 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Context Compression at Scale
Jun 08, 2026Long-context language model inference is bottlenecked by memory, as the KV cache grows with context length. Recent techniques to compress the KV cache fall short: they either degrade model quality substantially or require considerable time and compute to compress a single long prompt. Furthermore, many methods require the input to fit within the target model's context window, and are generally incompatible with modern production inference engines. Encoder-decoder compressors, which map a long token sequence to a shorter sequence of latent embeddings consumed by a decoder, are an appealing alternative in principle. However, existing approaches are not competitive with KV cache compression on the accuracy-efficiency frontier. In this work, we revisit encoder-decoder compression and close this gap. We first perform an architecture search, pre-training many variants from scratch to determine how best to design and train encoder-decoder compressors. Guided by our findings, we continually pre-train a family of 0.6B-encoder, 4B-decoder models on over 350B tokens each, at compression ratios of 1:4, 1:8, and 1:16. We introduce Latent Context Language Models (LCLMs), a family of compressors that improve the Pareto frontier across general-task performance, compression speed, and peak memory usage. We demonstrate that LCLMs serve as efficient backbones for long-horizon agents, letting the agent skim through a compressed long context and adaptively expand relevant segments on demand.
How's it going? Reinforcement learning in language models recruits a functional welfare axis
May 28, 2026How does reinforcement learning shape a language model's internal representations? We present evidence that RL recruits a pre-existing representation of functional welfare: an estimate of how well or badly the system is doing, relative to its goals. We train several language models in a novel, semantically neutral maze environment. We then extract concept vectors for rewarded and punished trajectories, and evaluate those vectors in settings unrelated to the maze environment. The punishment vector behaves like a representation of negative welfare: it promotes failure and impossibility tokens, it aligns with negative emotion concepts, it negatively tracks goal-achievement, and steering with it induces negative self-reports, pathological backtracking, refusal, and uncertainty. The positive reward vector behaves as the mirror image, and the two are nearly antiparallel. These effects are robust when controlling for tile-to-reward mapping, scale, instruct tuning, RL training algorithm, model family, and LoRA versus full-finetuning, and largely persist when we replace RL with supervised fine-tuning. Importantly, the vectors are effective in models before they have undergone maze training. Combined with observations that the effects also appear in pretrain-only models, we therefore argue that this functional welfare axis pre-exists post-training: it is recruited, rather than created, by post-training. While we make no claims about any experience of welfare, the axis offers a demonstration that minimal reward signals can broadly affect model behavior by recruiting pre-existing welfare-like representations, with implications for interpretability, post-training dynamics, and alignment.
Forgetting in Language Models: Capacity, Optimization, and Self-Generated Replay
May 25, 2026Models trained on a new task typically degrade on prior tasks, a phenomenon known as forgetting. Traditionally, mitigating forgetting has required replaying stored exemplars from prior tasks, which is often impractical. By contrast, language models can sample from their own training distribution, and we show that these self-generated samples serve as effective replay data, nearly eliminating forgetting. We find that forgetting nonetheless persists when the model has little remaining capacity: models pretrained close to saturation cannot absorb new information without overwriting prior knowledge. When capacity is not the limiting factor, low learning rates reduce forgetting but require substantially more training steps. Replay breaks this tradeoff, enabling fast, high-learning-rate finetuning without forgetting.
DiscoverPhysics: Benchmarking LLMs for Out-of-the-Box Scientific Thinking
May 25, 2026Frontier LLMs now perform strongly across a wide range of physics evaluations, but it is hard to disentangle genuine reasoning from recall of established science. We introduce DiscoverPhysics, an interactive benchmark that asks a LLM agent to discover the laws of motion of a simulated world whose physics deliberately deviates from our own. We construct 22 worlds governed by, among others, screened and fractional-power gravity, multi-species couplings, hidden dark-matter-like particles, non-coordinate-free physics, and time-varying interactions. Each world is generated on demand by an N-body simulator, for which the agent proposes several rounds of experiments, observes raw trajectory data, and ultimately submits both a natural-language explanation of the world's physics and a Python implementation of the inferred law. Because solving a world requires the agent to design informative experiments and revise its hypotheses, the benchmark probes long-horizon reasoning over an experimental history. We evaluate submissions along two complementary axes: trajectory MSE on held-out particles and an LLM-judged explanation score following an expert-written rubric assessing conceptual understanding of each world. Across eleven frontier models, we find that the strongest agents pass only half of the worlds and consistently fail on those where latent structure must be uncovered. Open-source models lag substantially behind commercial models, both in their ability to design informative experiments and in extracting conclusions from the data. We further find that good predictive accuracy does not guarantee high explanation quality and that conceptual understanding depends on hypothesis refinement through well-chosen experiments.
