 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaterials Expert-Artificial Intelligence for Materials Discovery
Dec 05, 2023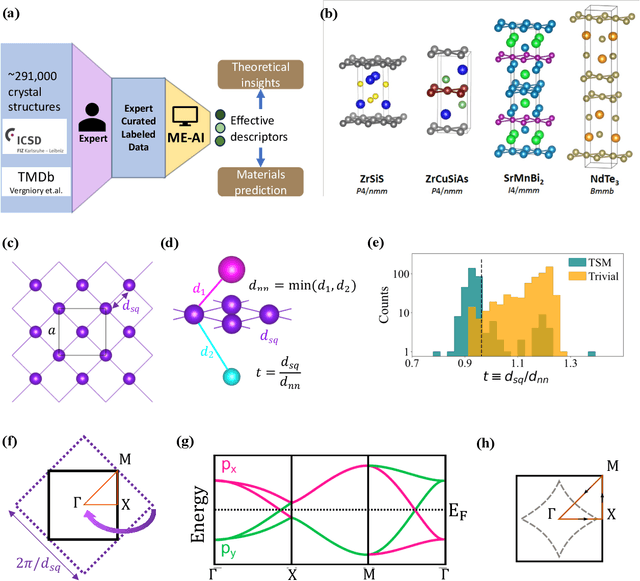


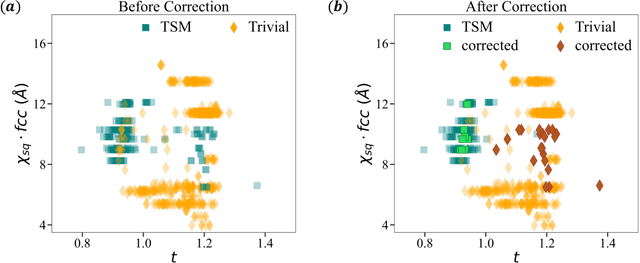
The advent of material databases provides an unprecedented opportunity to uncover predictive descriptors for emergent material properties from vast data space. However, common reliance on high-throughput ab initio data necessarily inherits limitations of such data: mismatch with experiments. On the other hand, experimental decisions are often guided by an expert's intuition honed from experiences that are rarely articulated. We propose using machine learning to "bottle" such operational intuition into quantifiable descriptors using expertly curated measurement-based data. We introduce "Materials Expert-Artificial Intelligence" (ME-AI) to encapsulate and articulate this human intuition. As a first step towards such a program, we focus on the topological semimetal (TSM) among square-net materials as the property inspired by the expert-identified descriptor based on structural information: the tolerance factor. We start by curating a dataset encompassing 12 primary features of 879 square-net materials, using experimental data whenever possible. We then use Dirichlet-based Gaussian process regression using a specialized kernel to reveal composite descriptors for square-net topological semimetals. The ME-AI learned descriptors independently reproduce expert intuition and expand upon it. Specifically, new descriptors point to hypervalency as a critical chemical feature predicting TSM within square-net compounds. Our success with a carefully defined problem points to the "machine bottling human insight" approach as promising for machine learning-aided material discovery.
Low-Precision Arithmetic for Fast Gaussian Processes
Jul 14, 2022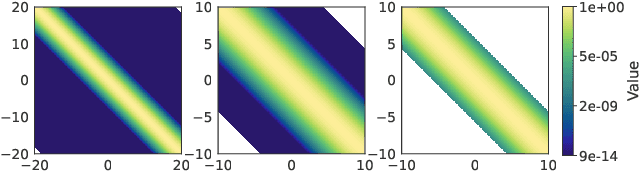
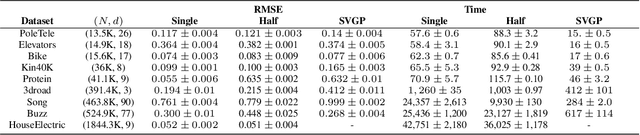

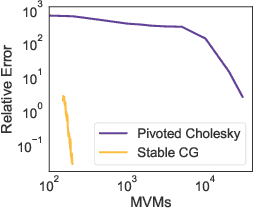
Low-precision arithmetic has had a transformative effect on the training of neural networks, reducing computation, memory and energy requirements. However, despite its promise, low-precision arithmetic has received little attention for Gaussian processes (GPs), largely because GPs require sophisticated linear algebra routines that are unstable in low-precision. We study the different failure modes that can occur when training GPs in half precision. To circumvent these failure modes, we propose a multi-faceted approach involving conjugate gradients with re-orthogonalization, mixed precision, and preconditioning. Our approach significantly improves the numerical stability and practical performance of conjugate gradients in low-precision over a wide range of settings, enabling GPs to train on $1.8$ million data points in $10$ hours on a single GPU, without any sparse approximations.
