 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Learning Universal Hyperparameter Optimizers with Transformers
May 26, 2022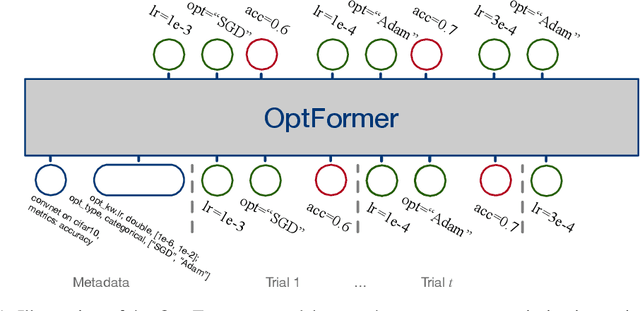


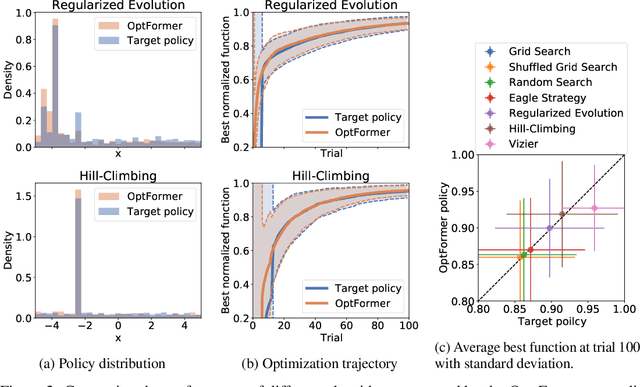
Meta-learning hyperparameter optimization (HPO) algorithms from prior experiments is a promising approach to improve optimization efficiency over objective functions from a similar distribution. However, existing methods are restricted to learning from experiments sharing the same set of hyperparameters. In this paper, we introduce the OptFormer, the first text-based Transformer HPO framework that provides a universal end-to-end interface for jointly learning policy and function prediction when trained on vast tuning data from the wild. Our extensive experiments demonstrate that the OptFormer can imitate at least 7 different HPO algorithms, which can be further improved via its function uncertainty estimates. Compared to a Gaussian Process, the OptFormer also learns a robust prior distribution for hyperparameter response functions, and can thereby provide more accurate and better calibrated predictions. This work paves the path to future extensions for training a Transformer-based model as a general HPO optimizer.
Learning Robust and Multilingual Speech Representations
Jan 29, 2020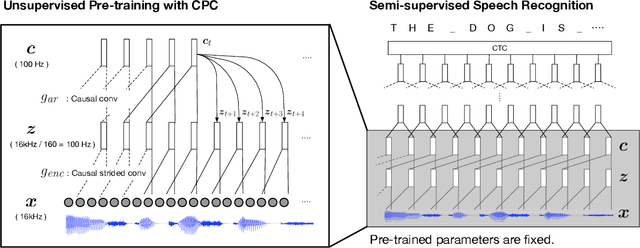
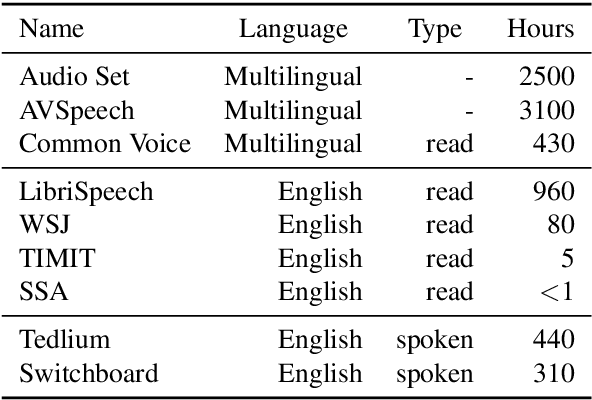

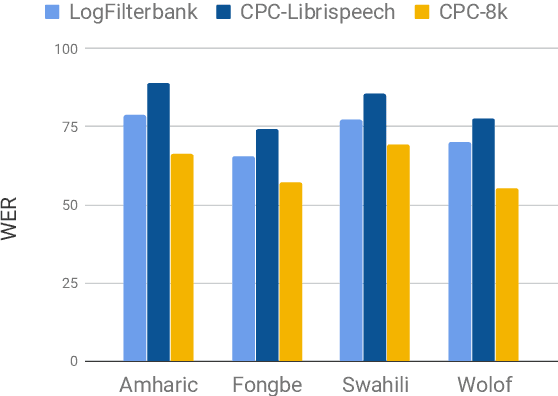
