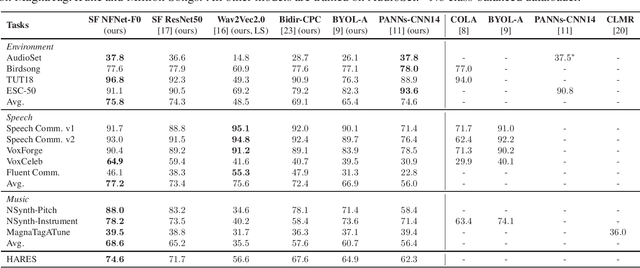
The ability to learn universal audio representations that can solve diverse speech, music, and environment tasks can spur many applications that require general sound content understanding. In this work, we introduce a holistic audio representation evaluation suite (HARES) spanning 12 downstream tasks across audio domains and provide a thorough empirical study of recent sound representation learning systems on that benchmark. We discover that previous sound event classification or speech models do not generalize outside of their domains. We observe that more robust audio representations can be learned with the SimCLR objective; however, the model's transferability depends heavily on the model architecture. We find the Slowfast architecture is good at learning rich representations required by different domains, but its performance is affected by the normalization scheme. Based on these findings, we propose a novel normalizer-free Slowfast NFNet and achieve state-of-the-art performance across all domains.
Divide and Contrast: Self-supervised Learning from Uncurated Data
May 17, 2021



Self-supervised learning holds promise in leveraging large amounts of unlabeled data, however much of its progress has thus far been limited to highly curated pre-training data such as ImageNet. We explore the effects of contrastive learning from larger, less-curated image datasets such as YFCC, and find there is indeed a large difference in the resulting representation quality. We hypothesize that this curation gap is due to a shift in the distribution of image classes -- which is more diverse and heavy-tailed -- resulting in less relevant negative samples to learn from. We test this hypothesis with a new approach, Divide and Contrast (DnC), which alternates between contrastive learning and clustering-based hard negative mining. When pretrained on less curated datasets, DnC greatly improves the performance of self-supervised learning on downstream tasks, while remaining competitive with the current state-of-the-art on curated datasets.
Multimodal Self-Supervised Learning of General Audio Representations
Apr 28, 2021



We present a multimodal framework to learn general audio representations from videos. Existing contrastive audio representation learning methods mainly focus on using the audio modality alone during training. In this work, we show that additional information contained in video can be utilized to greatly improve the learned features. First, we demonstrate that our contrastive framework does not require high resolution images to learn good audio features. This allows us to scale up the training batch size, while keeping the computational load incurred by the additional video modality to a reasonable level. Second, we use augmentations that mix together different samples. We show that this is effective to make the proxy task harder, which leads to substantial performance improvements when increasing the batch size. As a result, our audio model achieves a state-of-the-art of 42.4 mAP on the AudioSet classification downstream task, closing the gap between supervised and self-supervised methods trained on the same dataset. Moreover, we show that our method is advantageous on a broad range of non-semantic audio tasks, including speaker identification, keyword spotting, language identification, and music instrument classification.
Multi-Format Contrastive Learning of Audio Representations
Mar 24, 2021



Recent advances suggest the advantage of multi-modal training in comparison with single-modal methods. In contrast to this view, in our work we find that similar gain can be obtained from training with different formats of a single modality. In particular, we investigate the use of the contrastive learning framework to learn audio representations by maximizing the agreement between the raw audio and its spectral representation. We find a significant gain using this multi-format strategy against the single-format counterparts. Moreover, on the downstream AudioSet and ESC-50 classification task, our audio-only approach achieves new state-of-the-art results with a mean average precision of 0.376 and an accuracy of 90.5%, respectively.
Efficient Visual Pretraining with Contrastive Detection
Mar 19, 2021

