 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Focus: CSI-Free Hierarchical MARL for Reconfigurable Reflectors
Apr 06, 2026Reconfigurable Intelligent Surfaces (RIS) has a potential to engineer smart radio environments for next-generation millimeter-wave (mmWave) networks. However, the prohibitive computational overhead of Channel State Information (CSI) estimation and the dimensionality explosion inherent in centralized optimization severely hinder practical large-scale deployments. To overcome these bottlenecks, we introduce a ``CSI-free" paradigm powered by a Hierarchical Multi-Agent Reinforcement Learning (HMARL) architecture to control mechanically reconfigurable reflective surfaces. By substituting pilot-based channel estimation with accessible user localization data, our framework leverages spatial intelligence for macro-scale wave propagation management. The control problem is decomposed into a two-tier neural architecture: a high-level controller executes temporally extended, discrete user-to-reflector allocations, while low-level controllers autonomously optimize continuous focal points utilizing Multi-Agent Proximal Policy Optimization (MAPPO) under a Centralized Training with Decentralized Execution (CTDE) scheme. Comprehensive deterministic ray-tracing evaluations demonstrate that this hierarchical framework achieves massive RSSI improvements of up to 7.79 dB over centralized baselines. Furthermore, the system exhibits robust multi-user scalability and maintains highly resilient beam-focusing performance under practical sub-meter localization tracking errors. By eliminating CSI overhead while maintaining high-fidelity signal redirection, this work establishes a scalable and cost-effective blueprint for intelligent wireless environments.
Bypassing the CSI Bottleneck: MARL-Driven Spatial Control for Reflector Arrays
Apr 06, 2026Reconfigurable Intelligent Surfaces (RIS) are pivotal for next-generation smart radio environments, yet their practical deployment is severely bottlenecked by the intractable computational overhead of Channel State Information (CSI) estimation. To bypass this fundamental physical-layer barrier, we propose an AI-native, data-driven paradigm that replaces complex channel modeling with spatial intelligence. This paper presents a fully autonomous Multi-Agent Reinforcement Learning (MARL) framework to control mechanically adjustable metallic reflector arrays. By mapping high-dimensional mechanical constraints to a reduced-order virtual focal point space, we deploy a Centralized Training with Decentralized Execution (CTDE) architecture. Using Multi-Agent Proximal Policy Optimization (MAPPO), our decentralized agents learn cooperative beam-focusing strategies relying on user coordinates, achieving CSI-free operation. High-fidelity ray-tracing simulations in dynamic non-line-of-sight (NLOS) environments demonstrate that this multi-agent approach rapidly adapts to user mobility, yielding up to a 26.86 dB enhancement over static flat reflectors and outperforming single-agent and hardware-constrained DRL baselines in both spatial selectivity and temporal stability. Crucially, the learned policies exhibit good deployment resilience, sustaining stable signal coverage even under 1.0-meter localization noise. These results validate the efficacy of MARL-driven spatial abstractions as a scalable, highly practical pathway toward AI-empowered wireless networks.
Automated Counting of Stacked Objects in Industrial Inspection
Mar 16, 2026Visual object counting is a fundamental computer vision task in industrial inspection, where accurate, high-throughput inventory tracking and quality assurance are critical. Moreover, manufactured parts are often too light to reliably deduce their count from their weight, or too heavy to move the stack on a scale safely and practically, making automated visual counting the more robust solution in many scenarios. However, existing methods struggle with stacked 3D items in containers, pallets, or bins, where most objects are heavily occluded and only a few are directly visible. To address this important yet underexplored challenge, we propose a novel 3D counting approach that decomposes the task into two complementary subproblems: estimating the 3D geometry of the stack and its occupancy ratio from multi-view images. By combining geometric reconstruction with deep learning-based depth analysis, our method can accurately count identical manufactured parts inside containers, even when they are irregularly stacked and partially hidden. We validate our 3D counting pipeline on large-scale synthetic and diverse real-world data with manually verified total counts, demonstrating robust performance under realistic inspection conditions.
