 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOverton Pluralistic Reinforcement Learning for Large Language Models
Feb 24, 2026Existing alignment paradigms remain limited in capturing the pluralistic nature of human values. Overton Pluralism addresses this gap by generating responses with diverse perspectives from a single query. This paper introduces OP-GRPO (Overton Pluralistic Group Relative Policy Optimization), a reinforcement learning framework for implicit Overton Pluralism that enables a single large language model to produce pluralistic responses without explicit prompting or modular orchestration. Our workflow consists of two main steps. First, similarity estimator training fine-tunes a Sentence Transformer for Overton Pluralism tasks to provide more accurate coverage evaluation of generated responses. Second, OP-GRPO training incorporates this similarity estimator into a dual-reward system designed to ensure both broad coverage of genuine human perspectives and the uniqueness of each perspective, thereby promoting diversity. Empirical results demonstrate a "small models, big perspective coverage" effect. The trained Qwen2.5-3B-Instruct model surpasses a 20B GPT-OSS baseline with a 37.4 percent relative accuracy gain on a Natural Language Inference benchmark, and also outperforms a modular architecture baseline with a 19.1 percent relative improvement. Additional evaluations using GPT-4.1 as a large language model judge further confirm the robustness of the approach.
Robust Multi-Objective Controlled Decoding of Large Language Models
Mar 11, 2025
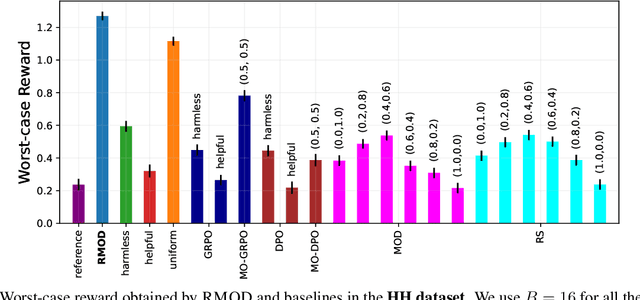
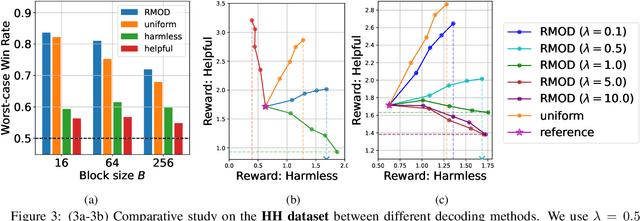
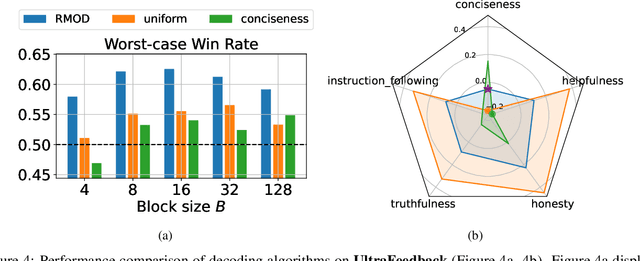
Test-time alignment of Large Language Models (LLMs) to human preferences offers a flexible way to generate responses aligned to diverse objectives without extensive retraining of LLMs. Existing methods achieve alignment to multiple objectives simultaneously (e.g., instruction-following, helpfulness, conciseness) by optimizing their corresponding reward functions. However, they often rely on predefined weights or optimize for averages, sacrificing one objective for another and leading to unbalanced outcomes. To address this, we introduce Robust Multi-Objective Decoding (RMOD), a novel inference-time algorithm that optimizes for improving worst-case rewards. RMOD formalizes the robust decoding problem as a maximin two-player game between reward weights and the sampling policy, solving for the Nash equilibrium. We show that the game reduces to a convex optimization problem to find the worst-case weights, while the best response policy can be computed analytically. We also introduce a practical RMOD variant designed for efficient decoding with contemporary LLMs, incurring minimal computational overhead compared to non-robust Multi-Objective Decoding (MOD) methods. Our experimental results showcase the effectiveness of RMOD in generating responses equitably aligned with diverse objectives, outperforming baselines up to 20%.
Right Now, Wrong Then: Non-Stationary Direct Preference Optimization under Preference Drift
Jul 26, 2024



Reinforcement learning from human feedback (RLHF) aligns Large Language Models (LLMs) with human preferences. However, these preferences can often change over time due to external factors (e.g. environment change and societal influence). Consequently, what was wrong then might be right now. Current preference optimization algorithms do not account for temporal preference drift in their modeling, which can lead to severe misalignment. To address this limitation, we use a Dynamic Bradley-Terry model that models preferences via time-dependent reward functions, and propose Non-Stationary Direct Preference Optimisation (NS-DPO). By introducing a discount parameter in the loss function, NS-DPO applies exponential weighting, which proportionally focuses learning on more time-relevant datapoints. We theoretically analyse the convergence of NS-DPO in the offline setting, providing upper bounds on the estimation error caused by non-stationary preferences. Finally, we demonstrate the effectiveness of NS-DPO1 for fine-tuning LLMs in scenarios with drifting preferences. By simulating preference drift using renowned reward models and modifying popular LLM datasets accordingly, we show that NS-DPO fine-tuned LLMs remain robust under non-stationarity, significantly outperforming baseline algorithms that ignore temporal preference changes, without sacrificing performance in stationary cases.
Creating Pro-Level AI for Real-Time Fighting Game with Deep Reinforcement Learning
Apr 08, 2019
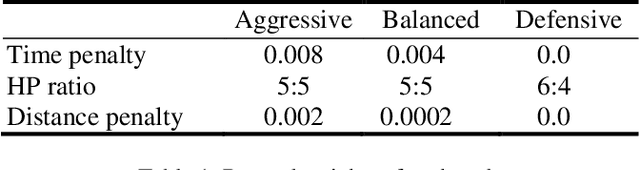
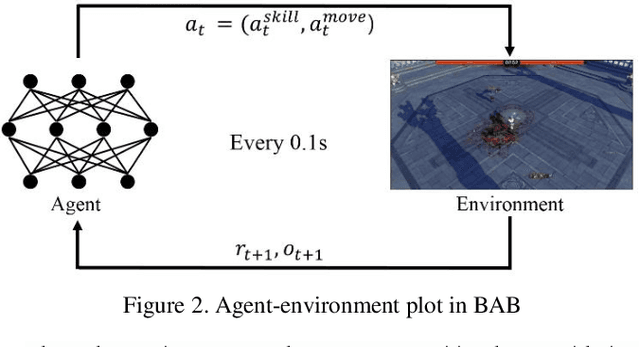

Reinforcement learning combined with deep neural networks has performed remarkably well in many genres of game recently. It surpassed human-level performance in fixed game environments and turn-based two player board games. However, no research has ever shown a result that surpassed human level in modern complex fighting games, to the best of our knowledge. This is due to the inherent difficulties of modern fighting games, including vast action spaces, real-time constraints, and performance generalizations required for various opponents. We overcame these challenges and made 1v1 battle AI agents for the commercial game, "Blade & Soul". The trained agents competed against five professional gamers and achieved 62% of win rate.This paper presents a practical reinforcement learning method including a novel self-play curriculum and data skipping techniques. Through the curriculum, three different styles of agents are created by reward shaping, and are trained against each other for robust performance. Additionally, this paper suggests data skipping techniques which increased data efficiency and facilitated explorations in vast spaces.