 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmilesT5: Domain-specific pretraining for molecular language models
Jul 30, 2025Molecular property prediction is an increasingly critical task within drug discovery and development. Typically, neural networks can learn molecular properties using graph-based, language-based or feature-based methods. Recent advances in natural language processing have highlighted the capabilities of neural networks to learn complex human language using masked language modelling. These approaches to training large transformer-based deep learning models have also been used to learn the language of molecules, as represented by simplified molecular-input line-entry system (SMILES) strings. Here, we present novel domain-specific text-to-text pretraining tasks that yield improved performance in six classification-based molecular property prediction benchmarks, relative to both traditional likelihood-based training and previously proposed fine-tuning tasks. Through ablation studies, we show that data and computational efficiency can be improved by using these domain-specific pretraining tasks. Finally, the pretrained embeddings from the model can be used as fixed inputs into a downstream machine learning classifier and yield comparable performance to finetuning but with much lower computational overhead.
Time-varying Factor Augmented Vector Autoregression with Grouped Sparse Autoencoder
Mar 06, 2025Recent economic events, including the global financial crisis and COVID-19 pandemic, have exposed limitations in linear Factor Augmented Vector Autoregressive (FAVAR) models for forecasting and structural analysis. Nonlinear dimension techniques, particularly autoencoders, have emerged as promising alternatives in a FAVAR framework, but challenges remain in identifiability, interpretability, and integration with traditional nonlinear time series methods. We address these challenges through two contributions. First, we introduce a Grouped Sparse autoencoder that employs the Spike-and-Slab Lasso prior, with parameters under this prior being shared across variables of the same economic category, thereby achieving semi-identifiability and enhancing model interpretability. Second, we incorporate time-varying parameters into the VAR component to better capture evolving economic dynamics. Our empirical application to the US economy demonstrates that the Grouped Sparse autoencoder produces more interpretable factors through its parsimonious structure; and its combination with time-varying parameter VAR shows superior performance in both point and density forecasting. Impulse response analysis reveals that monetary policy shocks during recessions generate more moderate responses with higher uncertainty compared to expansionary periods.
Effects of Random Edge-Dropping on Over-Squashing in Graph Neural Networks
Feb 11, 2025



Message Passing Neural Networks (MPNNs) are a class of Graph Neural Networks (GNNs) that leverage the graph topology to propagate messages across increasingly larger neighborhoods. The message-passing scheme leads to two distinct challenges: over-smoothing and over-squashing. While several algorithms, e.g. DropEdge and its variants -- DropNode, DropAgg and DropGNN -- have successfully addressed the over-smoothing problem, their impact on over-squashing remains largely unexplored. This represents a critical gap in the literature as failure to mitigate over-squashing would make these methods unsuitable for long-range tasks. In this work, we take the first step towards closing this gap by studying the aforementioned algorithms in the context of over-squashing. We present novel theoretical results that characterize the negative effects of DropEdge on sensitivity between distant nodes, suggesting its unsuitability for long-range tasks. Our findings are easily extended to its variants, allowing us to build a comprehensive understanding of how they affect over-squashing. We evaluate these methods using real-world datasets, demonstrating their detrimental effects. Specifically, we show that while DropEdge-variants improve test-time performance in short range tasks, they deteriorate performance in long-range ones. Our theory explains these results as follows: random edge-dropping lowers the effective receptive field of GNNs, which although beneficial for short-range tasks, misaligns the models on long-range ones. This forces the models to overfit to short-range artefacts in the training set, resulting in poor generalization. Our conclusions highlight the need to re-evaluate various methods designed for training deep GNNs, with a renewed focus on modelling long-range interactions.
