 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDissecting Bias in LLMs: A Mechanistic Interpretability Perspective
Jun 06, 2025Large Language Models (LLMs) are known to exhibit social, demographic, and gender biases, often as a consequence of the data on which they are trained. In this work, we adopt a mechanistic interpretability approach to analyze how such biases are structurally represented within models such as GPT-2 and Llama2. Focusing on demographic and gender biases, we explore different metrics to identify the internal edges responsible for biased behavior. We then assess the stability, localization, and generalizability of these components across dataset and linguistic variations. Through systematic ablations, we demonstrate that bias-related computations are highly localized, often concentrated in a small subset of layers. Moreover, the identified components change across fine-tuning settings, including those unrelated to bias. Finally, we show that removing these components not only reduces biased outputs but also affects other NLP tasks, such as named entity recognition and linguistic acceptability judgment because of the sharing of important components with these tasks.
A Counterfactual Explanation Framework for Retrieval Models
Sep 01, 2024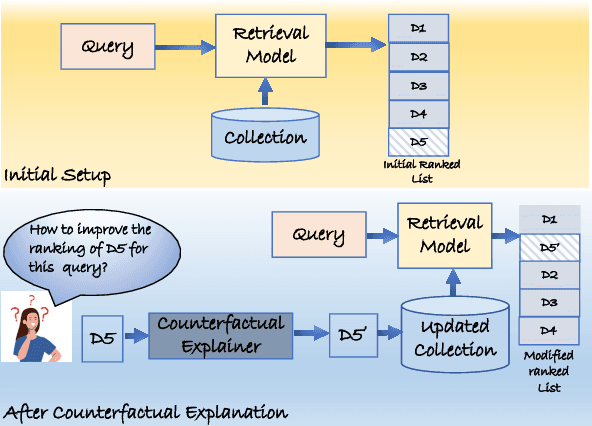

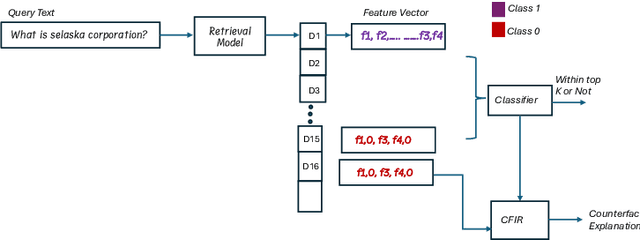

Explainability has become a crucial concern in today's world, aiming to enhance transparency in machine learning and deep learning models. Information retrieval is no exception to this trend. In existing literature on explainability of information retrieval, the emphasis has predominantly been on illustrating the concept of relevance concerning a retrieval model. The questions addressed include why a document is relevant to a query, why one document exhibits higher relevance than another, or why a specific set of documents is deemed relevant for a query. However, limited attention has been given to understanding why a particular document is considered non-relevant to a query with respect to a retrieval model. In an effort to address this gap, our work focus on the question of what terms need to be added within a document to improve its ranking. This in turn answers the question of which words played a role in not being favored by a retrieval model for a particular query. We use an optimization framework to solve the above-mentioned research problem. % To the best of our knowledge, we mark the first attempt to tackle this specific counterfactual problem. Our experiments show the effectiveness of our proposed approach in predicting counterfactuals for both statistical (e.g. BM25) and deep-learning-based models (e.g. DRMM, DSSM, ColBERT).