Volatility Based Kernels and Moving Average Means for Accurate Forecasting with Gaussian Processes
Jul 13, 2022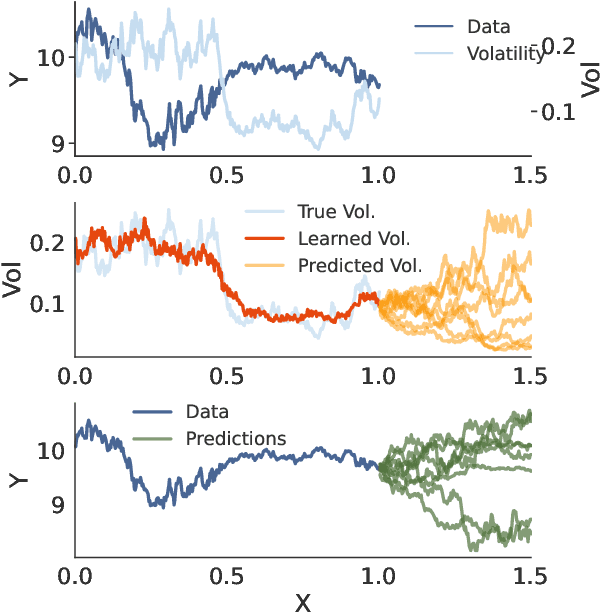
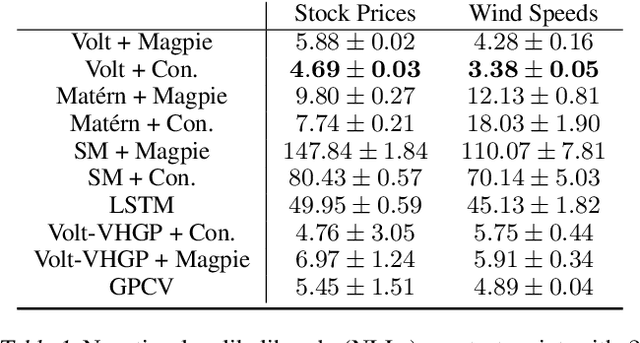


A broad class of stochastic volatility models are defined by systems of stochastic differential equations. While these models have seen widespread success in domains such as finance and statistical climatology, they typically lack an ability to condition on historical data to produce a true posterior distribution. To address this fundamental limitation, we show how to re-cast a class of stochastic volatility models as a hierarchical Gaussian process (GP) model with specialized covariance functions. This GP model retains the inductive biases of the stochastic volatility model while providing the posterior predictive distribution given by GP inference. Within this framework, we take inspiration from well studied domains to introduce a new class of models, Volt and Magpie, that significantly outperform baselines in stock and wind speed forecasting, and naturally extend to the multitask setting.
