 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Fine-tuning with Rewarded Moment Matching Distillation
Jun 29, 2026Distillation and Reinforcement Learning (RL) fine-tuning are the primary pillars of diffusion post-training. While traditionally studied in isolation, the interaction between these phases remains poorly understood, and in particular how fine-tuning impacts the generative quality of distilled models. We introduce Rewarded Moment Matching Distillation (RMMD), a novel framework that simultaneously distills diffusion models and maximizes a reward function. RMMD preserves the high-fidelity ``naturalness'' characteristic of advanced distillation (such as 8-step Moment Matching) by adapting the sampling loop for on-policy training and repurposing the distillation loss as a proxy for integral KL regularization. By evaluating the FID-Reward Pareto fronts on ImageNet, we demonstrate that RMMD achieves superior trade-offs compared to single-step baselines (DI++) and multi-step competitors (DRaFT, HyperNoise). Finally, we apply RMMD to GenCast, a state-of-the-art weather forecasting model, to distill it while optimizing the Continuous Ranked Probability Score (CRPS) metric. The resulting distilled model achieves a 7.5x speedup while outperforming the teacher model on 93% of target weather variables, and being better calibrated. This proves that RMMD scales to complex, high-dimensional scientific domains.
Accelerating Speculative Diffusions via Block Verification
Jun 11, 2026Speculative decoding speeds up LLM inference by using a draft model to generate tokens, with an acceptance-rejection scheme that ensures that the output matches the target distribution. Adapting this to continuous diffusions is difficult because speculative sampling requires drawing from a residual distribution. While straightforward in discrete spaces, efficiently sampling this residual in continuous space is non-trivial. Consequently, existing diffusion adaptations either use computationally inefficient sampling techniques or rely on an alternative scheme. In this work, we introduce a novel scheme that efficiently implements the original speculative sampling mechanism for diffusion models. Our approach offers a critical advantage over current methods: it enables us to adapt block verification from LLMs to diffusions -- which provably improves the acceptance rate of drafts. Furthermore, we formalize and analyze the Free Drafter, a heuristic self-speculative drafter for diffusions that requires no training. By enabling block verification, our Free Drafter yields up to a 6.3% speedup over existing speculative methods with no additional training and negligible overhead beyond the existing parallel verification pass.
SURF: Separation via Unsupervised Remixing Flow
Jun 03, 2026The goal of single-channel source separation is to reconstruct $K$ sources given their mixture. In supervised settings where vast amounts of clean source data are available, this challenging, ill-posed problem has been addressed successfully by generative diffusion and flow-based prior models. However, access to such clean source samples is often limited, and even when available, supervised models are vulnerable to domain shifts. To bridge this gap, we present Separation via Unsupervised Remixing Flow (SURF), an unsupervised flow matching approach for source separation that learns directly from observed mixtures. This method relies on a novel combination of state-of-the-art supervised flow matching and regression-based self-supervised techniques. At a high level, starting from a teacher model, we utilize a "remixing" step to bootstrap the learning of a student flow model from the teacher's estimates. We provide insights into the objectives optimized by this approach and draw a novel connection to the Wake-Sleep algorithm. Empirical evaluations on image and audio benchmarks demonstrate that SURF establishes a new state-of-the-art, significantly outperforming existing unsupervised methods. See our demo page for examples. https://google.github.io/df-conformer/surf/
Metropolis-Adjusted Diffusion Models
May 10, 2026Sampling from score-based diffusion models incurs bias due to both time discretisation and the approximation of the score function. A common strategy for reducing this bias is to apply corrector steps based on the unadjusted Langevin algorithm (ULA) at each noise level within a predictor-corrector framework. However, ULA is itself a biased sampler, as it discretises a continuous diffusion process. In this work, we consider adjusted Langevin correctors that employ Metropolis--Hastings (MH) or Barker's accept-reject steps to correct for this bias. Since the target density ratio typically required by MH-based algorithms is unavailable, we propose methods that instead utilise the score function to compute the correct acceptance probability. We introduce the first exact method for adjusting Langevin corrections in diffusion models, based on a two-coin Bernoulli factory algorithm. We also propose an efficient approximation based on Simpson's rule that achieves accuracy of order $5/2$ in the step size at near-zero marginal cost. We demonstrate that these procedures improve sample quality on both synthetic and image datasets, yielding consistent gains in Fréchet Inception Distance (FID) on the latter.
On the Wasserstein Gradient Flow Interpretation of Drifting Models
May 06, 2026Recently, Deng et al. (2026) proposed Generative Modeling via Drifting (GMD), a novel framework for generative tasks. This note presents an analysis of GMD through the lens of Wasserstein Gradient Flows (WGF), i.e., the path of steepest descent for a functional in the space of probability measures, equipped with the geometry of optimal transport. Unlike previous WGF-based contributions, GMD can be thought of as directly targeting a fixed point of a specific WGF flow. We demonstrate three main results: first, that one algorithm proposed by Deng et al. (2026) corresponds to finding the limiting point of a WGF on the KL divergence, with Parzen smoothing on the densities. Second, that the algorithm actually implemented by Deng et al. (2026) corresponds to a different procedure, which bears some resemblance to the fixed point of a WGF on the Sinkhorn divergence, but lacks certain desirable properties of the latter. Third, the same same idea can be extended to the limiting point of other WGFs, including the Maximum Mean Discrepancy (MMD), the sliced Wasserstein distance, and GAN critic functions.
