 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGDSD: Reinforcement Learning as Guided Denoiser Self-Distillation for Diffusion Language Models
May 28, 2026Reinforcement learning (RL) can be used to improve the policy (denoiser) of diffusion large language models (dLLMs), while being hindered by the intractability of the policy likelihood. A dominant and efficient family of methods replaces the likelihood in standard RL with its evidence lower bound (ELBO), estimated from randomly masked sequences. Despite being well aligned with pre-training, these approaches introduce bias through training--inference mismatch by using the ELBO as a likelihood surrogate, which can degrade performance. In this work, we propose Guided Denoiser Self-Distillation (GDSD) to directly distill the denoiser of dLLMs from an advantage-guided self-teacher, derived from the closed-form optimum of reverse-KL regularized RL. GDSD matches the dLLM's denoiser logits to the teacher's via a normalization-free objective, which reduces RL to likelihood-free self-distillation and thus bypasses the TIM biases. Recent ELBO-based methods emerge as instances of applying different distillation divergences, but with diagnosable pathologies that GDSD avoids. On planning, math, and coding benchmarks with LLaDA-8B and Dream-7B, GDSD consistently outperforms prior state-of-the-art ELBO-based methods with a more stable training reward dynamics, achieving test-accuracy improvements of up to $+19.6\%$. These results suggest that direct denoiser self-distillation, without relying on an ELBO likelihood surrogate, can provide a more stable and effective RL procedure for dLLMs. Code is available at https://github.com/GaryBall/GDSD.
On-Policy Adversarial Flow Distillation for Autoregressive Video Generation
May 25, 2026Autoregressive video generators are attractive for streaming, long-horizon, and interactive applications, but distilling strong black-box teachers into causal students remains difficult. The student must learn under its own rollout distribution, whereas practical teachers may expose only prompt-conditioned completed videos and may differ in architecture, capacity, temporal design, and sampling schedule. This interface makes supervised fine-tuning off-policy, score-based distillation inapplicable, and direct adversarial imitation too sparse for denoising-time credit assignment. We propose Adversarial Flow Distillation (AFD), an on-policy framework for heterogeneous black-box video distillation. AFD queries the teacher and rolls out the current student on the same prompts, trains a prompt-paired Bradley-Terry discriminator to estimate clean-sample teacher-student discrepancy, and converts the resulting on-policy advantage into forward-process flow-matching updates on the student's own noised states. Thus, AFD provides dense velocity-field supervision while requiring no teacher scores, latents, denoising trajectories, step alignment, or reverse-chain reinforcement learning. Experiments across two causal AR student families show that AFD consistently improves motion- and physics-sensitive generation while preserving general video quality, and ablations validate the importance of adaptive on-policy feedback and forward-process credit assignment. The method requires only clean teacher videos and student rollouts, providing a practical route for distilling proprietary or heterogeneous video generators into efficient autoregressive students.
LLM-WikiRace: Benchmarking Long-term Planning and Reasoning over Real-World Knowledge Graphs
Feb 18, 2026We introduce LLM-Wikirace, a benchmark for evaluating planning, reasoning, and world knowledge in large language models (LLMs). In LLM-Wikirace, models must efficiently navigate Wikipedia hyperlinks step by step to reach a target page from a given source, requiring look-ahead planning and the ability to reason about how concepts are connected in the real world. We evaluate a broad set of open- and closed-source models, including Gemini-3, GPT-5, and Claude Opus 4.5, which achieve the strongest results on the easy level of the task and demonstrate superhuman performance. Despite this, performance drops sharply on hard difficulty: the best-performing model, Gemini-3, succeeds in only 23\% of hard games, highlighting substantial remaining challenges for frontier models. Our analysis shows that world knowledge is a necessary ingredient for success, but only up to a point, beyond this threshold, planning and long-horizon reasoning capabilities become the dominant factors. Trajectory-level analysis further reveals that even the strongest models struggle to replan after failure, frequently entering loops rather than recovering. LLM-Wikirace is a simple benchmark that reveals clear limitations in current reasoning systems, offering an open arena where planning-capable LLMs still have much to prove. Our code and leaderboard available at https:/llmwikirace.github.io.
