 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectroStream: A Versatile Neural Codec for General Audio
Aug 07, 2025We propose SpectroStream, a full-band multi-channel neural audio codec. Successor to the well-established SoundStream, SpectroStream extends its capability beyond 24 kHz monophonic audio and enables high-quality reconstruction of 48 kHz stereo music at bit rates of 4--16 kbps. This is accomplished with a new neural architecture that leverages audio representation in the time-frequency domain, which leads to better audio quality especially at higher sample rate. The model also uses a delayed-fusion strategy to handle multi-channel audio, which is crucial in balancing per-channel acoustic quality and cross-channel phase consistency.
Live Music Models
Aug 06, 2025We introduce a new class of generative models for music called live music models that produce a continuous stream of music in real-time with synchronized user control. We release Magenta RealTime, an open-weights live music model that can be steered using text or audio prompts to control acoustic style. On automatic metrics of music quality, Magenta RealTime outperforms other open-weights music generation models, despite using fewer parameters and offering first-of-its-kind live generation capabilities. We also release Lyria RealTime, an API-based model with extended controls, offering access to our most powerful model with wide prompt coverage. These models demonstrate a new paradigm for AI-assisted music creation that emphasizes human-in-the-loop interaction for live music performance.
Simplified and Generalized Masked Diffusion for Discrete Data
Jun 06, 2024Masked (or absorbing) diffusion is actively explored as an alternative to autoregressive models for generative modeling of discrete data. However, existing work in this area has been hindered by unnecessarily complex model formulations and unclear relationships between different perspectives, leading to suboptimal parameterization, training objectives, and ad hoc adjustments to counteract these issues. In this work, we aim to provide a simple and general framework that unlocks the full potential of masked diffusion models. We show that the continuous-time variational objective of masked diffusion models is a simple weighted integral of cross-entropy losses. Our framework also enables training generalized masked diffusion models with state-dependent masking schedules. When evaluated by perplexity, our models trained on OpenWebText surpass prior diffusion language models at GPT-2 scale and demonstrate superior performance on 4 out of 5 zero-shot language modeling tasks. Furthermore, our models vastly outperform previous discrete diffusion models on pixel-level image modeling, achieving 2.78~(CIFAR-10) and 3.42 (ImageNet 64$\times$64) bits per dimension that are comparable or better than autoregressive models of similar sizes.
Transfer Learning for Text Diffusion Models
Jan 30, 2024In this report, we explore the potential for text diffusion to replace autoregressive (AR) decoding for the training and deployment of large language models (LLMs). We are particularly interested to see whether pretrained AR models can be transformed into text diffusion models through a lightweight adaptation procedure we call ``AR2Diff''. We begin by establishing a strong baseline setup for training text diffusion models. Comparing across multiple architectures and pretraining objectives, we find that training a decoder-only model with a prefix LM objective is best or near-best across several tasks. Building on this finding, we test various transfer learning setups for text diffusion models. On machine translation, we find that text diffusion underperforms the standard AR approach. However, on code synthesis and extractive QA, we find diffusion models trained from scratch outperform AR models in many cases. We also observe quality gains from AR2Diff -- adapting AR models to use diffusion decoding. These results are promising given that text diffusion is relatively underexplored and can be significantly faster than AR decoding for long text generation.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
Jul 28, 2023We study how vision-language models trained on Internet-scale data can be incorporated directly into end-to-end robotic control to boost generalization and enable emergent semantic reasoning. Our goal is to enable a single end-to-end trained model to both learn to map robot observations to actions and enjoy the benefits of large-scale pretraining on language and vision-language data from the web. To this end, we propose to co-fine-tune state-of-the-art vision-language models on both robotic trajectory data and Internet-scale vision-language tasks, such as visual question answering. In contrast to other approaches, we propose a simple, general recipe to achieve this goal: in order to fit both natural language responses and robotic actions into the same format, we express the actions as text tokens and incorporate them directly into the training set of the model in the same way as natural language tokens. We refer to such category of models as vision-language-action models (VLA) and instantiate an example of such a model, which we call RT-2. Our extensive evaluation (6k evaluation trials) shows that our approach leads to performant robotic policies and enables RT-2 to obtain a range of emergent capabilities from Internet-scale training. This includes significantly improved generalization to novel objects, the ability to interpret commands not present in the robot training data (such as placing an object onto a particular number or icon), and the ability to perform rudimentary reasoning in response to user commands (such as picking up the smallest or largest object, or the one closest to another object). We further show that incorporating chain of thought reasoning allows RT-2 to perform multi-stage semantic reasoning, for example figuring out which object to pick up for use as an improvised hammer (a rock), or which type of drink is best suited for someone who is tired (an energy drink).
