 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeploying Semantic ID-based Generative Retrieval for Large-Scale Podcast Discovery at Spotify
Mar 18, 2026Podcast listening is often grounded in a set of favorite shows, while listener intent can evolve over time. This combination of stable preferences and changing intent motivates recommendation approaches that support both familiarity and exploration. Traditional recommender systems typically emphasize long-term interaction patterns, and are less explicitly designed to incorporate rich contextual signals or flexible, intent-aware discovery objectives. In this setting, models that can jointly reason over semantics, context, and user state offer a promising direction. Large Language Models (LLMs) provide strong semantic reasoning and contextual conditioning for discovery-oriented recommendation, but deploying them in production introduces challenges in catalog grounding, user-level personalization, and latency-critical serving. We address these challenges with GLIDE, a production-scale generative recommender for podcast discovery at Spotify. GLIDE formulates recommendation as an instruction-following task over a discretized catalog using Semantic IDs, enabling grounded generation over a large inventory. The model conditions on recent listening history and lightweight user context, while injecting long-term user embeddings as soft prompts to capture stable preferences under strict inference constraints. We evaluate GLIDE using offline retrieval metrics, human judgments, and LLM-based evaluation, and validate its impact through large-scale online A/B testing. Across experiments involving millions of users, GLIDE increases non-habitual podcast streaming on Spotify home surface by up to 5.4% and new-show discovery by up to 14.3%, while meeting production cost and latency constraints.
A Unified Language Model for Large Scale Search, Recommendation, and Reasoning
Mar 18, 2026LLMs are increasingly applied to recommendation, retrieval, and reasoning, yet deploying a single end-to-end model that can jointly support these behaviors over large, heterogeneous catalogs remains challenging. Such systems must generate unambiguous references to real items, handle multiple entity types, and operate under strict latency and reliability constraints requirements that are difficult to satisfy with text-only generation. While tool-augmented recommender systems address parts of this problem, they introduce orchestration complexity and limit end-to-end optimization. We view this setting as an instance of a broader research problem: how to adapt LLMs to reason jointly over multiple-domain entities, users, and language in a fully self-contained manner. To this end, we introduce NEO, a framework that adapts a pre-trained decoder-only LLM into a tool-free, catalog-grounded generator. NEO represents items as SIDs and trains a single model to interleave natural language and typed item identifiers within a shared sequence. Text prompts control the task, target entity type, and output format (IDs, text, or mixed), while constrained decoding guarantees catalog-valid item generation without restricting free-form text. We refer to this instruction-conditioned controllability as language-steerability. We treat SIDs as a distinct modality and study design choices for integrating discrete entity representations into LLMs via staged alignment and instruction tuning. We evaluate NEO at scale on a real-world catalog of over 10M items across multiple media types and discovery tasks, including recommendation, search, and user understanding. In offline experiments, NEO consistently outperforms strong task-specific baselines and exhibits cross-task transfer, demonstrating a practical path toward consolidating large-scale discovery capabilities into a single language-steerable generative model.
Mapping Faithful Reasoning in Language Models
Oct 25, 2025Chain-of-thought (CoT) traces promise transparency for reasoning language models, but prior work shows they are not always faithful reflections of internal computation. This raises challenges for oversight: practitioners may misinterpret decorative reasoning as genuine. We introduce Concept Walk, a general framework for tracing how a model's internal stance evolves with respect to a concept direction during reasoning. Unlike surface text, Concept Walk operates in activation space, projecting each reasoning step onto the concept direction learned from contrastive data. This allows us to observe whether reasoning traces shape outcomes or are discarded. As a case study, we apply Concept Walk to the domain of Safety using Qwen 3-4B. We find that in 'easy' cases, perturbed CoTs are quickly ignored, indicating decorative reasoning, whereas in 'hard' cases, perturbations induce sustained shifts in internal activations, consistent with faithful reasoning. The contribution is methodological: Concept Walk provides a lens to re-examine faithfulness through concept-specific internal dynamics, helping identify when reasoning traces can be trusted and when they risk misleading practitioners.
Evaluating Podcast Recommendations with Profile-Aware LLM-as-a-Judge
Aug 12, 2025



Evaluating personalized recommendations remains a central challenge, especially in long-form audio domains like podcasts, where traditional offline metrics suffer from exposure bias and online methods such as A/B testing are costly and operationally constrained. In this paper, we propose a novel framework that leverages Large Language Models (LLMs) as offline judges to assess the quality of podcast recommendations in a scalable and interpretable manner. Our two-stage profile-aware approach first constructs natural-language user profiles distilled from 90 days of listening history. These profiles summarize both topical interests and behavioral patterns, serving as compact, interpretable representations of user preferences. Rather than prompting the LLM with raw data, we use these profiles to provide high-level, semantically rich context-enabling the LLM to reason more effectively about alignment between a user's interests and recommended episodes. This reduces input complexity and improves interpretability. The LLM is then prompted to deliver fine-grained pointwise and pairwise judgments based on the profile-episode match. In a controlled study with 47 participants, our profile-aware judge matched human judgments with high fidelity and outperformed or matched a variant using raw listening histories. The framework enables efficient, profile-aware evaluation for iterative testing and model selection in recommender systems.