Adaptive Retrieval-Augmented Generation for Conversational Systems
Jul 31, 2024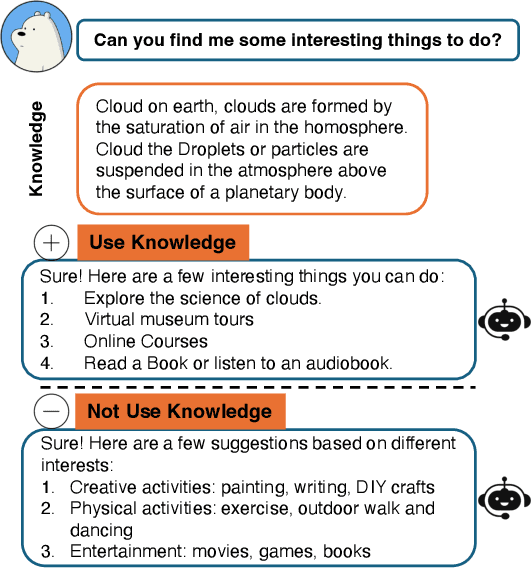



Despite the success of integrating large language models into the development of conversational systems, many studies have shown the effectiveness of retrieving and augmenting external knowledge for informative responses. Hence, many existing studies commonly assume the always need for Retrieval Augmented Generation (RAG) in a conversational system without explicit control. This raises a research question about such a necessity. In this study, we propose to investigate the need for each turn of system response to be augmented with external knowledge. In particular, by leveraging human judgements on the binary choice of adaptive augmentation, we develop RAGate, a gating model, which models conversation context and relevant inputs to predict if a conversational system requires RAG for improved responses. We conduct extensive experiments on devising and applying RAGate to conversational models and well-rounded analyses of different conversational scenarios. Our experimental results and analysis indicate the effective application of RAGate in RAG-based conversational systems in identifying system responses for appropriate RAG with high-quality responses and a high generation confidence. This study also identifies the correlation between the generation's confidence level and the relevance of the augmented knowledge.
Automated Attribute Extraction from Legal Proceedings
Oct 18, 2023


The escalating number of pending cases is a growing concern world-wide. Recent advancements in digitization have opened up possibilities for leveraging artificial intelligence (AI) tools in the processing of legal documents. Adopting a structured representation for legal documents, as opposed to a mere bag-of-words flat text representation, can significantly enhance processing capabilities. With the aim of achieving this objective, we put forward a set of diverse attributes for criminal case proceedings. We use a state-of-the-art sequence labeling framework to automatically extract attributes from the legal documents. Moreover, we demonstrate the efficacy of the extracted attributes in a downstream task, namely legal judgment prediction.
Can Word Sense Distribution Detect Semantic Changes of Words?
Oct 16, 2023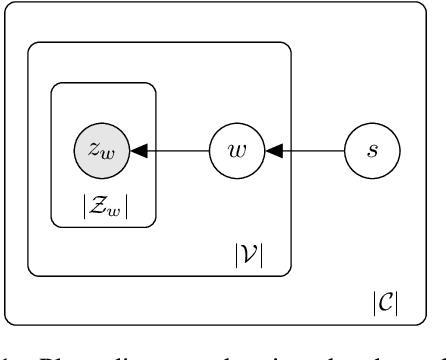
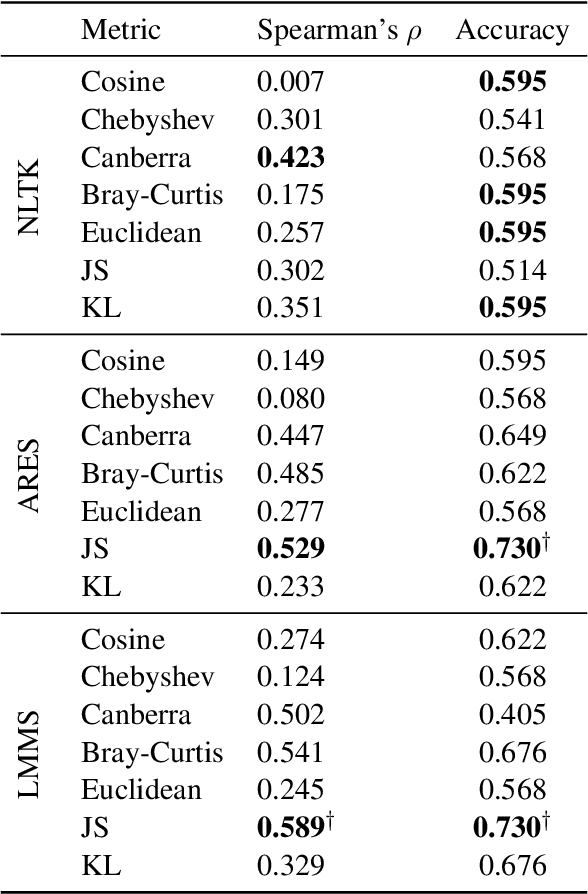
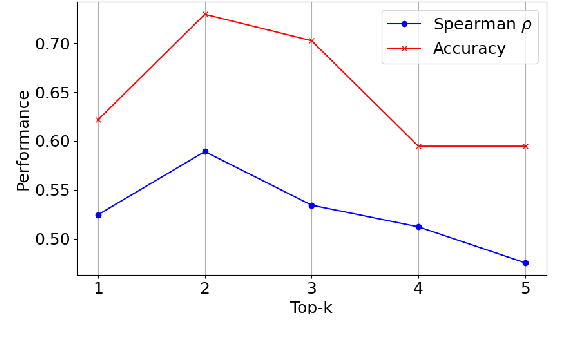
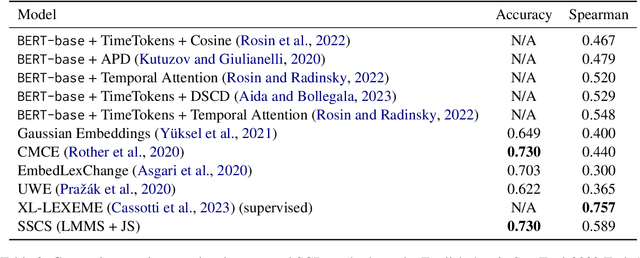