Robust Multi-Objective Controlled Decoding of Large Language Models
Mar 11, 2025
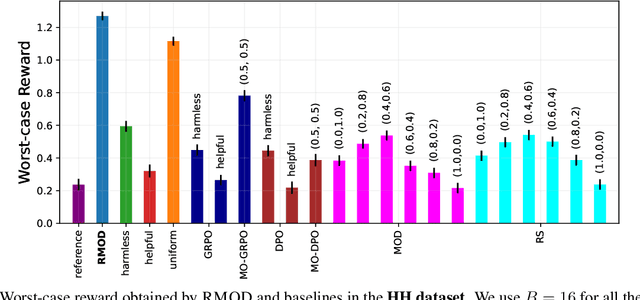
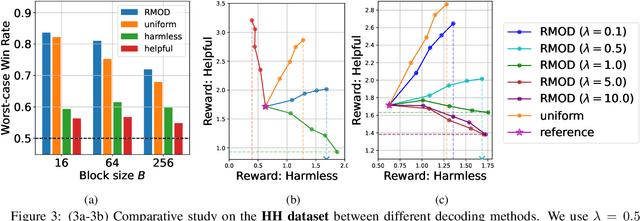
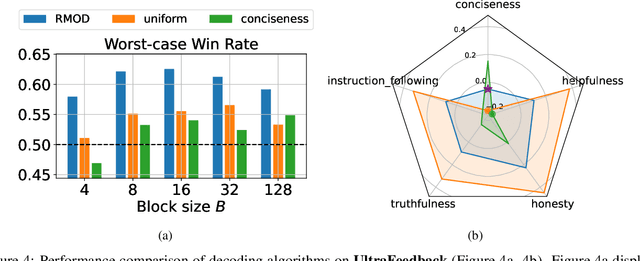
Test-time alignment of Large Language Models (LLMs) to human preferences offers a flexible way to generate responses aligned to diverse objectives without extensive retraining of LLMs. Existing methods achieve alignment to multiple objectives simultaneously (e.g., instruction-following, helpfulness, conciseness) by optimizing their corresponding reward functions. However, they often rely on predefined weights or optimize for averages, sacrificing one objective for another and leading to unbalanced outcomes. To address this, we introduce Robust Multi-Objective Decoding (RMOD), a novel inference-time algorithm that optimizes for improving worst-case rewards. RMOD formalizes the robust decoding problem as a maximin two-player game between reward weights and the sampling policy, solving for the Nash equilibrium. We show that the game reduces to a convex optimization problem to find the worst-case weights, while the best response policy can be computed analytically. We also introduce a practical RMOD variant designed for efficient decoding with contemporary LLMs, incurring minimal computational overhead compared to non-robust Multi-Objective Decoding (MOD) methods. Our experimental results showcase the effectiveness of RMOD in generating responses equitably aligned with diverse objectives, outperforming baselines up to 20%.
Adversarial Robust Decision Transformer: Enhancing Robustness of RvS via Minimax Returns-to-go
Jul 25, 2024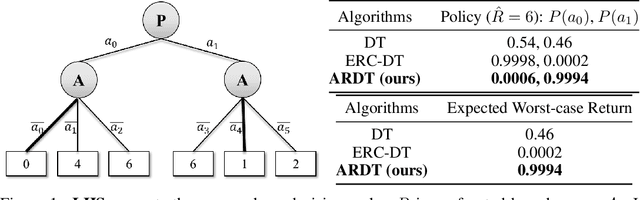

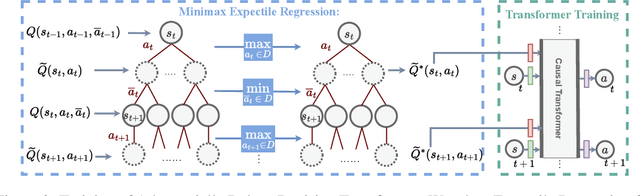
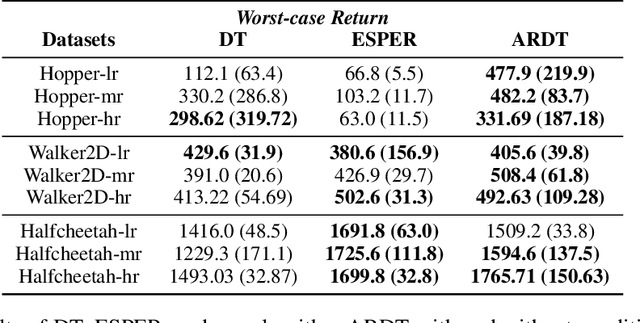