Right Now, Wrong Then: Non-Stationary Direct Preference Optimization under Preference Drift
Jul 26, 2024



Reinforcement learning from human feedback (RLHF) aligns Large Language Models (LLMs) with human preferences. However, these preferences can often change over time due to external factors (e.g. environment change and societal influence). Consequently, what was wrong then might be right now. Current preference optimization algorithms do not account for temporal preference drift in their modeling, which can lead to severe misalignment. To address this limitation, we use a Dynamic Bradley-Terry model that models preferences via time-dependent reward functions, and propose Non-Stationary Direct Preference Optimisation (NS-DPO). By introducing a discount parameter in the loss function, NS-DPO applies exponential weighting, which proportionally focuses learning on more time-relevant datapoints. We theoretically analyse the convergence of NS-DPO in the offline setting, providing upper bounds on the estimation error caused by non-stationary preferences. Finally, we demonstrate the effectiveness of NS-DPO1 for fine-tuning LLMs in scenarios with drifting preferences. By simulating preference drift using renowned reward models and modifying popular LLM datasets accordingly, we show that NS-DPO fine-tuned LLMs remain robust under non-stationarity, significantly outperforming baseline algorithms that ignore temporal preference changes, without sacrificing performance in stationary cases.
AsEP: Benchmarking Deep Learning Methods for Antibody-specific Epitope Prediction
Jul 25, 2024Epitope identification is vital for antibody design yet challenging due to the inherent variability in antibodies. While many deep learning methods have been developed for general protein binding site prediction tasks, whether they work for epitope prediction remains an understudied research question. The challenge is also heightened by the lack of a consistent evaluation pipeline with sufficient dataset size and epitope diversity. We introduce a filtered antibody-antigen complex structure dataset, AsEP (Antibody-specific Epitope Prediction). AsEP is the largest of its kind and provides clustered epitope groups, allowing the community to develop and test novel epitope prediction methods. AsEP comes with an easy-to-use interface in Python and pre-built graph representations of each antibody-antigen complex while also supporting customizable embedding methods. Based on this new dataset, we benchmarked various representative general protein-binding site prediction methods and find that their performances are not satisfactory as expected for epitope prediction. We thus propose a new method, WALLE, that leverages both protein language models and graph neural networks. WALLE demonstrate about 5X performance gain over existing methods. Our empirical findings evidence that epitope prediction benefits from combining sequential embeddings provided by language models and geometrical information from graph representations, providing a guideline for future method design. In addition, we reformulate the task as bipartite link prediction, allowing easy model performance attribution and interpretability. We open-source our data and code at https://github.com/biochunan/AsEP-dataset.
Analyzing the Generalization and Reliability of Steering Vectors -- ICML 2024
Jul 17, 2024Steering vectors (SVs) are a new approach to efficiently adjust language model behaviour at inference time by intervening on intermediate model activations. They have shown promise in terms of improving both capabilities and model alignment. However, the reliability and generalisation properties of this approach are unknown. In this work, we rigorously investigate these properties, and show that steering vectors have substantial limitations both in- and out-of-distribution. In-distribution, steerability is highly variable across different inputs. Depending on the concept, spurious biases can substantially contribute to how effective steering is for each input, presenting a challenge for the widespread use of steering vectors. Out-of-distribution, while steering vectors often generalise well, for several concepts they are brittle to reasonable changes in the prompt, resulting in them failing to generalise well. Overall, our findings show that while steering can work well in the right circumstances, there remain many technical difficulties of applying steering vectors to guide models' behaviour at scale.
Generative Active Learning for the Search of Small-molecule Protein Binders
May 02, 2024



Despite substantial progress in machine learning for scientific discovery in recent years, truly de novo design of small molecules which exhibit a property of interest remains a significant challenge. We introduce LambdaZero, a generative active learning approach to search for synthesizable molecules. Powered by deep reinforcement learning, LambdaZero learns to search over the vast space of molecules to discover candidates with a desired property. We apply LambdaZero with molecular docking to design novel small molecules that inhibit the enzyme soluble Epoxide Hydrolase 2 (sEH), while enforcing constraints on synthesizability and drug-likeliness. LambdaZero provides an exponential speedup in terms of the number of calls to the expensive molecular docking oracle, and LambdaZero de novo designed molecules reach docking scores that would otherwise require the virtual screening of a hundred billion molecules. Importantly, LambdaZero discovers novel scaffolds of synthesizable, drug-like inhibitors for sEH. In in vitro experimental validation, a series of ligands from a generated quinazoline-based scaffold were synthesized, and the lead inhibitor N-(4,6-di(pyrrolidin-1-yl)quinazolin-2-yl)-N-methylbenzamide (UM0152893) displayed sub-micromolar enzyme inhibition of sEH.
