 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Context Compression at Scale
Jun 08, 2026Long-context language model inference is bottlenecked by memory, as the KV cache grows with context length. Recent techniques to compress the KV cache fall short: they either degrade model quality substantially or require considerable time and compute to compress a single long prompt. Furthermore, many methods require the input to fit within the target model's context window, and are generally incompatible with modern production inference engines. Encoder-decoder compressors, which map a long token sequence to a shorter sequence of latent embeddings consumed by a decoder, are an appealing alternative in principle. However, existing approaches are not competitive with KV cache compression on the accuracy-efficiency frontier. In this work, we revisit encoder-decoder compression and close this gap. We first perform an architecture search, pre-training many variants from scratch to determine how best to design and train encoder-decoder compressors. Guided by our findings, we continually pre-train a family of 0.6B-encoder, 4B-decoder models on over 350B tokens each, at compression ratios of 1:4, 1:8, and 1:16. We introduce Latent Context Language Models (LCLMs), a family of compressors that improve the Pareto frontier across general-task performance, compression speed, and peak memory usage. We demonstrate that LCLMs serve as efficient backbones for long-horizon agents, letting the agent skim through a compressed long context and adaptively expand relevant segments on demand.
Quantized Reasoning Models Think They Need to Think Longer, but They Do Not
May 29, 2026Post-training quantization (PTQ) is widely used to deploy large language models efficiently, but its effect on reasoning models is not well understood. Across math, coding, and science QA, we find that aggressive PTQ reduces accuracy while increasing chain-of-thought (CoT) length. Surprisingly, we show that in up to 52% of the quantized models' failures, models reach the right answer in intermediate reasoning steps but do not output it as a final answer. To understand why quantization leads to this increase in overthinking errors, we measure the token-level KL divergence between quantized and full-precision output distributions. Positions with high KL divergence correlate strongly with high next-token entropy, and at these positions quantized models disproportionately sample overthinking markers such as "wait", "but", and "alternatively". We show that simply introducing a training-free logit penalty on a curated set of overthinking markers can reduce CoT length by 12--23% while preserving or improving accuracy across 5 models (1.5B-32B parameters), 3 quantization methods, and 5 benchmarks, yielding a favorable Pareto frontier of accuracy against reasoning cost compared to penalizing other token sets. Overthinking errors produced by quantized models are particularly reduced by up to 58%.
Trade-offs in Ensembling, Merging and Routing Among Parameter-Efficient Experts
Mar 03, 2026While large language models (LLMs) fine-tuned with lightweight adapters achieve strong performance across diverse tasks, their performance on individual tasks depends on the fine-tuning strategy. Fusing independently trained models with different strengths has shown promise for multi-task learning through three main strategies: ensembling, which combines outputs from independent models; merging, which fuses model weights via parameter averaging; and routing, which integrates models in an input-dependent fashion. However, many design decisions in these approaches remain understudied, and the relative benefits of more sophisticated ensembling, merging and routing techniques are not fully understood. We empirically evaluate their trade-offs, addressing two key questions: What are the advantages of going beyond uniform ensembling or merging? And does the flexibility of routing justify its complexity? Our findings indicate that non-uniform ensembling and merging improve performance, but routing offers even greater gains. To mitigate the computational cost of routing, we analyze expert selection techniques, showing that clustering and greedy subset selection can maintain reasonable performance with minimal overhead. These insights advance our understanding of model fusion for multi-task learning.