Decision Transformer (DT), as one of the representative Reinforcement Learning via Supervised Learning (RvS) methods, has achieved strong performance in offline learning tasks by leveraging the powerful Transformer architecture for sequential decision-making. However, in adversarial environments, these methods can be non-robust, since the return is dependent on the strategies of both the decision-maker and adversary. Training a probabilistic model conditioned on observed return to predict action can fail to generalize, as the trajectories that achieve a return in the dataset might have done so due to a weak and suboptimal behavior adversary. To address this, we propose a worst-case-aware RvS algorithm, the Adversarial Robust Decision Transformer (ARDT), which learns and conditions the policy on in-sample minimax returns-to-go. ARDT aligns the target return with the worst-case return learned through minimax expectile regression, thereby enhancing robustness against powerful test-time adversaries. In experiments conducted on sequential games with full data coverage, ARDT can generate a maximin (Nash Equilibrium) strategy, the solution with the largest adversarial robustness. In large-scale sequential games and continuous adversarial RL environments with partial data coverage, ARDT demonstrates significantly superior robustness to powerful test-time adversaries and attains higher worst-case returns compared to contemporary DT methods.
Can Word Sense Distribution Detect Semantic Changes of Words?
Oct 16, 2023
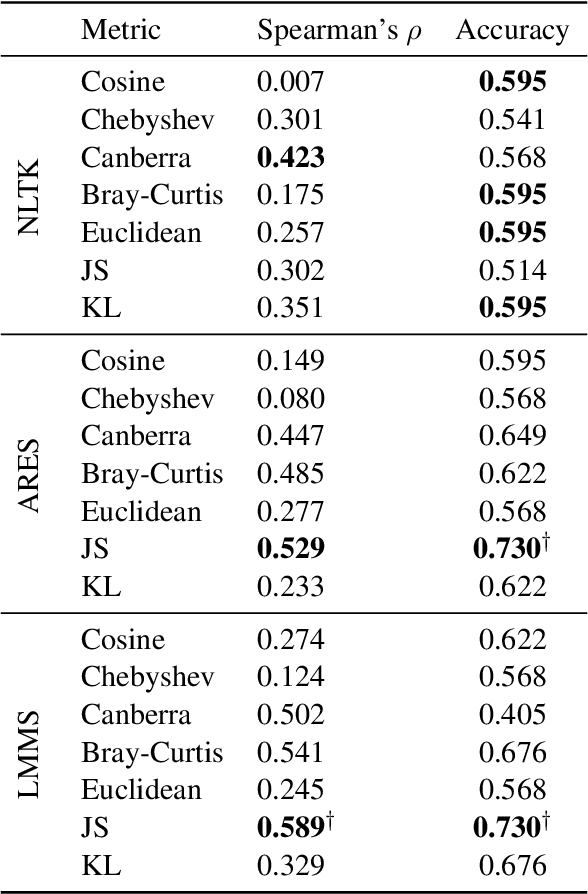
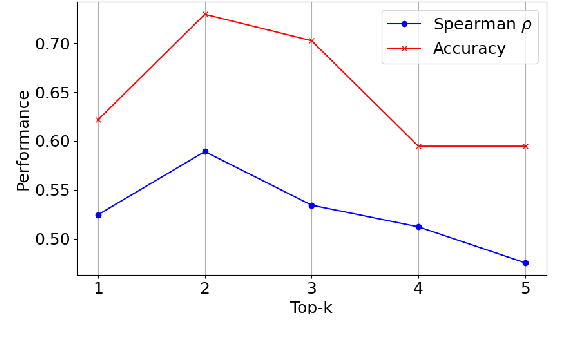
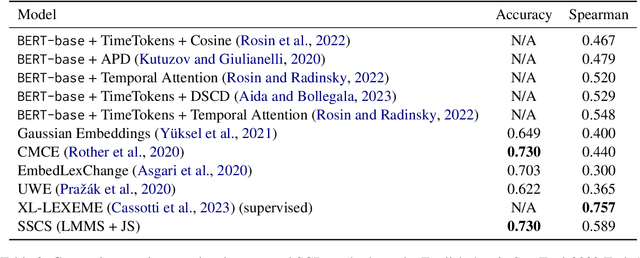
Semantic Change Detection (SCD) of words is an important task for various NLP applications that must make time-sensitive predictions. Some words are used over time in novel ways to express new meanings, and these new meanings establish themselves as novel senses of existing words. On the other hand, Word Sense Disambiguation (WSD) methods associate ambiguous words with sense ids, depending on the context in which they occur. Given this relationship between WSD and SCD, we explore the possibility of predicting whether a target word has its meaning changed between two corpora collected at different time steps, by