Semantic Change Detection (SCD) of words is an important task for various NLP applications that must make time-sensitive predictions. Some words are used over time in novel ways to express new meanings, and these new meanings establish themselves as novel senses of existing words. On the other hand, Word Sense Disambiguation (WSD) methods associate ambiguous words with sense ids, depending on the context in which they occur. Given this relationship between WSD and SCD, we explore the possibility of predicting whether a target word has its meaning changed between two corpora collected at different time steps, by comparing the distributions of senses of that word in each corpora. For this purpose, we use pretrained static sense embeddings to automatically annotate each occurrence of the target word in a corpus with a sense id. Next, we compute the distribution of sense ids of a target word in a given corpus. Finally, we use different divergence or distance measures to quantify the semantic change of the target word across the two given corpora. Our experimental results on SemEval 2020 Task 1 dataset show that word sense distributions can be accurately used to predict semantic changes of words in English, German, Swedish and Latin.
* Accepted to Findings of EMNLP 2023
Lexical Entrainment for Conversational Systems
Oct 14, 2023Conversational agents have become ubiquitous in assisting with daily tasks, and are expected to possess human-like features. One such feature is lexical entrainment (LE), a phenomenon in which speakers in human-human conversations tend to naturally and subconsciously align their lexical choices with those of their interlocutors, leading to more successful and engaging conversations. As an example, if a digital assistant replies 'Your appointment for Jinling Noodle Pub is at 7 pm' to the question 'When is my reservation for Jinling Noodle Bar today?', it may feel as though the assistant is trying to correct the speaker, whereas a response of 'Your reservation for Jinling Noodle Bar is at 7 pm' would likely be perceived as more positive. This highlights the importance of LE in establishing a shared terminology for maximum clarity and reducing ambiguity in conversations. However, we demonstrate in this work that current response generation models do not adequately address this crucial humanlike phenomenon. To address this, we propose a new dataset, named MULTIWOZ-ENTR, and a measure for LE for conversational systems. Additionally, we suggest a way to explicitly integrate LE into conversational systems with two new tasks, a LE extraction task and a LE generation task. We also present two baseline approaches for the LE extraction task, which aim to detect LE expressions from dialogue contexts.
