 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShadow Removal Refinement via Material-Consistent Shadow Edges
Sep 10, 2024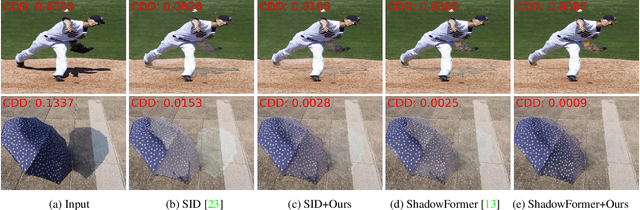
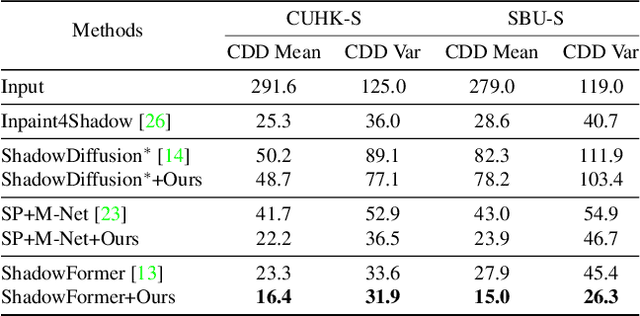
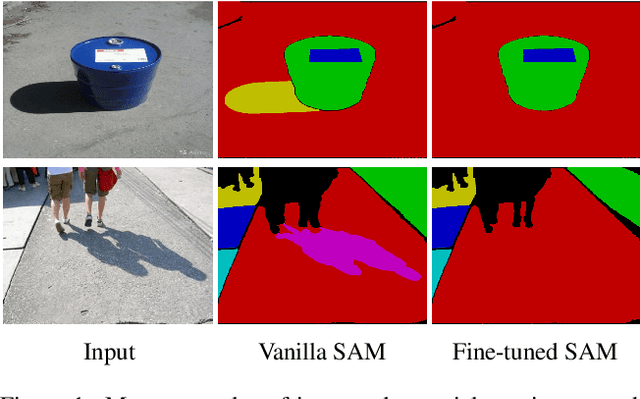

Shadow boundaries can be confused with material boundaries as both exhibit sharp changes in luminance or contrast within a scene. However, shadows do not modify the intrinsic color or texture of surfaces. Therefore, on both sides of shadow edges traversing regions with the same material, the original color and textures should be the same if the shadow is removed properly. These shadow/shadow-free pairs are very useful but hard-to-collect supervision signals. The crucial contribution of this paper is to learn how to identify those shadow edges that traverse material-consistent regions and how to use them as self-supervision for shadow removal refinement during test time. To achieve this, we fine-tune SAM, an image segmentation foundation model, to produce a shadow-invariant segmentation and then extract material-consistent shadow edges by comparing the SAM segmentation with the shadow mask. Utilizing these shadow edges, we introduce color and texture-consistency losses to enhance the shadow removal process. We demonstrate the effectiveness of our method in improving shadow removal results on more challenging, in-the-wild images, outperforming the state-of-the-art shadow removal methods. Additionally, we propose a new metric and an annotated dataset for evaluating the performance of shadow removal methods without the need for paired shadow/shadow-free data.
Automated Attribute Extraction from Legal Proceedings
Oct 18, 2023


The escalating number of pending cases is a growing concern world-wide. Recent advancements in digitization have opened up possibilities for leveraging artificial intelligence (AI) tools in the processing of legal documents. Adopting a structured representation for legal documents, as opposed to a mere bag-of-words flat text representation, can significantly enhance processing capabilities. With the aim of achieving this objective, we put forward a set of diverse attributes for criminal case proceedings. We use a state-of-the-art sequence labeling framework to automatically extract attributes from the legal documents. Moreover, we demonstrate the efficacy of the extracted attributes in a downstream task, namely legal judgment prediction.
Intrinsic Decomposition of Document Images In-the-Wild
Nov 29, 2020
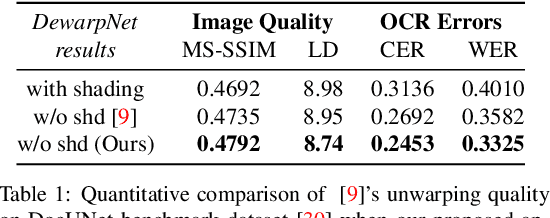

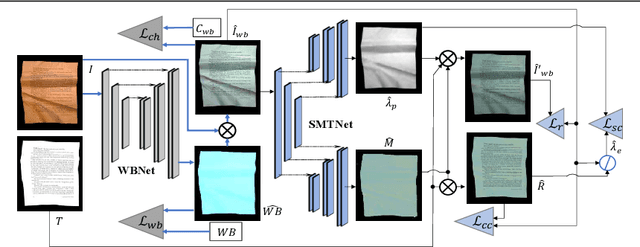
Automatic document content processing is affected by artifacts caused by the shape of the paper, non-uniform and diverse color of lighting conditions. Fully-supervised methods on real data are impossible due to the large amount of data needed. Hence, the current state of the art deep learning models are trained on fully or partially synthetic images. However, document shadow or shading removal results still suffer because: (a) prior methods rely on uniformity of local color statistics, which limit their application on real-scenarios with complex document shapes and textures and; (b) synthetic or hybrid datasets with non-realistic, simulated lighting conditions are used to train the models. In this paper we tackle these problems with our two main contributions. First, a physically constrained learning-based method that directly estimates document reflectance based on intrinsic image formation which generalizes to challenging illumination conditions. Second, a new dataset that clearly improves previous synthetic ones, by adding a large range of realistic shading and diverse multi-illuminant conditions, uniquely customized to deal with documents in-the-wild. The proposed architecture works in a self-supervised manner where only the synthetic texture is used as a weak training signal (obviating the need for very costly ground truth with disentangled versions of shading and reflectance). The proposed approach leads to a significant generalization of document reflectance estimation in real scenes with challenging illumination. We extensively evaluate on the real benchmark datasets available for intrinsic image decomposition and document shadow removal tasks. Our reflectance estimation scheme, when used as a pre-processing step of an OCR pipeline, shows a 26% improvement of character error rate (CER), thus, proving the practical applicability.