On Uncertainty, Tempering, and Data Augmentation in Bayesian Classification
Mar 30, 2022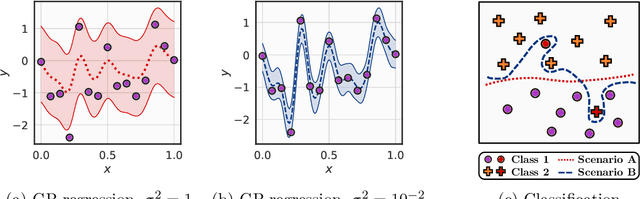
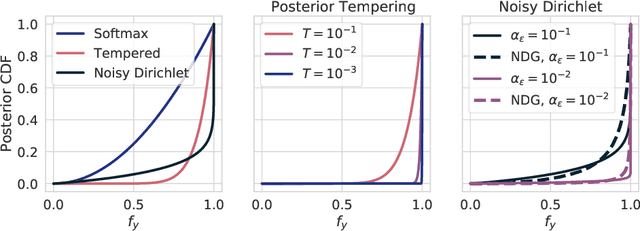
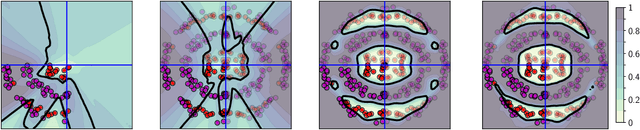
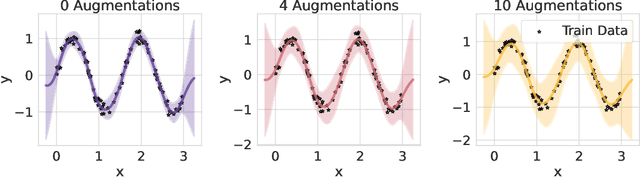
Aleatoric uncertainty captures the inherent randomness of the data, such as measurement noise. In Bayesian regression, we often use a Gaussian observation model, where we control the level of aleatoric uncertainty with a noise variance parameter. By contrast, for Bayesian classification we use a categorical distribution with no mechanism to represent our beliefs about aleatoric uncertainty. Our work shows that explicitly accounting for aleatoric uncertainty significantly improves the performance of Bayesian neural networks. We note that many standard benchmarks, such as CIFAR, have essentially no aleatoric uncertainty. Moreover, we show data augmentation in approximate inference has the effect of softening the likelihood, leading to underconfidence and profoundly misrepresenting our honest beliefs about aleatoric uncertainty. Accordingly, we find that a cold posterior, tempered by a power greater than one, often more honestly reflects our beliefs about aleatoric uncertainty than no tempering -- providing an explicit link between data augmentation and cold posteriors. We show that we can match or exceed the performance of posterior tempering by using a Dirichlet observation model, where we explicitly control the level of aleatoric uncertainty, without any need for tempering.
When are Iterative Gaussian Processes Reliably Accurate?
Dec 31, 2021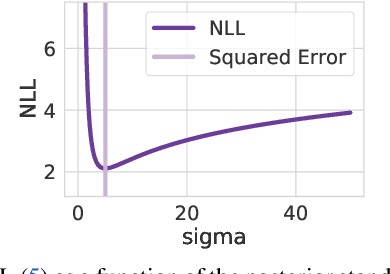

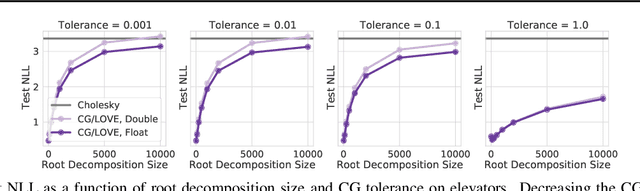

While recent work on conjugate gradient methods and Lanczos decompositions have achieved scalable Gaussian process inference with highly accurate point predictions, in several implementations these iterative methods appear to struggle with numerical instabilities in learning kernel hyperparameters, and poor test likelihoods. By investigating CG tolerance, preconditioner rank, and Lanczos decomposition rank, we provide a particularly simple prescription to correct these issues: we recommend that one should use a small CG tolerance ($\epsilon \leq 0.01$) and a large root decomposition size ($r \geq 5000$). Moreover, we show that L-BFGS-B is a compelling optimizer for Iterative GPs, achieving convergence with fewer gradient updates.