Automated Argument Generation from Legal Facts
Oct 12, 2023

The count of pending cases has shown an exponential rise across nations (e.g., with more than 10 million pending cases in India alone). The main issue lies in the fact that the number of cases submitted to the law system is far greater than the available number of legal professionals present in a country. Given this worldwide context, the utilization of AI technology has gained paramount importance to enhance the efficiency and speed of legal procedures. In this study we partcularly focus on helping legal professionals in the process of analyzing a legal case. Our specific investigation delves into harnessing the generative capabilities of open-sourced large language models to create arguments derived from the facts present in legal cases. Experimental results show that the generated arguments from the best performing method have on average 63% overlap with the benchmark set gold standard annotations.
LIPEx -- Locally Interpretable Probabilistic Explanations -- To Look Beyond The True Class
Oct 07, 2023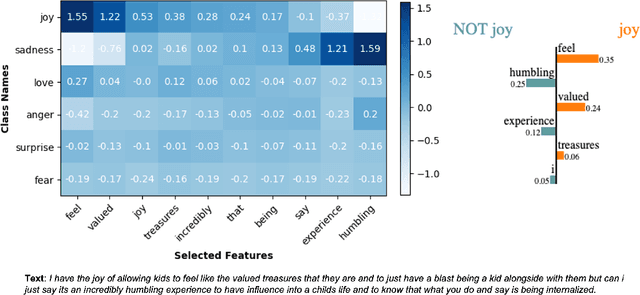
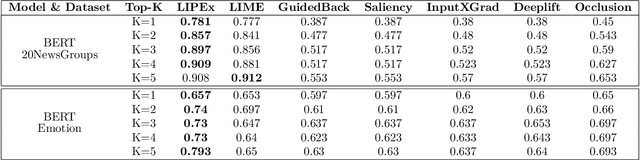
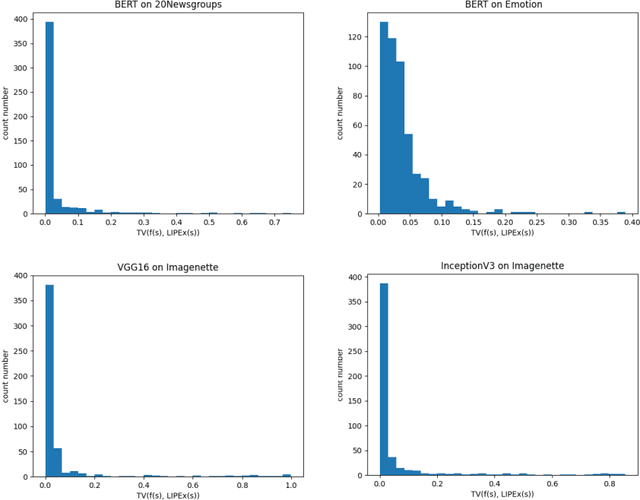

In this work, we instantiate a novel perturbation-based multi-class explanation framework, LIPEx (Locally Interpretable Probabilistic Explanation). We demonstrate that LIPEx not only locally replicates the probability distributions output by the widely used complex classification models but also provides insight into how every feature deemed to be important affects the prediction probability for each of the possible classes. We achieve this by defining the explanation as a matrix obtained via regression with respect to the Hellinger distance in the space of probability distributions. Ablation tests on text and image data, show that LIPEx-guided removal of important features from the data causes more change in predictions for the underlying model than similar tests on other saliency-based or feature importance-based XAI methods. It is also shown that compared to LIME, LIPEx is much more data efficient in terms of the number of perturbations needed for reliable evaluation of the explanation.
