 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMorse Neural Networks for Uncertainty Quantification
Jul 02, 2023We introduce a new deep generative model useful for uncertainty quantification: the Morse neural network, which generalizes the unnormalized Gaussian densities to have modes of high-dimensional submanifolds instead of just discrete points. Fitting the Morse neural network via a KL-divergence loss yields 1) a (unnormalized) generative density, 2) an OOD detector, 3) a calibration temperature, 4) a generative sampler, along with in the supervised case 5) a distance aware-classifier. The Morse network can be used on top of a pre-trained network to bring distance-aware calibration w.r.t the training data. Because of its versatility, the Morse neural networks unifies many techniques: e.g., the Entropic Out-of-Distribution Detector of (Mac\^edo et al., 2021) in OOD detection, the one class Deep Support Vector Description method of (Ruff et al., 2018) in anomaly detection, or the Contrastive One Class classifier in continuous learning (Sun et al., 2021). The Morse neural network has connections to support vector machines, kernel methods, and Morse theory in topology.
Plex: Towards Reliability using Pretrained Large Model Extensions
Jul 15, 2022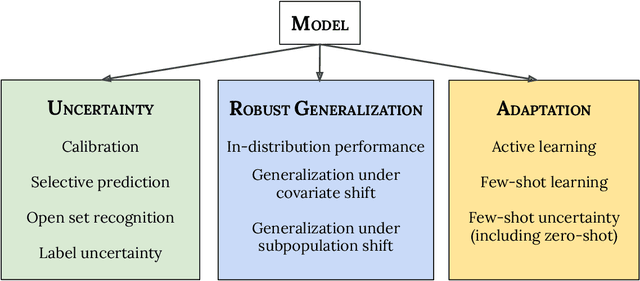

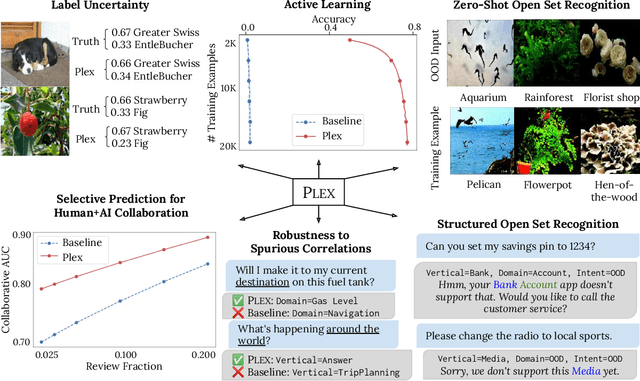

A recent trend in artificial intelligence is the use of pretrained models for language and vision tasks, which have achieved extraordinary performance but also puzzling failures. Probing these models' abilities in diverse ways is therefore critical to the field. In this paper, we explore the reliability of models, where we define a reliable model as one that not only achieves strong predictive performance but also performs well consistently over many decision-making tasks involving uncertainty (e.g., selective prediction, open set recognition), robust generalization (e.g., accuracy and proper scoring rules such as log-likelihood on in- and out-of-distribution datasets), and adaptation (e.g., active learning, few-shot uncertainty). We devise 10 types of tasks over 40 datasets in order to evaluate different aspects of reliability on both vision and language domains. To improve reliability, we developed ViT-Plex and T5-Plex, pretrained large model extensions for vision and language modalities, respectively. Plex greatly improves the state-of-the-art across reliability tasks, and simplifies the traditional protocol as it improves the out-of-the-box performance and does not require designing scores or tuning the model for each task. We demonstrate scaling effects over model sizes up to 1B parameters and pretraining dataset sizes up to 4B examples. We also demonstrate Plex's capabilities on challenging tasks including zero-shot open set recognition, active learning, and uncertainty in conversational language understanding.