Conditioning Sparse Variational Gaussian Processes for Online Decision-making
Oct 28, 2021
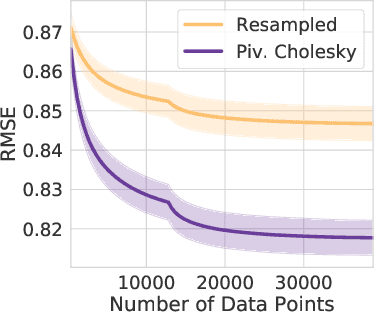
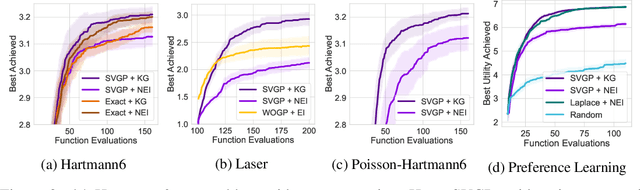
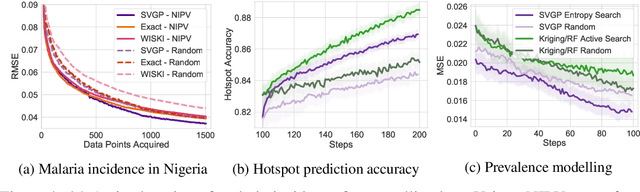
With a principled representation of uncertainty and closed form posterior updates, Gaussian processes (GPs) are a natural choice for online decision making. However, Gaussian processes typically require at least $\mathcal{O}(n^2)$ computations for $n$ training points, limiting their general applicability. Stochastic variational Gaussian processes (SVGPs) can provide scalable inference for a dataset of fixed size, but are difficult to efficiently condition on new data. We propose online variational conditioning (OVC), a procedure for efficiently conditioning SVGPs in an online setting that does not require re-training through the evidence lower bound with the addition of new data. OVC enables the pairing of SVGPs with advanced look-ahead acquisition functions for black-box optimization, even with non-Gaussian likelihoods. We show OVC provides compelling performance in a range of applications including active learning of malaria incidence, and reinforcement learning on MuJoCo simulated robotic control tasks.
Bayesian Optimization with High-Dimensional Outputs
Jun 24, 2021
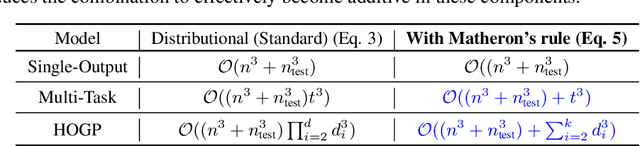
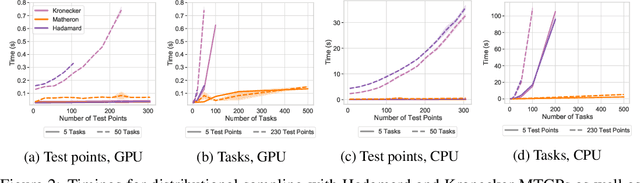

Bayesian Optimization is a sample-efficient black-box optimization procedure that is typically applied to problems with a small number of independent objectives. However, in practice we often wish to optimize objectives defined over many correlated outcomes (or ``tasks"). For example, scientists may want to optimize the coverage of a cell tower network across a dense grid of locations. Similarly, engineers may seek to balance the performance of a robot across dozens of different environments via constrained or robust optimization. However, the Gaussian Process (GP) models typically used as probabilistic surrogates for multi-task Bayesian Optimization scale poorly with the number of outcomes, greatly limiting applicability. We devise an efficient technique for exact multi-task GP sampling that combines exploiting Kronecker structure in the covariance matrices with Matheron's identity, allowing us to perform Bayesian Optimization using exact multi-task GP models with tens of thousands of correlated outputs. In doing so, we achieve substantial improvements in sample efficiency compared to existing approaches that only model aggregate functions of the outcomes. We demonstrate how this unlocks a new class of applications for Bayesian Optimization across a range of tasks in science and engineering, including optimizing interference patterns of an optical interferometer with more than 65,000 outputs.