Unsupervised speech representation learning has shown remarkable success at finding representations that correlate with phonetic structures and improve downstream speech recognition performance. However, most research has been focused on evaluating the representations in terms of their ability to improve the performance of speech recognition systems on read English (e.g. Wall Street Journal and LibriSpeech). This evaluation methodology overlooks two important desiderata that speech representations should have: robustness to domain shifts and transferability to other languages. In this paper we learn representations from up to 8000 hours of diverse and noisy speech data and evaluate the representations by looking at their robustness to domain shifts and their ability to improve recognition performance in many languages. We find that our representations confer significant robustness advantages to the resulting recognition systems: we see significant improvements in out-of-domain transfer relative to baseline feature sets and the features likewise provide improvements in 25 phonetically diverse languages including tonal languages and low-resource languages.
Unsupervised Word Discovery with Segmental Neural Language Models
Nov 23, 2018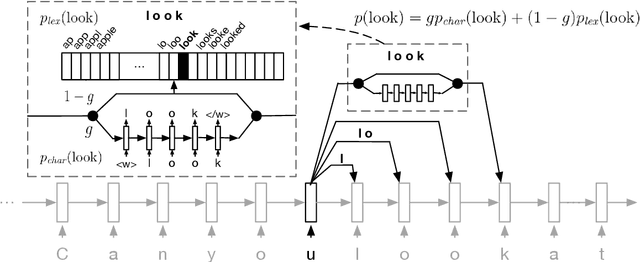
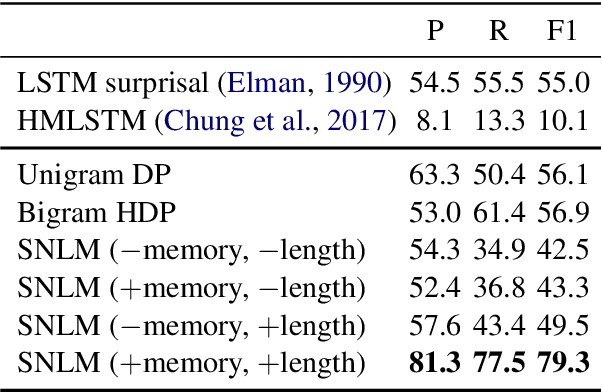
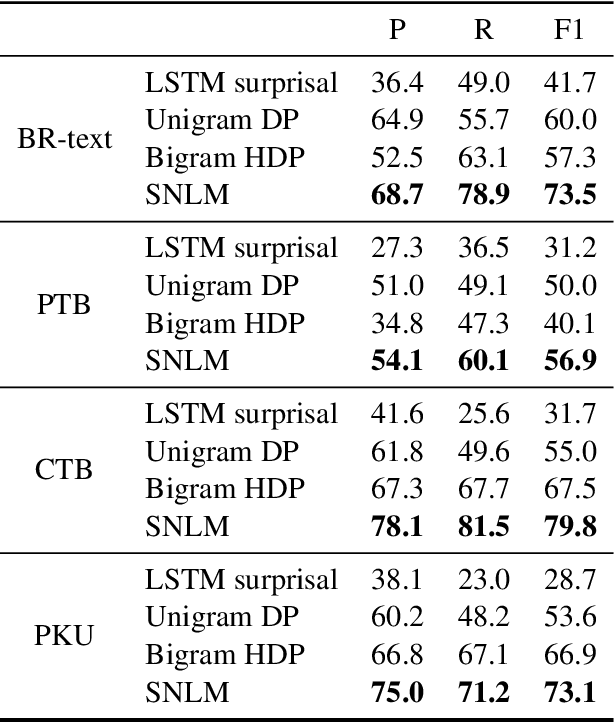
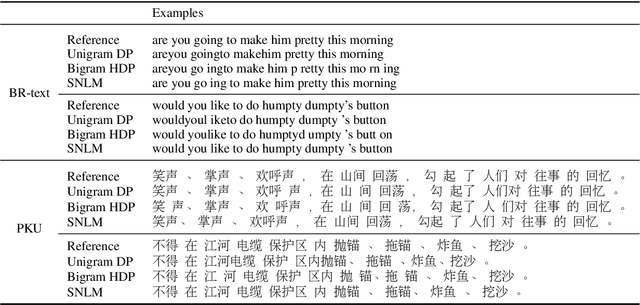
We propose a segmental neural language model that combines the representational power of neural networks and the structure learning mechanism of Bayesian nonparametrics, and show that it learns to discover semantically meaningful units (e.g., morphemes and words) from unsegmented character sequences. The model generates text as a sequence of segments, where each segment is generated either character-by-character from a sequence model or as a single draw from a lexical memory that stores