Can a Confident Prior Replace a Cold Posterior?
Mar 02, 2024Benchmark datasets used for image classification tend to have very low levels of label noise. When Bayesian neural networks are trained on these datasets, they often underfit, misrepresenting the aleatoric uncertainty of the data. A common solution is to cool the posterior, which improves fit to the training data but is challenging to interpret from a Bayesian perspective. We explore whether posterior tempering can be replaced by a confidence-inducing prior distribution. First, we introduce a "DirClip" prior that is practical to sample and nearly matches the performance of a cold posterior. Second, we introduce a "confidence prior" that directly approximates a cold likelihood in the limit of decreasing temperature but cannot be easily sampled. Lastly, we provide several general insights into confidence-inducing priors, such as when they might diverge and how fine-tuning can mitigate numerical instability.
Diffusive Gibbs Sampling
Feb 05, 2024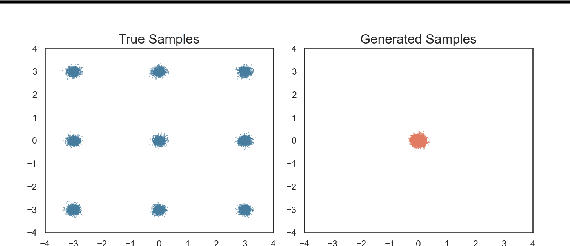
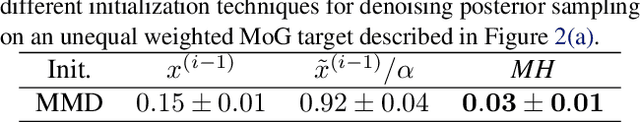
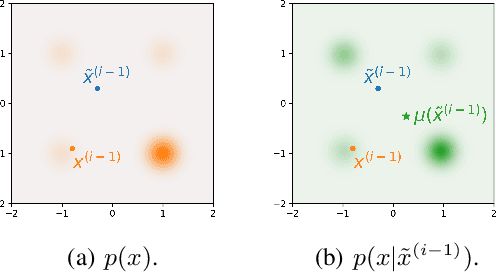

The inadequate mixing of conventional Markov Chain Monte Carlo (MCMC) methods for multi-modal distributions presents a significant challenge in practical applications such as Bayesian inference and molecular dynamics. Addressing this, we propose Diffusive Gibbs Sampling (DiGS), an innovative family of sampling methods designed for effective sampling from distributions characterized by distant and disconnected modes. DiGS integrates recent developments in diffusion models, leveraging Gaussian convolution to create an auxiliary noisy distribution that bridges isolated modes in the original space and applying Gibbs sampling to alternately draw samples from both spaces. Our approach exhibits a better mixing property for sampling multi-modal distributions than state-of-the-art methods such as parallel tempering. We demonstrate that our sampler attains substantially improved results across various tasks, including mixtures of Gaussians, Bayesian neural networks and molecular dynamics.
Gaussian Processes on Cellular Complexes
Nov 02, 2023In recent years, there has been considerable interest in developing machine learning models on graphs in order to account for topological inductive biases. In particular, recent attention was given to Gaussian processes on such structures since they can additionally account for uncertainty. However, graphs are limited to modelling relations between two vertices. In this paper, we go beyond this dyadic setting and consider polyadic relations that include interactions between vertices, edges and one of their generalisations, known as cells. Specifically, we propose Gaussian processes on cellular complexes, a generalisation of graphs that captures interactions between these higher-order cells. One of our key contributions is the derivation of two novel kernels, one that generalises the graph Mat\'ern kernel and one that additionally mixes information of different cell types.