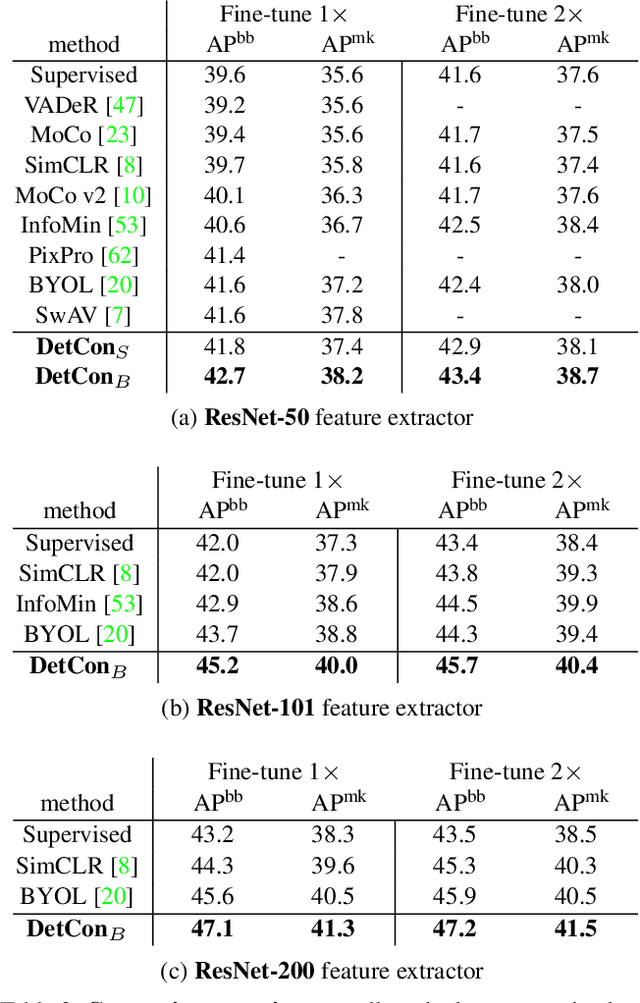

Self-supervised pretraining has been shown to yield powerful representations for transfer learning. These performance gains come at a large computational cost however, with state-of-the-art methods requiring an order of magnitude more computation than supervised pretraining. We tackle this computational bottleneck by introducing a new self-supervised objective, contrastive detection, which tasks representations with identifying object-level features across augmentations. This objective extracts a rich learning signal per image, leading to state-of-the-art transfer performance from ImageNet to COCO, while requiring up to 5x less pretraining. In particular, our strongest ImageNet-pretrained model performs on par with SEER, one of the largest self-supervised systems to date, which uses 1000x more pretraining data. Finally, our objective seamlessly handles pretraining on more complex images such as those in COCO, closing the gap with supervised transfer learning from COCO to PASCAL.
Learning Robust and Multilingual Speech Representations
Jan 29, 2020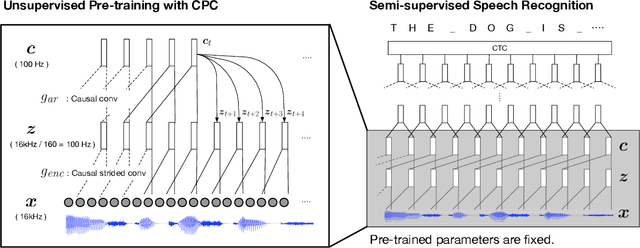
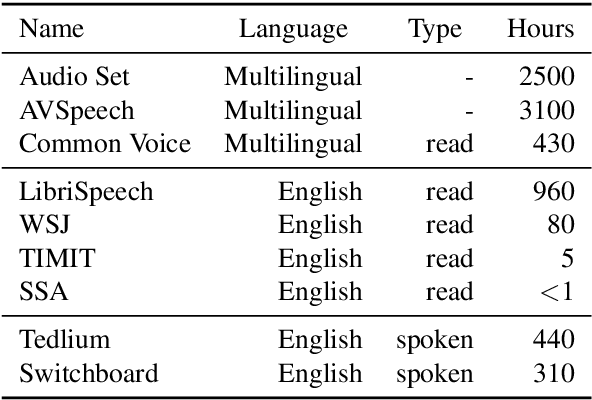