Information-theoretic Online Memory Selection for Continual Learning
Apr 10, 2022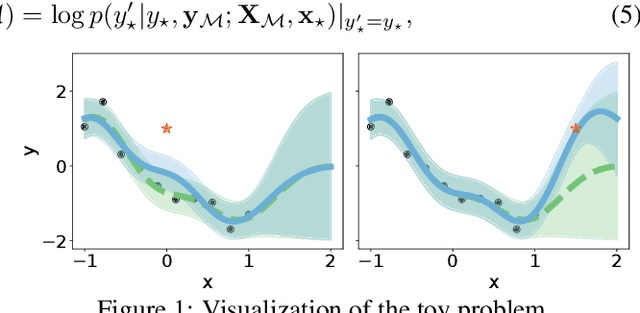
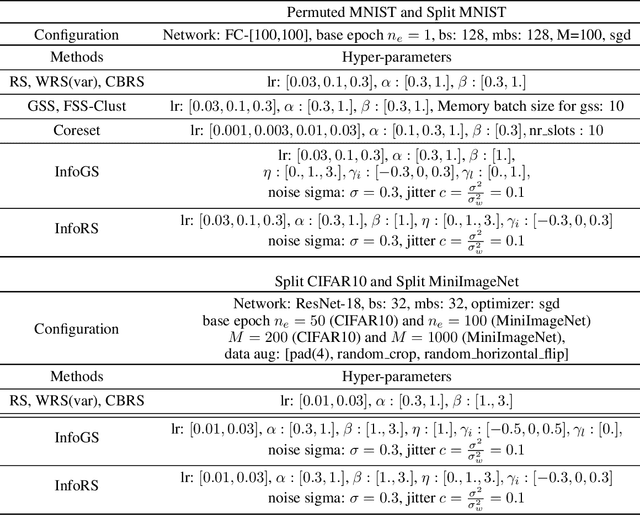
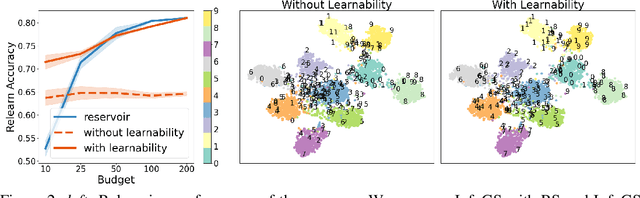
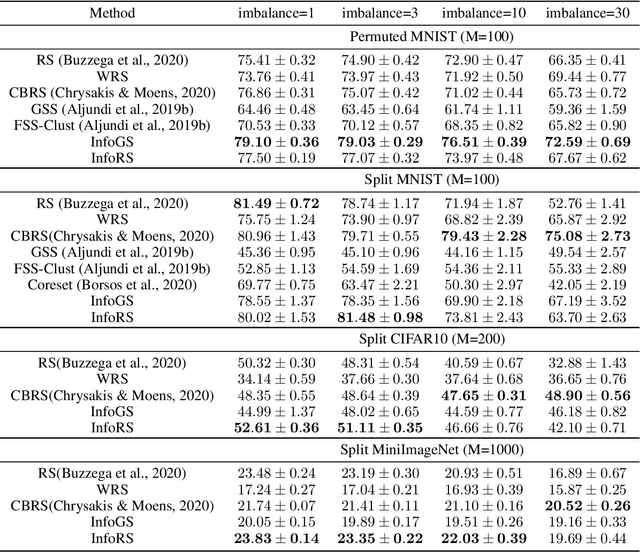
A challenging problem in task-free continual learning is the online selection of a representative replay memory from data streams. In this work, we investigate the online memory selection problem from an information-theoretic perspective. To gather the most information, we propose the \textit{surprise} and the \textit{learnability} criteria to pick informative points and to avoid outliers. We present a Bayesian model to compute the criteria efficiently by exploiting rank-one matrix structures. We demonstrate that these criteria encourage selecting informative points in a greedy algorithm for online memory selection. Furthermore, by identifying the importance of \textit{the timing to update the memory}, we introduce a stochastic information-theoretic reservoir sampler (InfoRS), which conducts sampling among selective points with high information. Compared to reservoir sampling, InfoRS demonstrates improved robustness against data imbalance. Finally, empirical performances over continual learning benchmarks manifest its efficiency and efficacy.
One Pass ImageNet
Nov 03, 2021

We present the One Pass ImageNet (OPIN) problem, which aims to study the effectiveness of deep learning in a streaming setting. ImageNet is a widely known benchmark dataset that has helped drive and evaluate recent advancements in deep learning. Typically, deep learning methods are trained on static data that the models have random access to, using multiple passes over the dataset with a random shuffle at each epoch of training. Such data access assumption does not hold in many real-world scenarios where massive data is collected from a stream and storing and accessing all the data becomes impractical due to storage costs and privacy concerns. For OPIN, we treat the ImageNet data as arriving sequentially, and there is limited memory budget to store a small subset of the data. We observe that training a deep network in a single pass with the same training settings used for multi-epoch training results in a huge drop in prediction accuracy. We show that the performance gap can be significantly decreased by paying a small memory cost and utilizing techniques developed for continual learning, despite the fact that OPIN differs from typical continual problem settings. We propose using OPIN to study resource-efficient deep learning.