multi-character units. Its parameters are fit to maximize the marginal likelihood of the training data, summing over all segmentations of the input, and its hyperparameters are likewise set to optimize held-out marginal likelihood. To prevent the model from overusing the lexical memory, which leads to poor generalization and bad segmentation, we introduce a differentiable regularizer that penalizes based on the expected length of each segment. To our knowledge, this is the first demonstration of neural networks that have predictive distributions better than LSTM language models and also infer a segmentation into word-like units that are competitive with the best existing word discovery models.
Learning to Create and Reuse Words in Open-Vocabulary Neural Language Modeling
Apr 23, 2017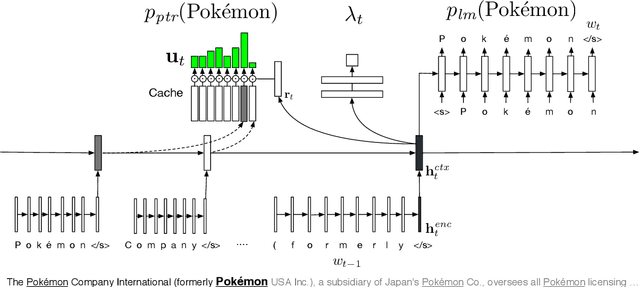
Fixed-vocabulary language models fail to account for one of the most characteristic statistical facts of natural language: the frequent creation and reuse of new word types. Although character-level language models offer a partial solution in that they can create word types not attested in the training corpus, they do not capture the "bursty" distribution of such words. In this paper, we augment a hierarchical LSTM language model that generates sequences of word tokens character by character with a caching mechanism that learns to reuse previously generated words. To validate our model we construct a new open-vocabulary language modeling corpus (the Multilingual Wikipedia Corpus, MWC) from comparable Wikipedia articles in 7 typologically diverse languages and demonstrate the effectiveness of our model across this range of languages.