Uncertainty Drives Social Bias Changes in Quantized Large Language Models
Feb 05, 2026Post-training quantization reduces the computational cost of large language models but fundamentally alters their social biases in ways that aggregate metrics fail to capture. We present the first large-scale study of 50 quantized models evaluated on PostTrainingBiasBench, a unified benchmark of 13 closed- and open-ended bias datasets. We identify a phenomenon we term quantization-induced masked bias flipping, in which up to 21% of responses flip between biased and unbiased states after quantization, despite showing no change in aggregate bias scores. These flips are strongly driven by model uncertainty, where the responses with high uncertainty are 3-11x more likely to change than the confident ones. Quantization strength amplifies this effect, with 4-bit quantized models exhibiting 4-6x more behavioral changes than 8-bit quantized models. Critically, these changes create asymmetric impacts across demographic groups, where bias can worsen by up to 18.6% for some groups while improving by 14.1% for others, yielding misleadingly neutral aggregate outcomes. Larger models show no consistent robustness advantage, and group-specific shifts vary unpredictably across model families. Our findings demonstrate that compression fundamentally alters bias patterns, requiring crucial post-quantization evaluation and interventions to ensure reliability in practice.
Customizing the Inductive Biases of Softmax Attention using Structured Matrices
Sep 09, 2025The core component of attention is the scoring function, which transforms the inputs into low-dimensional queries and keys and takes the dot product of each pair. While the low-dimensional projection improves efficiency, it causes information loss for certain tasks that have intrinsically high-dimensional inputs. Additionally, attention uses the same scoring function for all input pairs, without imposing a distance-dependent compute bias for neighboring tokens in the sequence. In this work, we address these shortcomings by proposing new scoring functions based on computationally efficient structured matrices with high ranks, including Block Tensor-Train (BTT) and Multi-Level Low Rank (MLR) matrices. On in-context regression tasks with high-dimensional inputs, our proposed scoring functions outperform standard attention for any fixed compute budget. On language modeling, a task that exhibits locality patterns, our MLR-based attention method achieves improved scaling laws compared to both standard attention and variants of sliding window attention. Additionally, we show that both BTT and MLR fall under a broader family of efficient structured matrices capable of encoding either full-rank or distance-dependent compute biases, thereby addressing significant shortcomings of standard attention. Finally, we show that MLR attention has promising results for long-range time-series forecasting.
Small Batch Size Training for Language Models: When Vanilla SGD Works, and Why Gradient Accumulation Is Wasteful
Jul 09, 2025Conventional wisdom dictates that small batch sizes make language model pretraining and fine-tuning unstable, motivating gradient accumulation, which trades off the number of optimizer steps for a proportional increase in batch size. While it is common to decrease the learning rate for smaller batch sizes, other hyperparameters are often held fixed. In this work, we revisit small batch sizes all the way down to batch size one, and we propose a rule for scaling Adam hyperparameters to small batch sizes. We find that small batch sizes (1) train stably, (2) are consistently more robust to hyperparameter choices, (3) achieve equal or better per-FLOP performance than larger batch sizes, and (4) notably enable stable language model training with vanilla SGD, even without momentum, despite storing no optimizer state. Building on these results, we provide practical recommendations for selecting a batch size and setting optimizer hyperparameters. We further recommend against gradient accumulation unless training on multiple devices with multiple model replicas, bottlenecked by inter-device bandwidth.
Unlocking Tokens as Data Points for Generalization Bounds on Larger Language Models
Jul 25, 2024Large language models (LLMs) with billions of parameters excel at predicting the next token in a sequence. Recent work computes non-vacuous compression-based generalization bounds for LLMs, but these bounds are vacuous for large models at the billion-parameter scale. Moreover, these bounds are obtained through restrictive compression techniques, bounding compressed models that generate low-quality text. Additionally, the tightness of these existing bounds depends on the number of IID documents in a training set rather than the much larger number of non-IID constituent tokens, leaving untapped potential for tighter bounds. In this work, we instead use properties of martingales to derive generalization bounds that benefit from the vast number of tokens in LLM training sets. Since a dataset contains far more tokens than documents, our generalization bounds not only tolerate but actually benefit from far less restrictive compression schemes. With Monarch matrices, Kronecker factorizations, and post-training quantization, we achieve non-vacuous generalization bounds for LLMs as large as LLaMA2-70B. Unlike previous approaches, our work achieves the first non-vacuous bounds for models that are deployed in practice and generate high-quality text.