Text2Tracks: Prompt-based Music Recommendation via Generative Retrieval
Mar 31, 2025



In recent years, Large Language Models (LLMs) have enabled users to provide highly specific music recommendation requests using natural language prompts (e.g. "Can you recommend some old classics for slow dancing?"). In this setup, the recommended tracks are predicted by the LLM in an autoregressive way, i.e. the LLM generates the track titles one token at a time. While intuitive, this approach has several limitation. First, it is based on a general purpose tokenization that is optimized for words rather than for track titles. Second, it necessitates an additional entity resolution layer that matches the track title to the actual track identifier. Third, the number of decoding steps scales linearly with the length of the track title, slowing down inference. In this paper, we propose to address the task of prompt-based music recommendation as a generative retrieval task. Within this setting, we introduce novel, effective, and efficient representations of track identifiers that significantly outperform commonly used strategies. We introduce Text2Tracks, a generative retrieval model that learns a mapping from a user's music recommendation prompt to the relevant track IDs directly. Through an offline evaluation on a dataset of playlists with language inputs, we find that (1) the strategy to create IDs for music tracks is the most important factor for the effectiveness of Text2Tracks and semantic IDs significantly outperform commonly used strategies that rely on song titles as identifiers (2) provided with the right choice of track identifiers, Text2Tracks outperforms sparse and dense retrieval solutions trained to retrieve tracks from language prompts.
Policy-as-Prompt: Rethinking Content Moderation in the Age of Large Language Models
Feb 25, 2025
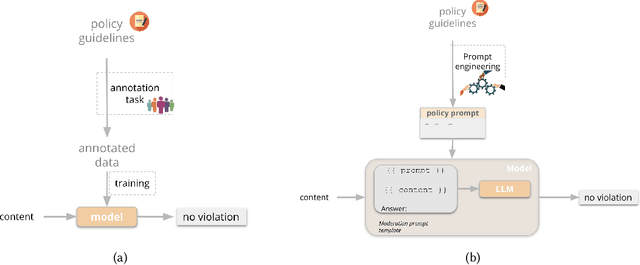

Content moderation plays a critical role in shaping safe and inclusive online environments, balancing platform standards, user expectations, and regulatory frameworks. Traditionally, this process involves operationalising policies into guidelines, which are then used by downstream human moderators for enforcement, or to further annotate datasets for training machine learning moderation models. However, recent advancements in large language models (LLMs) are transforming this landscape. These models can now interpret policies directly as textual inputs, eliminating the need for extensive data curation. This approach offers unprecedented flexibility, as moderation can be dynamically adjusted through natural language interactions. This paradigm shift raises important questions about how policies are operationalised and the implications for content moderation practices. In this paper, we formalise the emerging policy-as-prompt framework and identify five key challenges across four domains: Technical Implementation (1. translating policy to prompts, 2. sensitivity to prompt structure and formatting), Sociotechnical (3. the risk of technological determinism in policy formation), Organisational (4. evolving roles between policy and machine learning teams), and Governance (5. model governance and accountability). Through analysing these challenges across technical, sociotechnical, organisational, and governance dimensions, we discuss potential mitigation approaches. This research provides actionable insights for practitioners and lays the groundwork for future exploration of scalable and adaptive content moderation systems in digital ecosystems.
Generating Query Recommendations via LLMs
Jun 04, 2024Query recommendation systems are ubiquitous in modern search engines, assisting users in producing effective queries to meet their information needs. However, these systems require a large amount of data to produce good recommendations, such as a large collection of documents to index and query logs. In particular, query logs and user data are not available in cold start scenarios. Query logs are expensive to collect and maintain and require complex and time-consuming cascading pipelines for creating, combining, and ranking recommendations. To address these issues, we frame the query recommendation problem as a generative task, proposing a novel approach called Generative Query Recommendation (GQR). GQR uses an LLM as its foundation and does not require to be trained or fine-tuned to tackle the query recommendation problem. We design a prompt that enables the LLM to understand the specific recommendation task, even using a single example. We then improved our system by proposing a version that exploits query logs called Retriever-Augmented GQR (RA-GQR). RA-GQr dynamically composes its prompt by retrieving similar queries from query logs. GQR approaches reuses a pre-existing neural architecture resulting in a simpler and more ready-to-market approach, even in a cold start scenario. Our proposed GQR obtains state-of-the-art performance in terms of NDCG@10 and clarity score against two commercial search engines and the previous state-of-the-art approach on the Robust04 and ClueWeb09B collections, improving on average the NDCG@10 performance up to ~4% on Robust04 and ClueWeb09B w.r.t the previous best competitor. RA-GQR further improve the NDCG@10 obtaining an increase of ~11%, ~6\% on Robust04 and ClueWeb09B w.r.t the best competitor. Furthermore, our system obtained ~59% of user preferences in a blind user study, proving that our method produces the most engaging queries.