Neural Architectures for Named Entity Recognition
Apr 07, 2016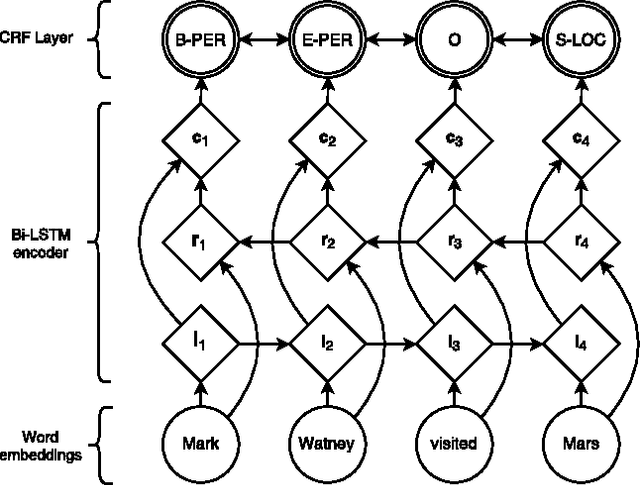
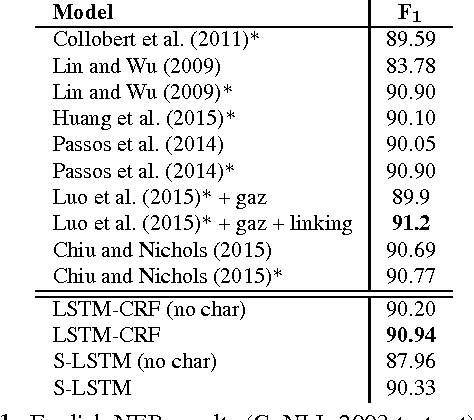

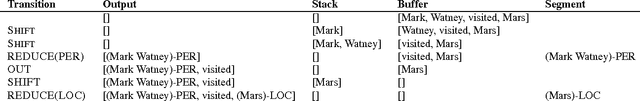
State-of-the-art named entity recognition systems rely heavily on hand-crafted features and domain-specific knowledge in order to learn effectively from the small, supervised training corpora that are available. In this paper, we introduce two new neural architectures---one based on bidirectional LSTMs and conditional random fields, and the other that constructs and labels segments using a transition-based approach inspired by shift-reduce parsers. Our models rely on two sources of information about words: character-based word representations learned from the supervised corpus and unsupervised word representations learned from unannotated corpora. Our models obtain state-of-the-art performance in NER in four languages without resorting to any language-specific knowledge or resources such as gazetteers.
Learning to Represent Words in Context with Multilingual Supervision
Nov 19, 2015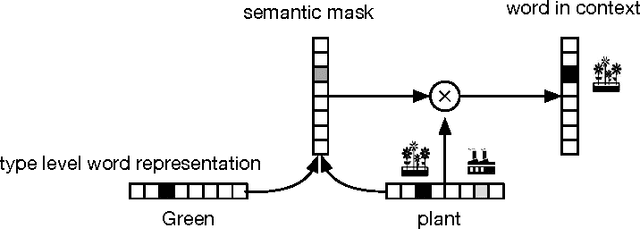
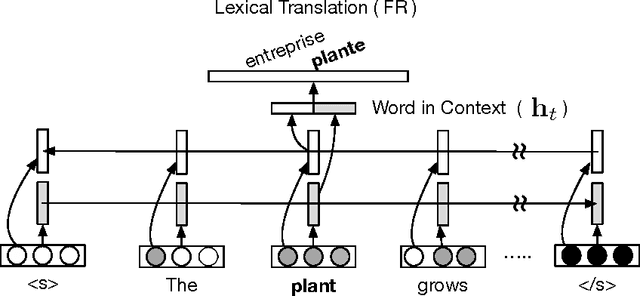
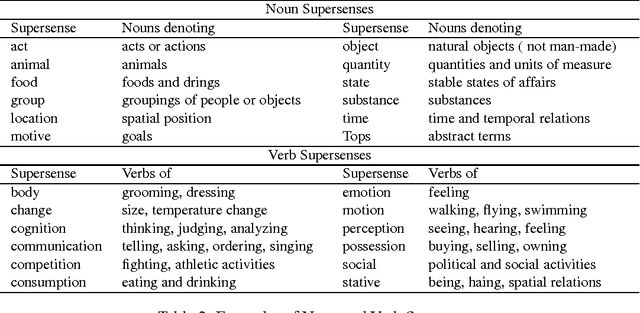
We present a neural network architecture based on bidirectional LSTMs to compute representations of words in the sentential contexts. These context-sensitive word representations are suitable for, e.g., distinguishing different word senses and other context-modulated variations in meaning. To learn the parameters of our model, we use cross-lingual supervision, hypothesizing that a good representation of a word in context will be one that is sufficient for selecting the correct translation into a second language. We evaluate the quality of our representations as features in three downstream tasks: prediction of semantic supersenses (which assign nouns and verbs into a few dozen semantic classes), low resource machine translation, and a lexical substitution task, and obtain state-of-the-art results on all of these.