Task2KB: A Public Task-Oriented Knowledge Base
Jan 24, 2023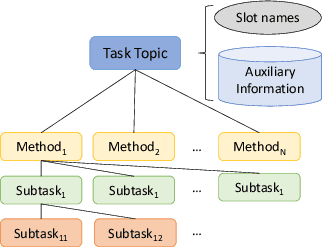
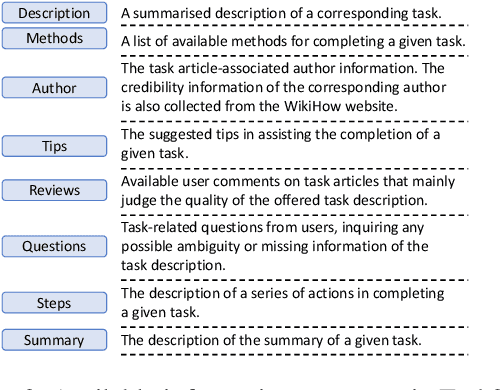
Search engines and conversational assistants are commonly used to help users complete their every day tasks such as booking travel, cooking, etc. While there are some existing datasets that can be used for this purpose, their coverage is limited to very few domains. In this paper, we propose a novel knowledge base, 'Task2KB', which is constructed using data crawled from WikiHow, an online knowledge resource offering instructional articles on a wide range of tasks. Task2KB encapsulates various types of task-related information and attributes, such as requirements, detailed step description, and available methods to complete tasks. Due to its higher coverage compared to existing related knowledge graphs, Task2KB can be highly useful in the development of general purpose task completion assistants
Multi-Objective Few-shot Learning for Fair Classification
Oct 05, 2021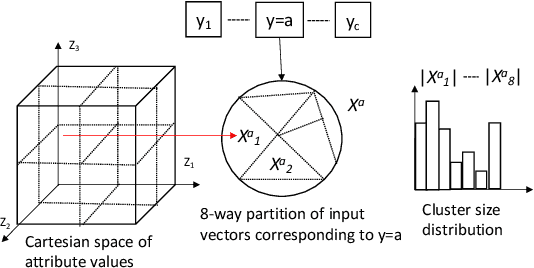
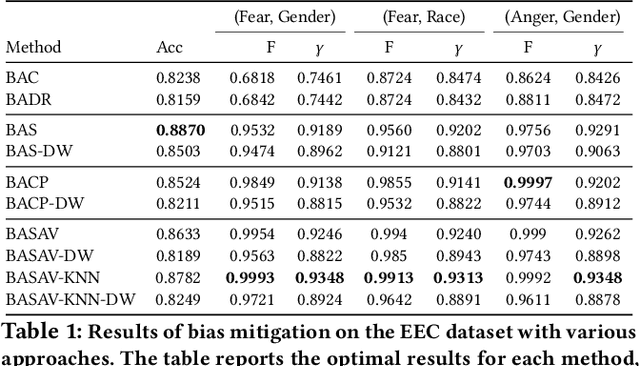
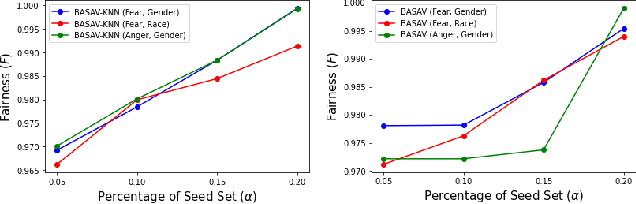
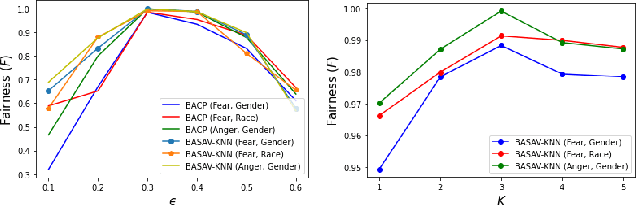
In this paper, we propose a general framework for mitigating the disparities of the predicted classes with respect to secondary attributes within the data (e.g., race, gender etc.). Our proposed method involves learning a multi-objective function that in addition to learning the primary objective of predicting the primary class labels from the data, also employs a clustering-based heuristic to minimize the disparities of the class label distribution with respect to the cluster memberships, with the assumption that each cluster should ideally map to a distinct combination of attribute values. Experiments demonstrate effective mitigation of cognitive biases on a benchmark dataset without the use of annotations of secondary attribute values (the zero-shot case) or with the use of a small number of attribute value annotations (the few-shot case).