 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCreating Pro-Level AI for Real-Time Fighting Game with Deep Reinforcement Learning
Apr 08, 2019
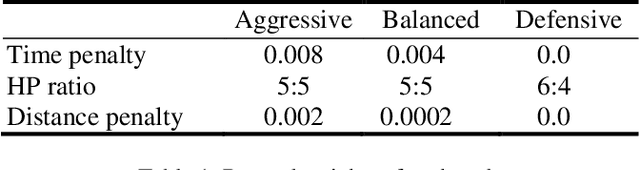
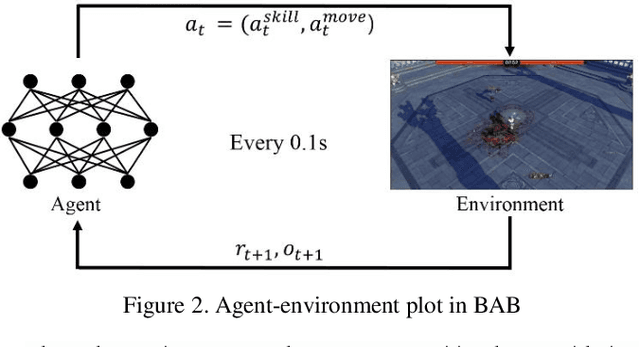

Reinforcement learning combined with deep neural networks has performed remarkably well in many genres of game recently. It surpassed human-level performance in fixed game environments and turn-based two player board games. However, no research has ever shown a result that surpassed human level in modern complex fighting games, to the best of our knowledge. This is due to the inherent difficulties of modern fighting games, including vast action spaces, real-time constraints, and performance generalizations required for various opponents. We overcame these challenges and made 1v1 battle AI agents for the commercial game, "Blade & Soul". The trained agents competed against five professional gamers and achieved 62% of win rate.This paper presents a practical reinforcement learning method including a novel self-play curriculum and data skipping techniques. Through the curriculum, three different styles of agents are created by reward shaping, and are trained against each other for robust performance. Additionally, this paper suggests data skipping techniques which increased data efficiency and facilitated explorations in vast spaces.