Wide Neural Networks Forget Less Catastrophically
Oct 21, 2021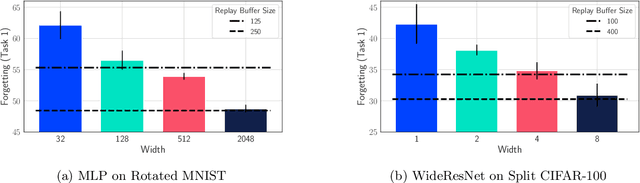
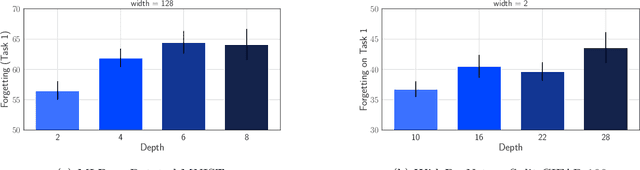
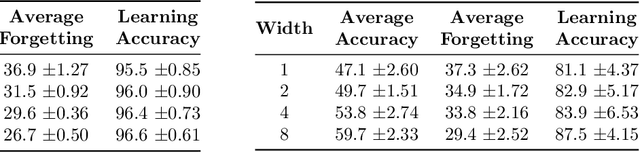
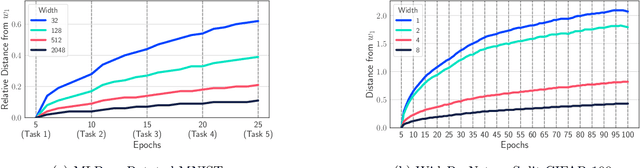
A growing body of research in continual learning is devoted to overcoming the "Catastrophic Forgetting" of neural networks by designing new algorithms that are more robust to the distribution shifts. While the recent progress in continual learning literature is encouraging, our understanding of what properties of neural networks contribute to catastrophic forgetting is still limited. To address this, instead of focusing on continual learning algorithms, in this work, we focus on the model itself and study the impact of "width" of the neural network architecture on catastrophic forgetting, and show that width has a surprisingly significant effect on forgetting. To explain this effect, we study the learning dynamics of the network from various perspectives such as gradient norm and sparsity, orthogonalization, and lazy training regime. We provide potential explanations that are consistent with the empirical results across different architectures and continual learning benchmarks.
Task-agnostic Continual Learning with Hybrid Probabilistic Models
Jun 24, 2021



Learning new tasks continuously without forgetting on a constantly changing data distribution is essential for real-world problems but extremely challenging for modern deep learning. In this work we propose HCL, a Hybrid generative-discriminative approach to Continual Learning for classification. We model the distribution of each task and each class with a normalizing flow. The flow is used to learn the data distribution, perform classification, identify task changes, and avoid forgetting, all leveraging the invertibility and exact likelihood which are uniquely enabled by the normalizing flow model. We use the generative capabilities of the flow to avoid catastrophic forgetting through generative replay and a novel functional regularization technique. For task identification, we use state-of-the-art anomaly detection techniques based on measuring the typicality of the model's statistics. We demonstrate the strong performance of HCL on a range of continual learning benchmarks such as split-MNIST, split-CIFAR, and SVHN-MNIST.
Deep Ensembles: A Loss Landscape Perspective
Dec 05, 2019
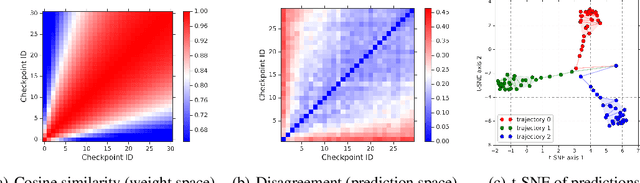
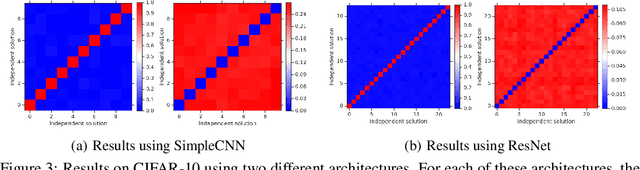

Deep ensembles have been empirically shown to be a promising approach for improving accuracy, uncertainty and out-of-distribution robustness of deep learning models. While deep ensembles were theoretically motivated by the bootstrap, non-bootstrap ensembles trained with just random initialization also perform well in practice, which suggests that there could be other explanations for why deep ensembles work well. Bayesian neural networks, which learn distributions over the parameters of the network, are theoretically well-motivated by Bayesian principles, but do not perform as well as deep ensembles in practice, particularly under dataset shift. One possible explanation for this gap between theory and practice is that popular scalable approximate Bayesian methods tend to focus on a single mode, whereas deep ensembles tend to explore diverse modes in function space. We investigate this hypothesis by building on recent work on understanding the loss landscape of neural networks and adding our own exploration to measure the similarity of functions in the space of predictions. Our results show that random initializations explore entirely different modes, while functions along an optimization trajectory or sampled from the subspace thereof cluster within a single mode predictions-wise, while often deviating significantly in the weight space. We demonstrate that while low-loss connectors between modes exist, they are not connected in the space of predictions. Developing the concept of the diversity--accuracy plane, we show that the decorrelation power of random initializations is unmatched by popular subspace sampling methods.