LoRIF: Low-Rank Influence Functions for Scalable Training Data Attribution
Jan 29, 2026Training data attribution (TDA) identifies which training examples most influenced a model's prediction. The best-performing TDA methods exploits gradients to define an influence function. To overcome the scalability challenge arising from gradient computation, the most popular strategy is random projection (e.g., TRAK, LoGRA). However, this still faces two bottlenecks when scaling to large training sets and high-quality attribution: \emph{(i)} storing and loading projected per-example gradients for all $N$ training examples, where query latency is dominated by I/O; and \emph{(ii)} forming the $D \times D$ inverse Hessian approximation, which costs $O(D^2)$ memory. Both bottlenecks scale with the projection dimension $D$, yet increasing $D$ is necessary for attribution quality -- creating a quality-scalability tradeoff. We introduce \textbf{LoRIF (Low-Rank Influence Functions)}, which exploits low-rank structures of gradient to address both bottlenecks. First, we store rank-$c$ factors of the projected per-example gradients rather than full matrices, reducing storage and query-time I/O from $O(D)$ to $O(c\sqrt{D})$ per layer per sample. Second, we use truncated SVD with the Woodbury identity to approximate the Hessian term in an $r$-dimensional subspace, reducing memory from $O(D^2)$ to $O(Dr)$. On models from 0.1B to 70B parameters trained on datasets with millions of examples, LoRIF achieves up to 20$\times$ storage reduction and query-time speedup compared to LoGRA, while matching or exceeding its attribution quality. LoRIF makes gradient-based TDA practical at frontier scale.
Learning to Weight Parameters for Data Attribution
Jun 06, 2025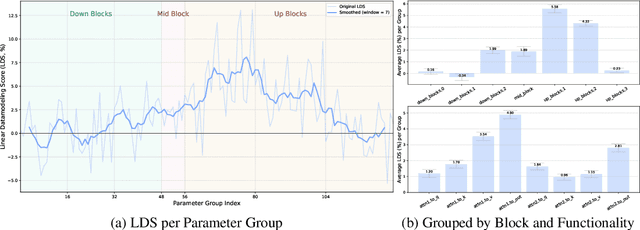

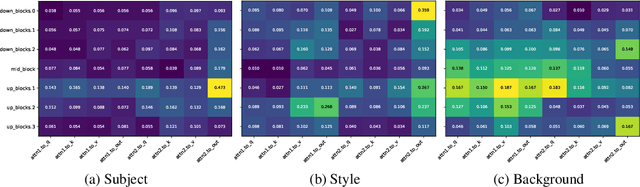
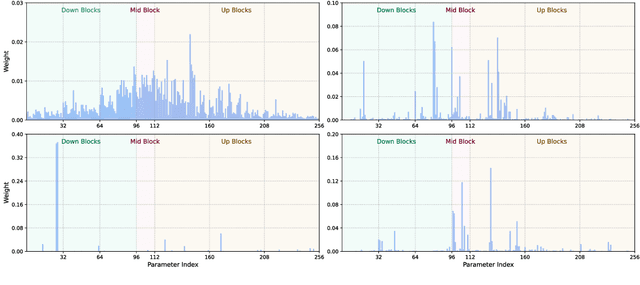
We study data attribution in generative models, aiming to identify which training examples most influence a given output. Existing methods achieve this by tracing gradients back to training data. However, they typically treat all network parameters uniformly, ignoring the fact that different layers encode different types of information and may thus draw information differently from the training set. We propose a method that models this by learning parameter importance weights tailored for attribution, without requiring labeled data. This allows the attribution process to adapt to the structure of the model, capturing which training examples contribute to specific semantic aspects of an output, such as subject, style, or background. Our method improves attribution accuracy across diffusion models and enables fine-grained insights into how outputs borrow from training data.