Kernel Interpolation for Scalable Online Gaussian Processes
Mar 02, 2021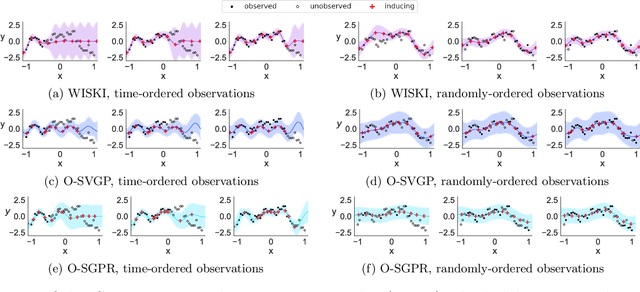
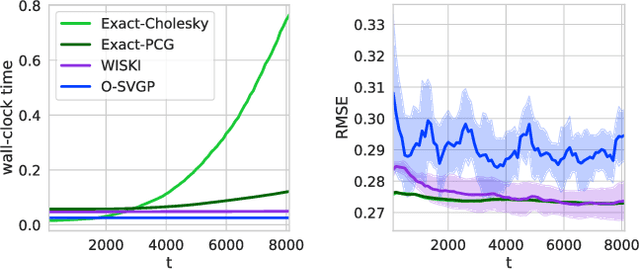
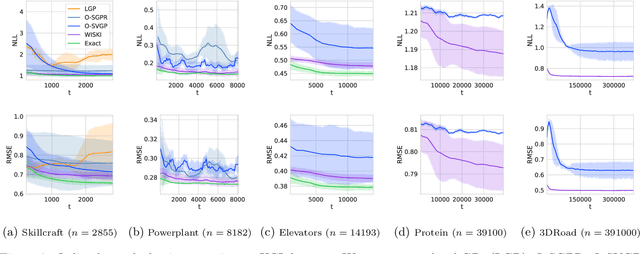
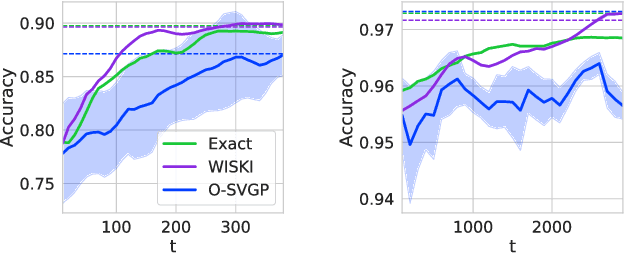
Gaussian processes (GPs) provide a gold standard for performance in online settings, such as sample-efficient control and black box optimization, where we need to update a posterior distribution as we acquire data in a sequential fashion. However, updating a GP posterior to accommodate even a single new observation after having observed $n$ points incurs at least $O(n)$ computations in the exact setting. We show how to use structured kernel interpolation to efficiently recycle computations for constant-time $O(1)$ online updates with respect to the number of points $n$, while retaining exact inference. We demonstrate the promise of our approach in a range of online regression and classification settings, Bayesian optimization, and active sampling to reduce error in malaria incidence forecasting. Code is available at https://github.com/wjmaddox/online_gp.