Cross-View Policy Learning for Street Navigation
Jun 13, 2019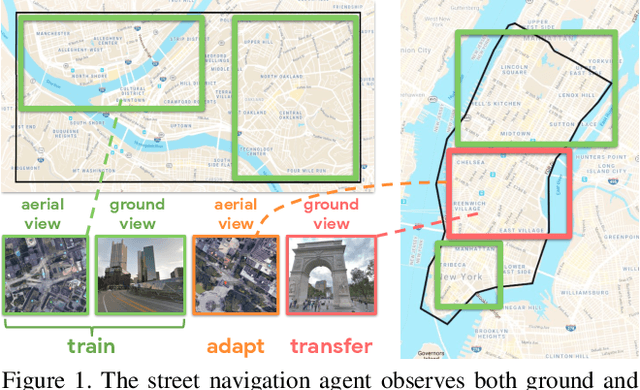
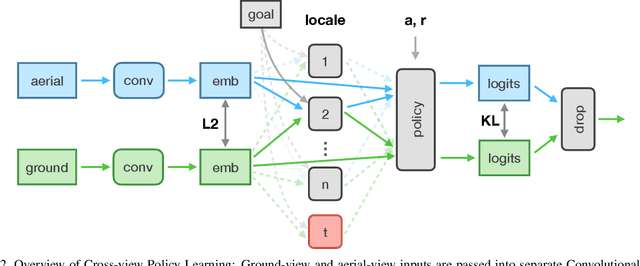
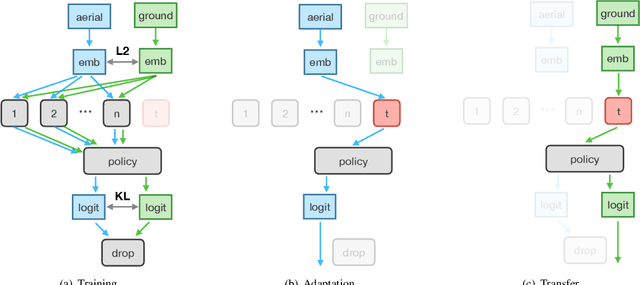
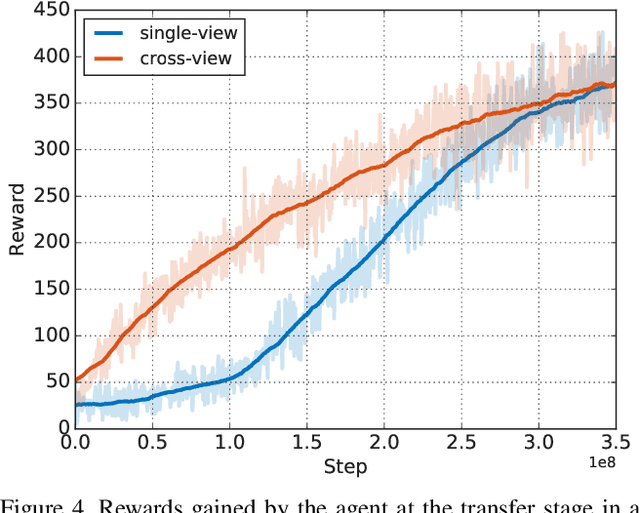
The ability to navigate from visual observations in unfamiliar environments is a core component of intelligent agents and an ongoing challenge for Deep Reinforcement Learning (RL). Street View can be a sensible testbed for such RL agents, because it provides real-world photographic imagery at ground level, with diverse street appearances; it has been made into an interactive environment called StreetLearn and used for research on navigation. However, goal-driven street navigation agents have not so far been able to transfer to unseen areas without extensive retraining, and relying on simulation is not a scalable solution. Since aerial images are easily and globally accessible, we propose instead to train a multi-modal policy on ground and aerial views, then transfer the ground view policy to unseen (target) parts of the city by utilizing aerial view observations. Our core idea is to pair the ground view with an aerial view and to learn a joint policy that is transferable across views. We achieve this by learning a similar embedding space for both views, distilling the policy across views and dropping out visual modalities. We further reformulate the transfer learning paradigm into three stages: 1) cross-modal training, when the agent is initially trained on multiple city regions, 2) aerial view-only adaptation to a new area, when the agent is adapted to a held-out region using only the easily obtainable aerial view, and 3) ground view-only transfer, when the agent is tested on navigation tasks on unseen ground views, without aerial imagery. Experimental results suggest that the proposed cross-view policy learning enables better generalization of the agent and allows for more effective transfer to unseen environments.