When Can LLMs Learn to Reason with Weak Supervision?
Apr 20, 2026Large language models have achieved significant reasoning improvements through reinforcement learning with verifiable rewards (RLVR). Yet as model capabilities grow, constructing high-quality reward signals becomes increasingly difficult, making it essential to understand when RLVR can succeed under weaker forms of supervision. We conduct a systematic empirical study across diverse model families and reasoning domains under three weak supervision settings: scarce data, noisy rewards, and self-supervised proxy rewards. We find that generalization is governed by training reward saturation dynamics: models that generalize exhibit a prolonged pre-saturation phase during which training reward and downstream performance climb together, while models that saturate rapidly memorize rather than learn. We identify reasoning faithfulness, defined as the extent to which intermediate steps logically support the final answer, as the pre-RL property that predicts which regime a model falls into, while output diversity alone is uninformative. Motivated by these findings, we disentangle the contributions of continual pre-training and supervised fine-tuning, finding that SFT on explicit reasoning traces is necessary for generalization under weak supervision, while continual pre-training on domain data amplifies the effect. Applied together to Llama3.2-3B-Base, these interventions enable generalization across all three settings where the base model previously failed.
Reliable and Responsible Foundation Models: A Comprehensive Survey
Feb 04, 2026Foundation models, including Large Language Models (LLMs), Multimodal Large Language Models (MLLMs), Image Generative Models (i.e, Text-to-Image Models and Image-Editing Models), and Video Generative Models, have become essential tools with broad applications across various domains such as law, medicine, education, finance, science, and beyond. As these models see increasing real-world deployment, ensuring their reliability and responsibility has become critical for academia, industry, and government. This survey addresses the reliable and responsible development of foundation models. We explore critical issues, including bias and fairness, security and privacy, uncertainty, explainability, and distribution shift. Our research also covers model limitations, such as hallucinations, as well as methods like alignment and Artificial Intelligence-Generated Content (AIGC) detection. For each area, we review the current state of the field and outline concrete future research directions. Additionally, we discuss the intersections between these areas, highlighting their connections and shared challenges. We hope our survey fosters the development of foundation models that are not only powerful but also ethical, trustworthy, reliable, and socially responsible.
From Entropy to Epiplexity: Rethinking Information for Computationally Bounded Intelligence
Jan 06, 2026Can we learn more from data than existed in the generating process itself? Can new and useful information be constructed from merely applying deterministic transformations to existing data? Can the learnable content in data be evaluated without considering a downstream task? On these questions, Shannon information and Kolmogorov complexity come up nearly empty-handed, in part because they assume observers with unlimited computational capacity and fail to target the useful information content. In this work, we identify and exemplify three seeming paradoxes in information theory: (1) information cannot be increased by deterministic transformations; (2) information is independent of the order of data; (3) likelihood modeling is merely distribution matching. To shed light on the tension between these results and modern practice, and to quantify the value of data, we introduce epiplexity, a formalization of information capturing what computationally bounded observers can learn from data. Epiplexity captures the structural content in data while excluding time-bounded entropy, the random unpredictable content exemplified by pseudorandom number generators and chaotic dynamical systems. With these concepts, we demonstrate how information can be created with computation, how it depends on the ordering of the data, and how likelihood modeling can produce more complex programs than present in the data generating process itself. We also present practical procedures to estimate epiplexity which we show capture differences across data sources, track with downstream performance, and highlight dataset interventions that improve out-of-distribution generalization. In contrast to principles of model selection, epiplexity provides a theoretical foundation for data selection, guiding how to select, generate, or transform data for learning systems.
Improving Semantic Uncertainty Quantification in LVLMs with Semantic Gaussian Processes
Dec 16, 2025Large Vision-Language Models (LVLMs) often produce plausible but unreliable outputs, making robust uncertainty estimation essential. Recent work on semantic uncertainty estimates relies on external models to cluster multiple sampled responses and measure their semantic consistency. However, these clustering methods are often fragile, highly sensitive to minor phrasing variations, and can incorrectly group or separate semantically similar answers, leading to unreliable uncertainty estimates. We propose Semantic Gaussian Process Uncertainty (SGPU), a Bayesian framework that quantifies semantic uncertainty by analyzing the geometric structure of answer embeddings, avoiding brittle clustering. SGPU maps generated answers into a dense semantic space, computes the Gram matrix of their embeddings, and summarizes their semantic configuration via the eigenspectrum. This spectral representation is then fed into a Gaussian Process Classifier that learns to map patterns of semantic consistency to predictive uncertainty, and that can be applied in both black-box and white-box settings. Across six LLMs and LVLMs on eight datasets spanning VQA, image classification, and textual QA, SGPU consistently achieves state-of-the-art calibration (ECE) and discriminative (AUROC, AUARC) performance. We further show that SGPU transfers across models and modalities, indicating that its spectral representation captures general patterns of semantic uncertainty.