Control Variate Score Matching for Diffusion Models
Dec 23, 2025Diffusion models offer a robust framework for sampling from unnormalized probability densities, which requires accurately estimating the score of the noise-perturbed target distribution. While the standard Denoising Score Identity (DSI) relies on data samples, access to the target energy function enables an alternative formulation via the Target Score Identity (TSI). However, these estimators face a fundamental variance trade-off: DSI exhibits high variance in low-noise regimes, whereas TSI suffers from high variance at high noise levels. In this work, we reconcile these approaches by unifying both estimators within the principled framework of control variates. We introduce the Control Variate Score Identity (CVSI), deriving an optimal, time-dependent control coefficient that theoretically guarantees variance minimization across the entire noise spectrum. We demonstrate that CVSI serves as a robust, low-variance plug-in estimator that significantly enhances sample efficiency in both data-free sampler learning and inference-time diffusion sampling.
Learn to Guide Your Diffusion Model
Oct 01, 2025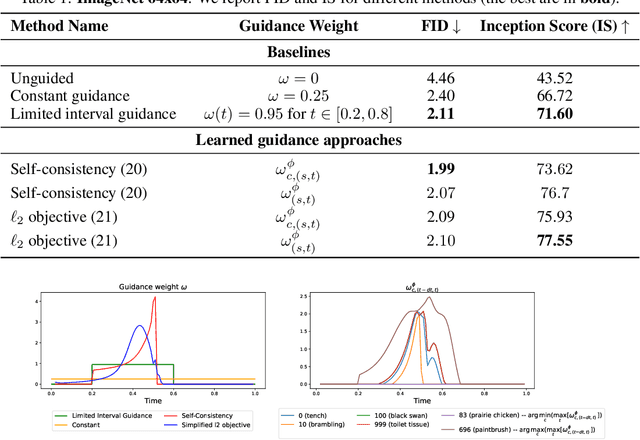
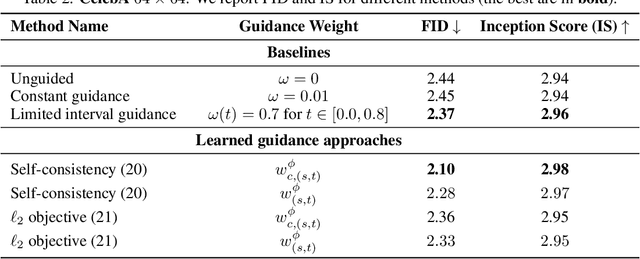
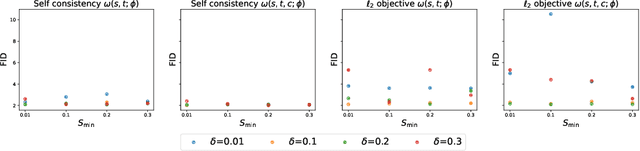

Classifier-free guidance (CFG) is a widely used technique for improving the perceptual quality of samples from conditional diffusion models. It operates by linearly combining conditional and unconditional score estimates using a guidance weight $\omega$. While a large, static weight can markedly improve visual results, this often comes at the cost of poorer distributional alignment. In order to better approximate the target conditional distribution, we instead learn guidance weights $\omega_{c,(s,t)}$, which are continuous functions of the conditioning $c$, the time $t$ from which we denoise, and the time $s$ towards which we denoise. We achieve this by minimizing the distributional mismatch between noised samples from the true conditional distribution and samples from the guided diffusion process. We extend our framework to reward guided sampling, enabling the model to target distributions tilted by a reward function $R(x_0,c)$, defined on clean data and a conditioning $c$. We demonstrate the effectiveness of our methodology on low-dimensional toy examples and high-dimensional image settings, where we observe improvements in Fr\'echet inception distance (FID) for image generation. In text-to-image applications, we observe that employing a reward function given by the CLIP score leads to guidance weights that improve image-prompt alignment.