Learning from Delayed Outcomes with Intermediate Observations
Jul 24, 2018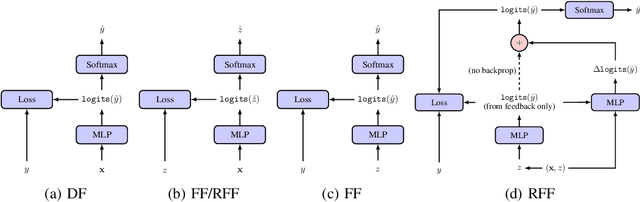

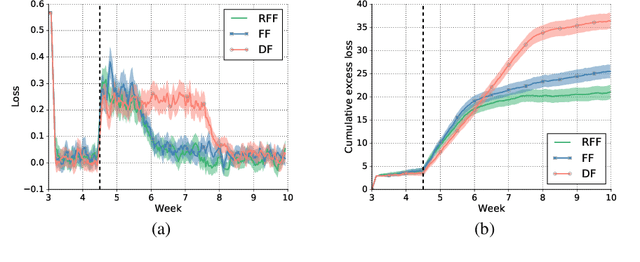
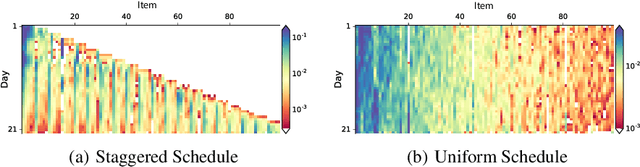
Optimizing for long term value is desirable in many practical applications, e.g. recommender systems. The most common approach for long term value optimization is supervised learning using long term value as the target. Unfortunately, long term metrics take a long time to measure (e.g., will customers finish reading an ebook?), and vanilla forecasters cannot learn from examples until the outcome is observed. In practical systems where new items arrive frequently, such delay can increase the training-serving skew, thereby negatively affecting the model's predictions for new products. We argue that intermediate observations (e.g., if customers read a third of the book in 24 hours) can improve a model's predictions. We formalize the problem as a semi-stochastic model, where instances are selected by an adversary but, given an instance, the intermediate observation and the outcome are sampled from a factored joint distribution. We propose an algorithm that exploits intermediate observations and theoretically quantify how much it can outperform any prediction method that ignores the intermediate observations. Motivated by the theoretical analysis, we propose two neural network architectures: Factored Forecaster (FF) which is ideal if our assumptions are satisfied, and Residual Factored Forecaster (RFF) that is more robust to model mis-specification. Experiments on two real world datasets, a dataset derived from GitHub repositories and another dataset from a popular marketplace, show that RFF outperforms both FF as well as an algorithm that ignores intermediate observations.
End-to-End Interpretation of the French Street Name Signs Dataset
Feb 13, 2017


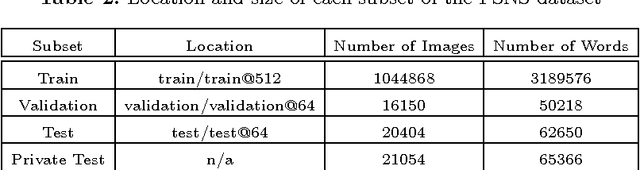
We introduce the French Street Name Signs (FSNS) Dataset consisting of more than a million images of street name signs cropped from Google Street View images of France. Each image contains several views of the same street name sign. Every image has normalized, title case folded ground-truth text as it would appear on a map. We believe that the FSNS dataset is large and complex enough to train a deep network of significant complexity to solve the street name extraction problem "end-to-end" or to explore the design trade-offs between a single complex engineered network and multiple sub-networks designed and trained to solve sub-problems. We present such an "end-to-end" network/graph for Tensor Flow and its results on the FSNS dataset.
* Presented at the IWRR workshop at ECCV 2016