Fast Adaptation with Linearized Neural Networks
Mar 02, 2021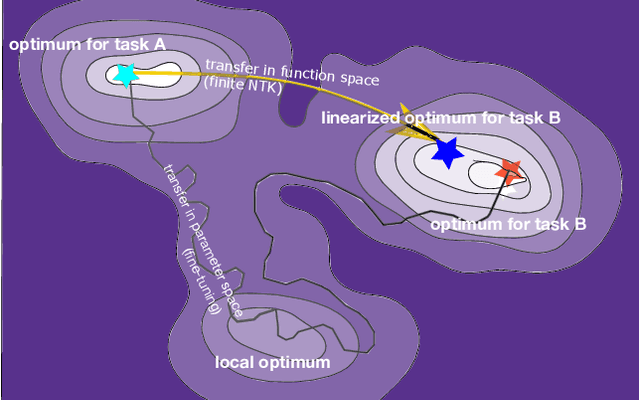

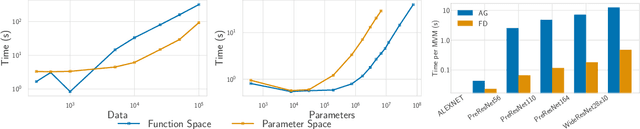
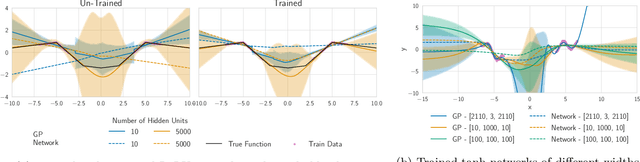
The inductive biases of trained neural networks are difficult to understand and, consequently, to adapt to new settings. We study the inductive biases of linearizations of neural networks, which we show to be surprisingly good summaries of the full network functions. Inspired by this finding, we propose a technique for embedding these inductive biases into Gaussian processes through a kernel designed from the Jacobian of the network. In this setting, domain adaptation takes the form of interpretable posterior inference, with accompanying uncertainty estimation. This inference is analytic and free of local optima issues found in standard techniques such as fine-tuning neural network weights to a new task. We develop significant computational speed-ups based on matrix multiplies, including a novel implementation for scalable Fisher vector products. Our experiments on both image classification and regression demonstrate the promise and convenience of this framework for transfer learning, compared to neural network fine-tuning. Code is available at https://github.com/amzn/xfer/tree/master/finite_ntk.
Loss Surface Simplexes for Mode Connecting Volumes and Fast Ensembling
Feb 25, 2021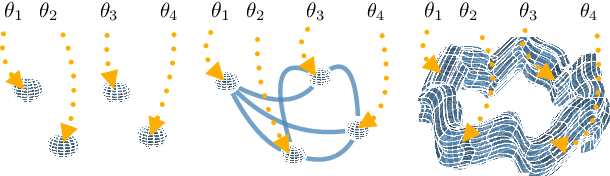
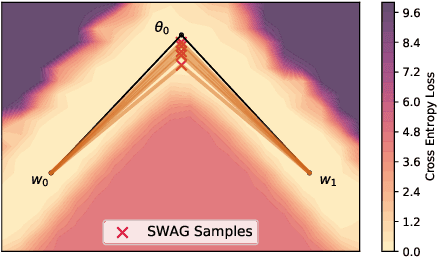
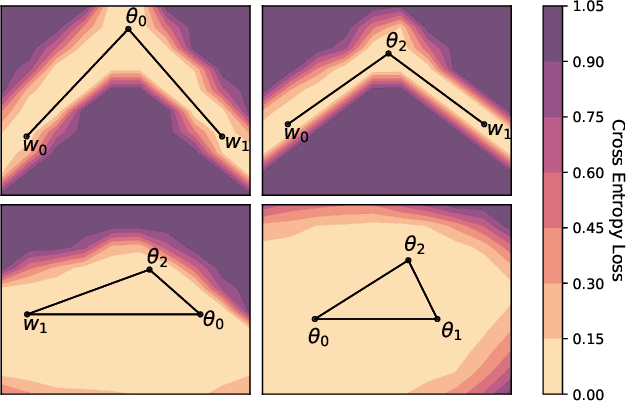
With a better understanding of the loss surfaces for multilayer networks, we can build more robust and accurate training procedures. Recently it was discovered that independently trained SGD solutions can be connected along one-dimensional paths of near-constant training loss. In this paper, we show that there are mode-connecting simplicial complexes that form multi-dimensional manifolds of low loss, connecting many independently trained models. Inspired by this discovery, we show how to efficiently build simplicial complexes for fast ensembling, outperforming independently trained deep ensembles in accuracy, calibration, and robustness to dataset shift. Notably, our approach only requires a few training epochs to discover a low-loss simplex, starting from a pre-trained solution. Code is available at https://github.com/g-benton/loss-surface-simplexes.