comparing the distributions of senses of that word in each corpora. For this purpose, we use pretrained static sense embeddings to automatically annotate each occurrence of the target word in a corpus with a sense id. Next, we compute the distribution of sense ids of a target word in a given corpus. Finally, we use different divergence or distance measures to quantify the semantic change of the target word across the two given corpora. Our experimental results on SemEval 2020 Task 1 dataset show that word sense distributions can be accurately used to predict semantic changes of words in English, German, Swedish and Latin.
* Accepted to Findings of EMNLP 2023
Learning Dynamic Contextualised Word Embeddings via Template-based Temporal Adaptation
Aug 23, 2022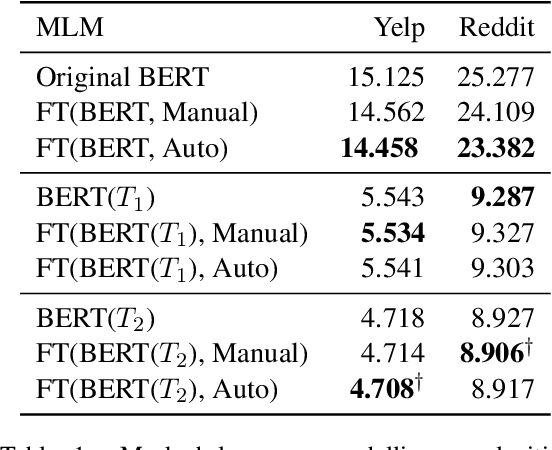

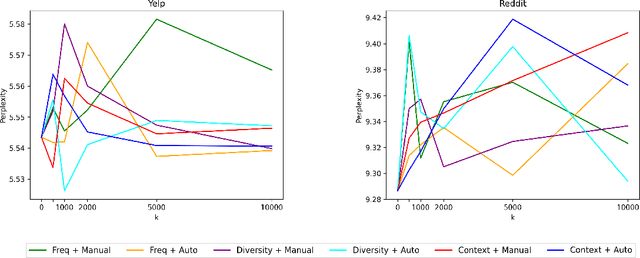
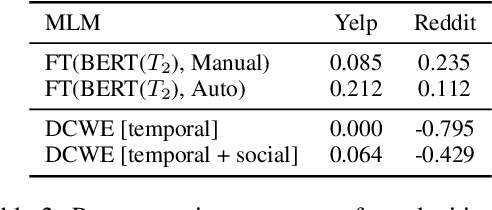
Dynamic contextualised word embeddings represent the temporal semantic variations of words. We propose a method for learning dynamic contextualised word embeddings by time-adapting a pretrained Masked Language Model (MLM) using time-sensitive templates. Given two snapshots $C_1$ and $C_2$ of a corpora taken respectively at two distinct timestamps $T_1$ and $T_2$, we first propose an unsupervised method to select (a) pivot terms related to both $C_1$ and $C_2$, and (b) anchor terms that are associated with a specific pivot term in each individual snapshot. We then generate prompts by filling manually compiled templates using the extracted pivot and anchor terms. Moreover, we propose an automatic method to learn time-sensitive templates from $C_1$ and $C_2$, without requiring any human supervision. Next, we use the generated prompts to adapt a pretrained MLM to $T_2$ by fine-tuning it on the prompts. Experimental results show that our proposed method significantly reduces the perplexity of test sentences selected from $T_2$, thereby outperforming the current state-of-the-art dynamic contextualised word embedding methods.