Towards Graph Foundation Models for Personalization
Mar 12, 2024In the realm of personalization, integrating diverse information sources such as consumption signals and content-based representations is becoming increasingly critical to build state-of-the-art solutions. In this regard, two of the biggest trends in research around this subject are Graph Neural Networks (GNNs) and Foundation Models (FMs). While GNNs emerged as a popular solution in industry for powering personalization at scale, FMs have only recently caught attention for their promising performance in personalization tasks like ranking and retrieval. In this paper, we present a graph-based foundation modeling approach tailored to personalization. Central to this approach is a Heterogeneous GNN (HGNN) designed to capture multi-hop content and consumption relationships across a range of recommendable item types. To ensure the generality required from a Foundation Model, we employ a Large Language Model (LLM) text-based featurization of nodes that accommodates all item types, and construct the graph using co-interaction signals, which inherently transcend content specificity. To facilitate practical generalization, we further couple the HGNN with an adaptation mechanism based on a two-tower (2T) architecture, which also operates agnostically to content type. This multi-stage approach ensures high scalability; while the HGNN produces general purpose embeddings, the 2T component models in a continuous space the sheer size of user-item interaction data. Our comprehensive approach has been rigorously tested and proven effective in delivering recommendations across a diverse array of products within a real-world, industrial audio streaming platform.
Personalized Audiobook Recommendations at Spotify Through Graph Neural Networks
Mar 08, 2024In the ever-evolving digital audio landscape, Spotify, well-known for its music and talk content, has recently introduced audiobooks to its vast user base. While promising, this move presents significant challenges for personalized recommendations. Unlike music and podcasts, audiobooks, initially available for a fee, cannot be easily skimmed before purchase, posing higher stakes for the relevance of recommendations. Furthermore, introducing a new content type into an existing platform confronts extreme data sparsity, as most users are unfamiliar with this new content type. Lastly, recommending content to millions of users requires the model to react fast and be scalable. To address these challenges, we leverage podcast and music user preferences and introduce 2T-HGNN, a scalable recommendation system comprising Heterogeneous Graph Neural Networks (HGNNs) and a Two Tower (2T) model. This novel approach uncovers nuanced item relationships while ensuring low latency and complexity. We decouple users from the HGNN graph and propose an innovative multi-link neighbor sampler. These choices, together with the 2T component, significantly reduce the complexity of the HGNN model. Empirical evaluations involving millions of users show significant improvement in the quality of personalized recommendations, resulting in a +46% increase in new audiobooks start rate and a +23% boost in streaming rates. Intriguingly, our model's impact extends beyond audiobooks, benefiting established products like podcasts.
Fast Adaptation with Linearized Neural Networks
Mar 02, 2021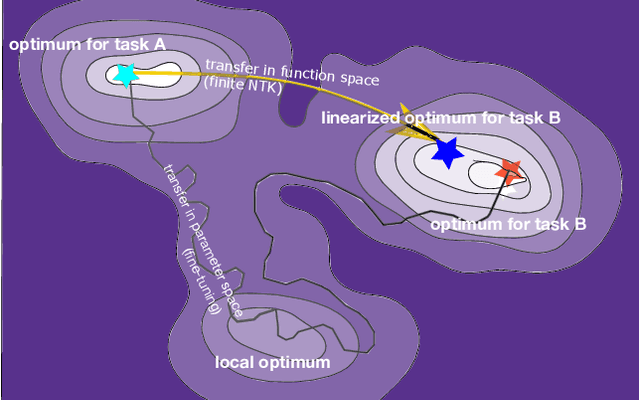

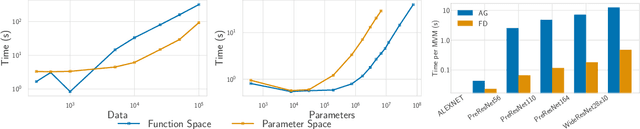
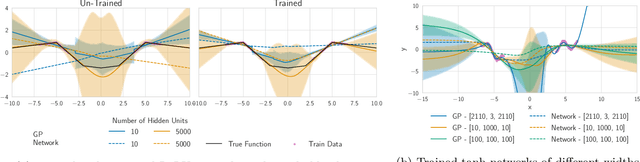
The inductive biases of trained neural networks are difficult to understand and, consequently, to adapt to new settings. We study the inductive biases of linearizations of neural networks, which we show to be surprisingly good summaries of the full network functions. Inspired by this finding, we propose a technique for embedding these inductive biases into Gaussian processes through a kernel designed from the Jacobian of the network. In this setting, domain adaptation takes the form of interpretable posterior inference, with accompanying uncertainty estimation. This inference is analytic and free of local optima issues found in standard techniques such as fine-tuning neural network weights to a new task. We develop significant computational speed-ups based on matrix multiplies, including a novel implementation for scalable Fisher vector products. Our experiments on both image classification and regression demonstrate the promise and convenience of this framework for transfer learning, compared to neural network fine-tuning. Code is available at https://github.com/amzn/xfer/tree/master/finite_ntk.