Plex: Towards Reliability using Pretrained Large Model Extensions
Jul 15, 2022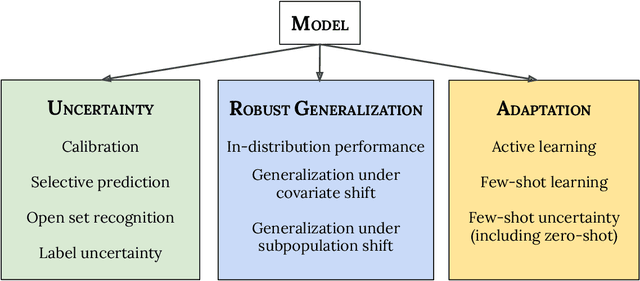

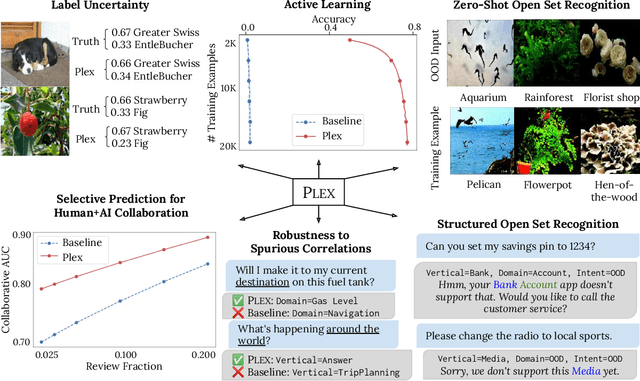

A recent trend in artificial intelligence is the use of pretrained models for language and vision tasks, which have achieved extraordinary performance but also puzzling failures. Probing these models' abilities in diverse ways is therefore critical to the field. In this paper, we explore the reliability of models, where we define a reliable model as one that not only achieves strong predictive performance but also performs well consistently over many decision-making tasks involving uncertainty (e.g., selective prediction, open set recognition), robust generalization (e.g., accuracy and proper scoring rules such as log-likelihood on in- and out-of-distribution datasets), and adaptation (e.g., active learning, few-shot uncertainty). We devise 10 types of tasks over 40 datasets in order to evaluate different aspects of reliability on both vision and language domains. To improve reliability, we developed ViT-Plex and T5-Plex, pretrained large model extensions for vision and language modalities, respectively. Plex greatly improves the state-of-the-art across reliability tasks, and simplifies the traditional protocol as it improves the out-of-the-box performance and does not require designing scores or tuning the model for each task. We demonstrate scaling effects over model sizes up to 1B parameters and pretraining dataset sizes up to 4B examples. We also demonstrate Plex's capabilities on challenging tasks including zero-shot open set recognition, active learning, and uncertainty in conversational language understanding.
Reliable Graph Neural Networks for Drug Discovery Under Distributional Shift
Nov 25, 2021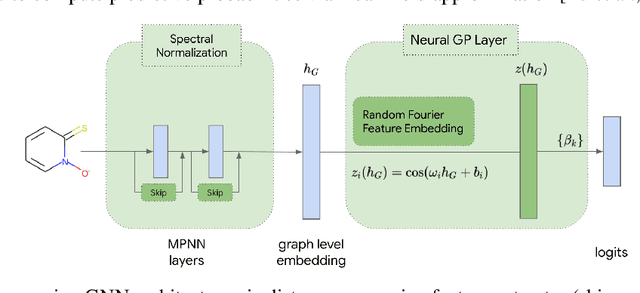
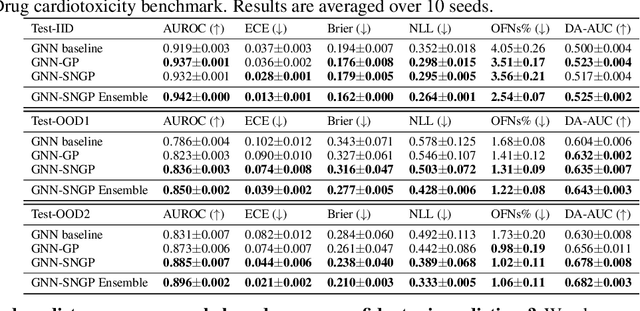
The concern of overconfident mis-predictions under distributional shift demands extensive reliability research on Graph Neural Networks used in critical tasks in drug discovery. Here we first introduce CardioTox, a real-world benchmark on drug cardio-toxicity to facilitate such efforts. Our exploratory study shows overconfident mis-predictions are often distant from training data. That leads us to develop distance-aware GNNs: GNN-SNGP. Through evaluation on CardioTox and three established benchmarks, we demonstrate GNN-SNGP's effectiveness in increasing distance-awareness, reducing overconfident mis-predictions and making better calibrated predictions without sacrificing accuracy performance. Our ablation study further reveals the representation learned by GNN-SNGP improves distance-preservation over its base architecture and is one major factor for improvements.