Closing the Train-Test Gap in World Models for Gradient-Based Planning
Dec 10, 2025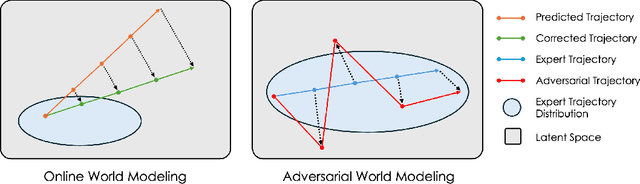
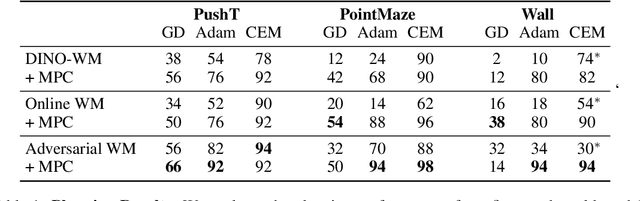
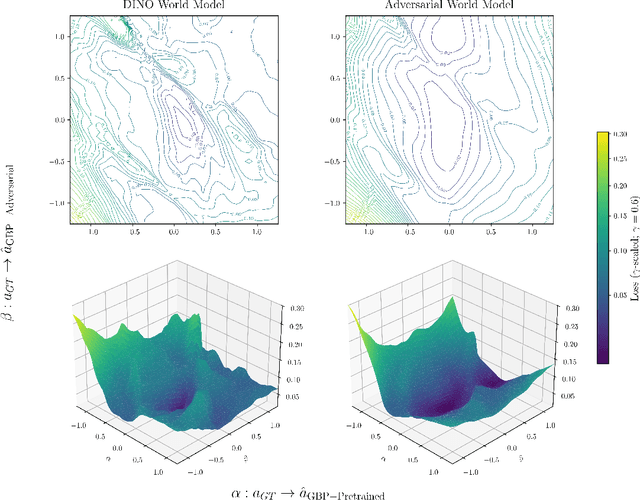
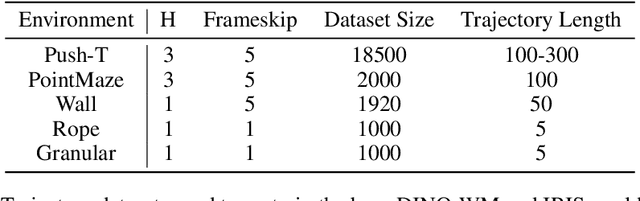
World models paired with model predictive control (MPC) can be trained offline on large-scale datasets of expert trajectories and enable generalization to a wide range of planning tasks at inference time. Compared to traditional MPC procedures, which rely on slow search algorithms or on iteratively solving optimization problems exactly, gradient-based planning offers a computationally efficient alternative. However, the performance of gradient-based planning has thus far lagged behind that of other approaches. In this paper, we propose improved methods for training world models that enable efficient gradient-based planning. We begin with the observation that although a world model is trained on a next-state prediction objective, it is used at test-time to instead estimate a sequence of actions. The goal of our work is to close this train-test gap. To that end, we propose train-time data synthesis techniques that enable significantly improved gradient-based planning with existing world models. At test time, our approach outperforms or matches the classical gradient-free cross-entropy method (CEM) across a variety of object manipulation and navigation tasks in 10% of the time budget.
OpenAI o1 System Card
Dec 21, 2024



The o1 model series is trained with large-scale reinforcement learning to reason using chain of thought. These advanced reasoning capabilities provide new avenues for improving the safety and robustness of our models. In particular, our models can reason about our safety policies in context when responding to potentially unsafe prompts, through deliberative alignment. This leads to state-of-the-art performance on certain benchmarks for risks such as generating illicit advice, choosing stereotyped responses, and succumbing to known jailbreaks. Training models to incorporate a chain of thought before answering has the potential to unlock substantial benefits, while also increasing potential risks that stem from heightened intelligence. Our results underscore the need for building robust alignment methods, extensively stress-testing their efficacy, and maintaining meticulous risk management protocols. This report outlines the safety work carried out for the OpenAI o1 and OpenAI o1-mini models, including safety evaluations, external red teaming, and Preparedness Framework evaluations.