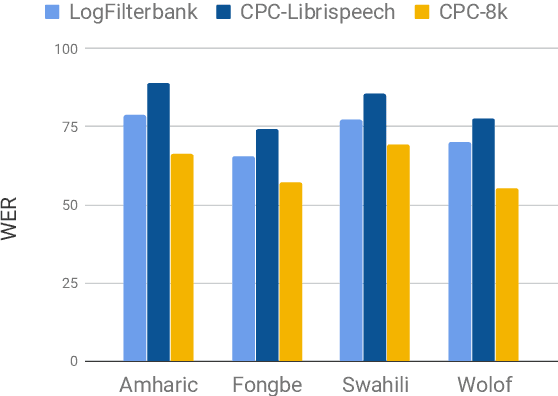
Unsupervised speech representation learning has shown remarkable success at finding representations that correlate with phonetic structures and improve downstream speech recognition performance. However, most research has been focused on evaluating the representations in terms of their ability to improve the performance of speech recognition systems on read English (e.g. Wall Street Journal and LibriSpeech). This evaluation methodology overlooks two important desiderata that speech representations should have: robustness to domain shifts and transferability to other languages. In this paper we learn representations from up to 8000 hours of diverse and noisy speech data and evaluate the representations by looking at their robustness to domain shifts and their ability to improve recognition performance in many languages. We find that our representations confer significant robustness advantages to the resulting recognition systems: we see significant improvements in out-of-domain transfer relative to baseline feature sets and the features likewise provide improvements in 25 phonetically diverse languages including tonal languages and low-resource languages.
Shaping Belief States with Generative Environment Models for RL
Jun 24, 2019


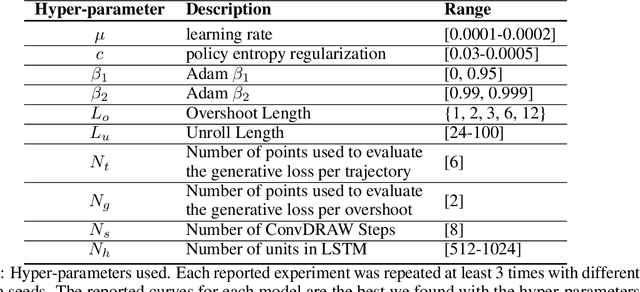
When agents interact with a complex environment, they must form and maintain beliefs about the relevant aspects of that environment. We propose a way to efficiently train expressive generative models in complex environments. We show that a predictive algorithm with an expressive generative model can form stable belief-states in visually rich and dynamic 3D environments. More precisely, we show that the learned representation captures the layout of the environment as well as the position and orientation of the agent. Our experiments show that the model substantially improves data-efficiency on a number of reinforcement learning (RL) tasks compared with strong model-free baseline agents. We find that predicting multiple steps into the future (overshooting), in combination with an expressive generative model, is critical for stable representations to emerge. In practice, using expressive generative models in RL is computationally expensive and we propose a scheme to reduce this computational burden, allowing us to build agents that are competitive with model-free baselines.
Generating Diverse High-Fidelity Images with VQ-VAE-2
Jun 02, 2019



We explore the use of Vector Quantized Variational AutoEncoder (VQ-VAE) models for large scale image generation. To this end, we scale and enhance the autoregressive priors used in VQ-VAE to generate synthetic samples of much higher coherence and fidelity than possible before. We use simple feed-forward encoder and decoder networks, making our model an attractive candidate for applications where the encoding and/or decoding speed is critical. Additionally, VQ-VAE requires sampling an autoregressive model only in the compressed latent space, which is an order of magnitude faster than sampling in the pixel space, especially for large images. We demonstrate that a multi-scale hierarchical organization of VQ-VAE, augmented with powerful priors over the latent codes, is able to generate samples with quality that rivals that of state of the art Generative Adversarial Networks on multifaceted datasets such as ImageNet, while not suffering from GAN's known shortcomings such as mode collapse and lack of diversity.
Data-Efficient Image Recognition with Contrastive Predictive Coding
May 22, 2019



Large scale deep learning excels when labeled images are abundant, yet data-efficient learning remains a longstanding challenge. While biological vision is thought to leverage vast amounts of unlabeled data to solve classification problems with limited supervision, computer vision has so far not succeeded in this `semi-supervised' regime. Our work tackles this challenge with Contrastive Predictive Coding, an unsupervised objective which extracts stable structure from still images. The result is a representation which, equipped with a simple linear classifier, separates ImageNet categories better than all competing methods, and surpasses the performance of a fully-supervised AlexNet model. When given a small number of labeled images (as few as 13 per class), this representation retains a strong classification performance, outperforming state-of-the-art semi-supervised methods by 10% Top-5 accuracy and supervised methods by 20%. Finally, we find our unsupervised representation to serve as a useful substrate for image detection on the PASCAL-VOC 2007 dataset, approaching the performance of representations trained with a fully annotated ImageNet dataset. We expect these results to open the door to pipelines that use scalable unsupervised representations as a drop-in replacement for supervised ones for real-world vision tasks where labels are scarce.