 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Illusion of Stochasticity in LLMs
Apr 08, 2026In this work, we demonstrate that reliable stochastic sampling is a fundamental yet unfulfilled requirement for Large Language Models (LLMs) operating as agents. Agentic systems are frequently required to sample from distributions, often inferred from observed data, a process which needs to be emulated by the LLM. This leads to a distinct failure point: while standard RL agents rely on external sampling mechanisms, LLMs fail to map their internal probability estimates to their stochastic outputs. Through rigorous empirical analysis across multiple model families, model sizes, prompting styles, and distributions, we demonstrate the extent of this failure. Crucially, we show that while powerful frontier models can convert provided random seeds to target distributions, their ability to sample directly from specific distributions is fundamentally flawed.
Information-theoretic Online Memory Selection for Continual Learning
Apr 10, 2022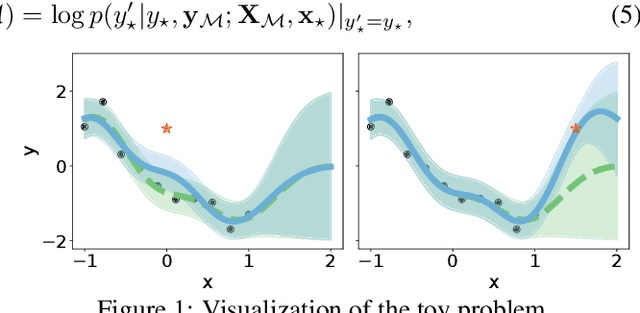
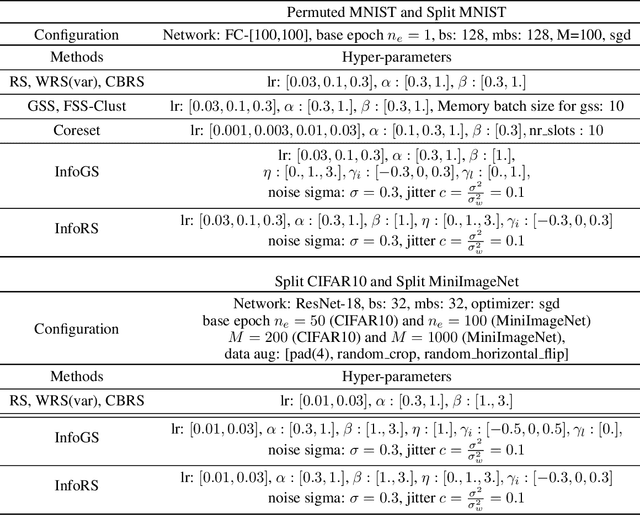
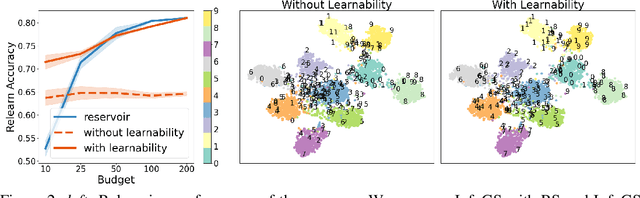
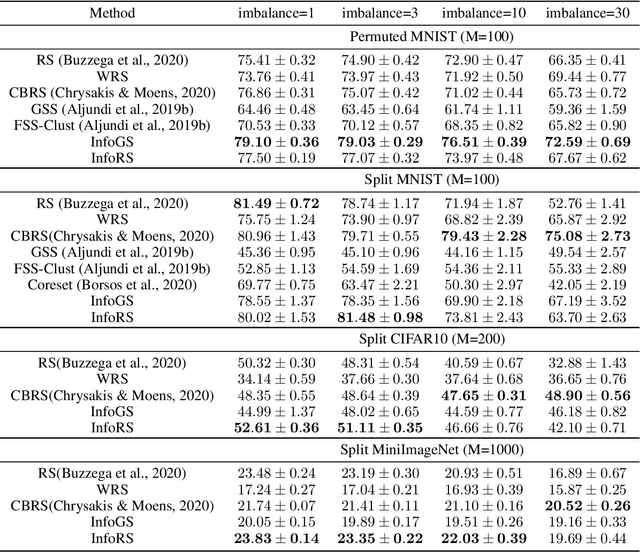
A challenging problem in task-free continual learning is the online selection of a representative replay memory from data streams. In this work, we investigate the online memory selection problem from an information-theoretic perspective. To gather the most information, we propose the \textit{surprise} and the \textit{learnability} criteria to pick informative points and to avoid outliers. We present a Bayesian model to compute the criteria efficiently by exploiting rank-one matrix structures. We demonstrate that these criteria encourage selecting informative points in a greedy algorithm for online memory selection. Furthermore, by identifying the importance of \textit{the timing to update the memory}, we introduce a stochastic information-theoretic reservoir sampler (InfoRS), which conducts sampling among selective points with high information. Compared to reservoir sampling, InfoRS demonstrates improved robustness against data imbalance. Finally, empirical performances over continual learning benchmarks manifest its efficiency and efficacy.
Manifold Relevance Determination
Jun 18, 2012


In this paper we present a fully Bayesian latent variable model which exploits conditional nonlinear(in)-dependence structures to learn an efficient latent representation. The latent space is factorized to represent shared and private information from multiple views of the data. In contrast to previous approaches, we introduce a relaxation to the discrete segmentation and allow for a "softly" shared latent space. Further, Bayesian techniques allow us to automatically estimate the dimensionality of the latent spaces. The model is capable of capturing structure underlying extremely high dimensional spaces. This is illustrated by modelling unprocessed images with tenths of thousands of pixels. This also allows us to directly generate novel images from the trained model by sampling from the discovered latent spaces. We also demonstrate the model by prediction of human pose in an ambiguous setting. Our Bayesian framework allows us to perform disambiguation in a principled manner by including latent space priors which incorporate the dynamic nature of the data.