Source Separation by Flow Matching
May 22, 2025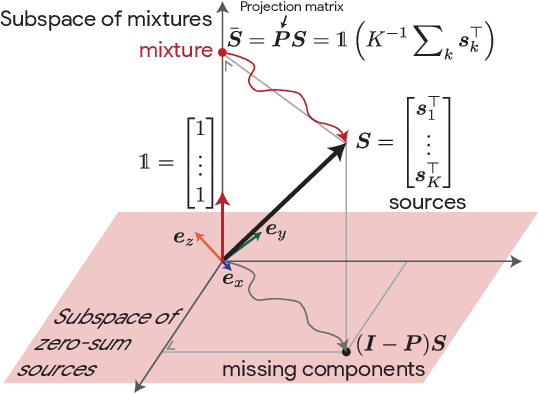
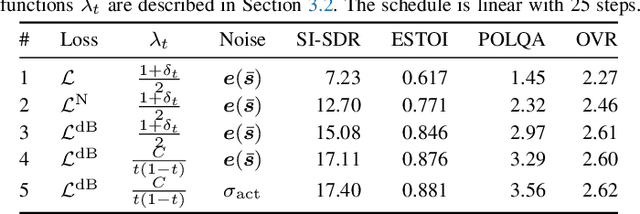
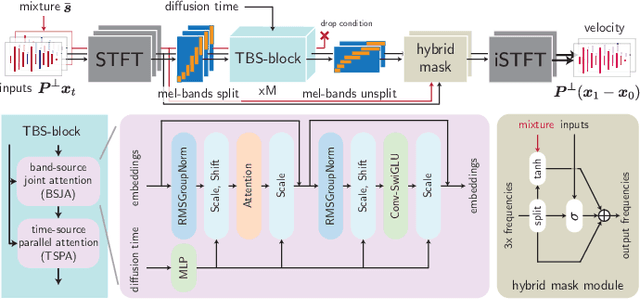
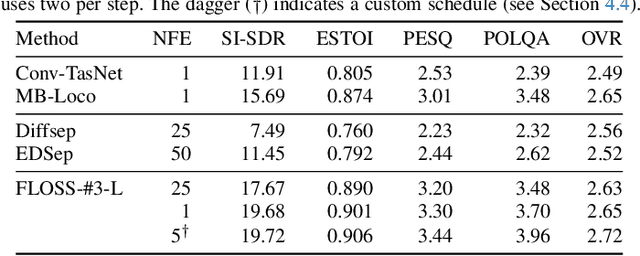
We consider the problem of single-channel audio source separation with the goal of reconstructing $K$ sources from their mixture. We address this ill-posed problem with FLOSS (FLOw matching for Source Separation), a constrained generation method based on flow matching, ensuring strict mixture consistency. Flow matching is a general methodology that, when given samples from two probability distributions defined on the same space, learns an ordinary differential equation to output a sample from one of the distributions when provided with a sample from the other. In our context, we have access to samples from the joint distribution of $K$ sources and so the corresponding samples from the lower-dimensional distribution of their mixture. To apply flow matching, we augment these mixture samples with artificial noise components to ensure the resulting "augmented" distribution matches the dimensionality of the $K$ source distribution. Additionally, as any permutation of the sources yields the same mixture, we adopt an equivariant formulation of flow matching which relies on a suitable custom-designed neural network architecture. We demonstrate the performance of the method for the separation of overlapping speech.
Feynman-Kac Correctors in Diffusion: Annealing, Guidance, and Product of Experts
Mar 04, 2025While score-based generative models are the model of choice across diverse domains, there are limited tools available for controlling inference-time behavior in a principled manner, e.g. for composing multiple pretrained models. Existing classifier-free guidance methods use a simple heuristic to mix conditional and unconditional scores to approximately sample from conditional distributions. However, such methods do not approximate the intermediate distributions, necessitating additional 'corrector' steps. In this work, we provide an efficient and principled method for sampling from a sequence of annealed, geometric-averaged, or product distributions derived from pretrained score-based models. We derive a weighted simulation scheme which we call Feynman-Kac Correctors (FKCs) based on the celebrated Feynman-Kac formula by carefully accounting for terms in the appropriate partial differential equations (PDEs). To simulate these PDEs, we propose Sequential Monte Carlo (SMC) resampling algorithms that leverage inference-time scaling to improve sampling quality. We empirically demonstrate the utility of our methods by proposing amortized sampling via inference-time temperature annealing, improving multi-objective molecule generation using pretrained models, and improving classifier-free guidance for text-to-image generation. Our code is available at https://github.com/martaskrt/fkc-diffusion.
Distributional Diffusion Models with Scoring Rules
Feb 04, 2025Diffusion models generate high-quality synthetic data. They operate by defining a continuous-time forward process which gradually adds Gaussian noise to data until fully corrupted. The corresponding reverse process progressively "denoises" a Gaussian sample into a sample from the data distribution. However, generating high-quality outputs requires many discretization steps to obtain a faithful approximation of the reverse process. This is expensive and has motivated the development of many acceleration methods. We propose to accomplish sample generation by learning the posterior {\em distribution} of clean data samples given their noisy versions, instead of only the mean of this distribution. This allows us to sample from the probability transitions of the reverse process on a coarse time scale, significantly accelerating inference with minimal degradation of the quality of the output. This is accomplished by replacing the standard regression loss used to estimate conditional means with a scoring rule. We validate our method on image and robot trajectory generation, where we consistently outperform standard diffusion models at few discretization steps.