Average-Reward Reinforcement Learning with Trust Region Methods
Jun 07, 2021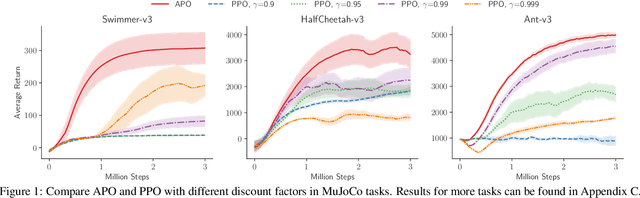
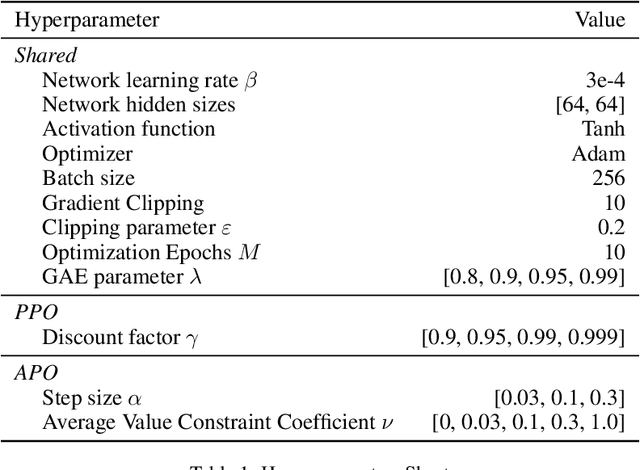
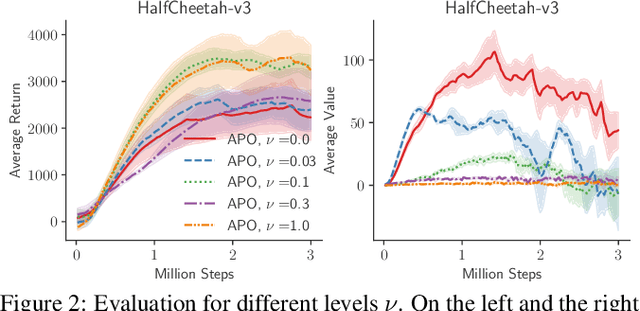
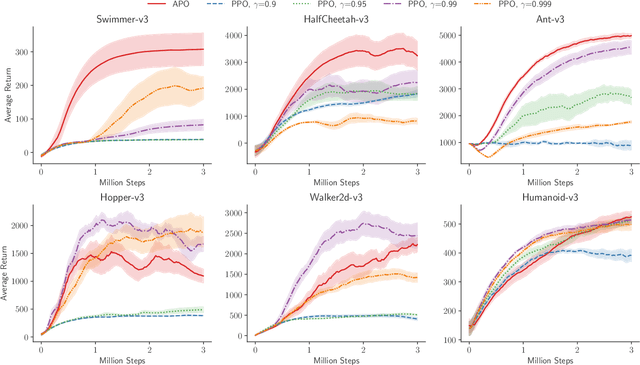
Most of reinforcement learning algorithms optimize the discounted criterion which is beneficial to accelerate the convergence and reduce the variance of estimates. Although the discounted criterion is appropriate for certain tasks such as financial related problems, many engineering problems treat future rewards equally and prefer a long-run average criterion. In this paper, we study the reinforcement learning problem with the long-run average criterion. Firstly, we develop a unified trust region theory with discounted and average criteria. With the average criterion, a novel performance bound within the trust region is derived with the Perturbation Analysis (PA) theory. Secondly, we propose a practical algorithm named Average Policy Optimization (APO), which improves the value estimation with a novel technique named Average Value Constraint. To the best of our knowledge, our work is the first one to study the trust region approach with the average criterion and it complements the framework of reinforcement learning beyond the discounted criterion. Finally, experiments are conducted in the continuous control environment MuJoCo. In most tasks, APO performs better than the discounted PPO, which demonstrates the effectiveness of our approach.