Non-Vacuous Generalization Bounds for Large Language Models
Dec 28, 2023Modern language models can contain billions of parameters, raising the question of whether they can generalize beyond the training data or simply regurgitate their training corpora. We provide the first non-vacuous generalization bounds for pretrained large language models (LLMs), indicating that language models are capable of discovering regularities that generalize to unseen data. In particular, we derive a compression bound that is valid for the unbounded log-likelihood loss using prediction smoothing, and we extend the bound to handle subsampling, accelerating bound computation on massive datasets. To achieve the extreme level of compression required for non-vacuous generalization bounds, we devise SubLoRA, a low-dimensional non-linear parameterization. Using this approach, we find that larger models have better generalization bounds and are more compressible than smaller models.
PAC-Bayes Compression Bounds So Tight That They Can Explain Generalization
Nov 24, 2022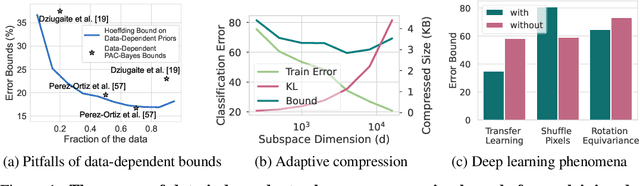

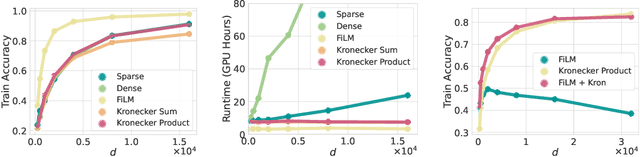
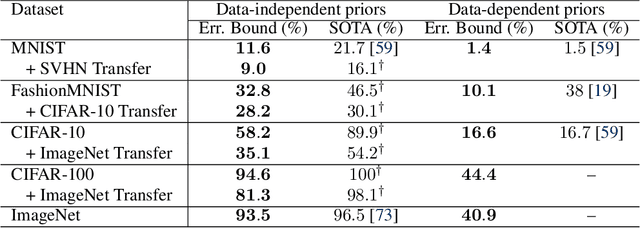
While there has been progress in developing non-vacuous generalization bounds for deep neural networks, these bounds tend to be uninformative about why deep learning works. In this paper, we develop a compression approach based on quantizing neural network parameters in a linear subspace, profoundly improving on previous results to provide state-of-the-art generalization bounds on a variety of tasks, including transfer learning. We use these tight bounds to better understand the role of model size, equivariance, and the implicit biases of optimization, for generalization in deep learning. Notably, we find large models can be compressed to a much greater extent than previously known, encapsulating Occam's razor. We also argue for data-independent bounds in explaining generalization.
Bayesian Model Selection, the Marginal Likelihood, and Generalization
Feb 23, 2022
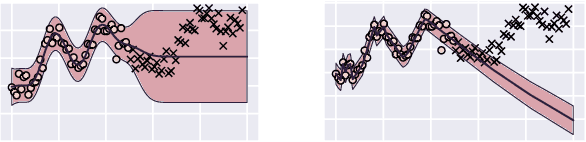
How do we compare between hypotheses that are entirely consistent with observations? The marginal likelihood (aka Bayesian evidence), which represents the probability of generating our observations from a prior, provides a distinctive approach to this foundational question, automatically encoding Occam's razor. Although it has been observed that the marginal likelihood can overfit and is sensitive to prior assumptions, its limitations for hyperparameter learning and discrete model comparison have not been thoroughly investigated. We first revisit the appealing properties of the marginal likelihood for learning constraints and hypothesis testing. We then highlight the conceptual and practical issues in using the marginal likelihood as a proxy for generalization. Namely, we show how marginal likelihood can be negatively correlated with generalization, with implications for neural architecture search, and can lead to both underfitting and overfitting in hyperparameter learning. We provide a partial remedy through a conditional marginal likelihood, which we show is more aligned with generalization, and practically valuable for large-scale hyperparameter learning, such as in deep kernel learning.