Improving Contrastive Learning for Referring Expression Counting
May 28, 2025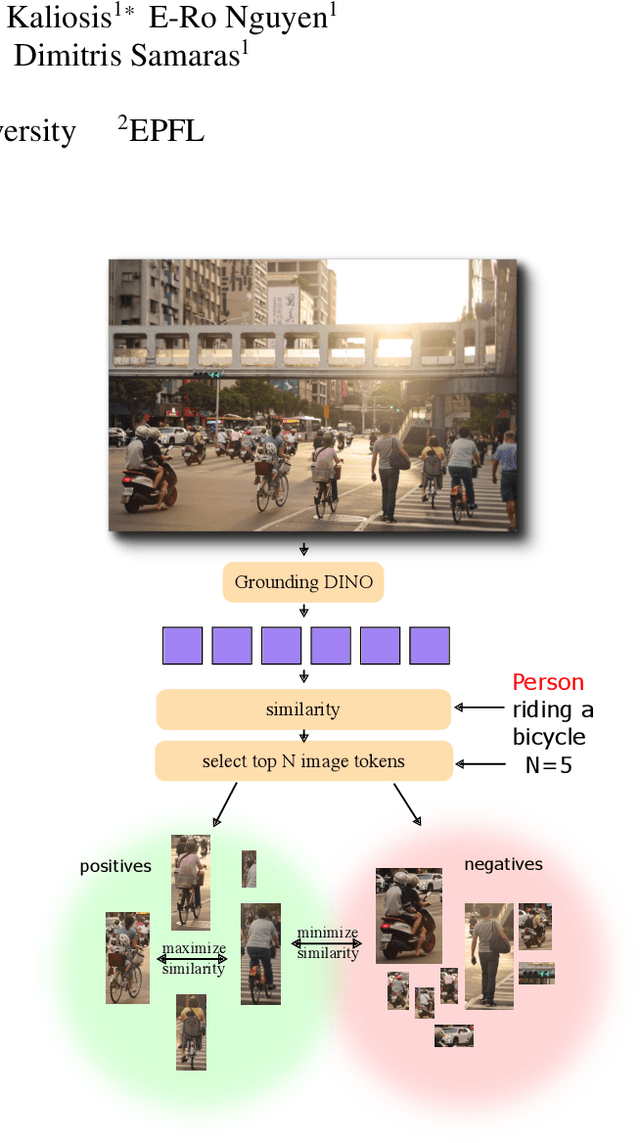
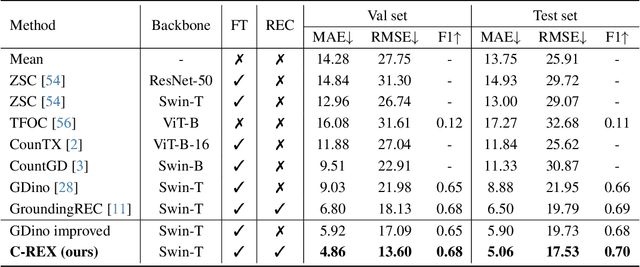

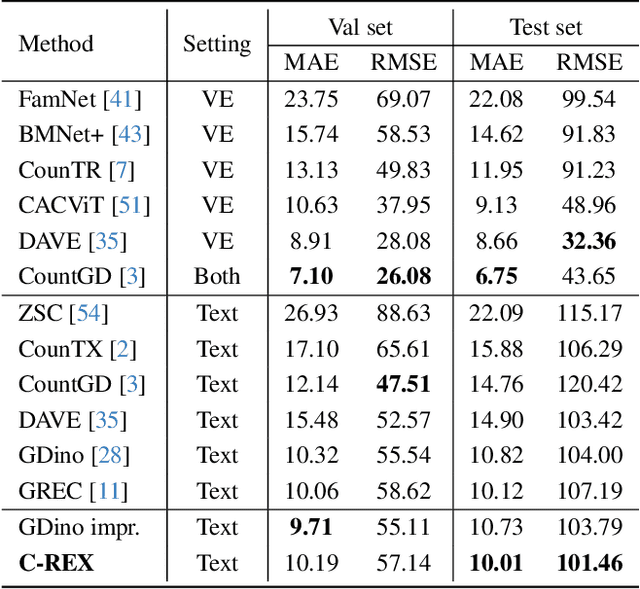
Object counting has progressed from class-specific models, which count only known categories, to class-agnostic models that generalize to unseen categories. The next challenge is Referring Expression Counting (REC), where the goal is to count objects based on fine-grained attributes and contextual differences. Existing methods struggle with distinguishing visually similar objects that belong to the same category but correspond to different referring expressions. To address this, we propose C-REX, a novel contrastive learning framework, based on supervised contrastive learning, designed to enhance discriminative representation learning. Unlike prior works, C-REX operates entirely within the image space, avoiding the misalignment issues of image-text contrastive learning, thus providing a more stable contrastive signal. It also guarantees a significantly larger pool of negative samples, leading to improved robustness in the learned representations. Moreover, we showcase that our framework is versatile and generic enough to be applied to other similar tasks like class-agnostic counting. To support our approach, we analyze the key components of sota detection-based models and identify that detecting object centroids instead of bounding boxes is the key common factor behind their success in counting tasks. We use this insight to design a simple yet effective detection-based baseline to build upon. Our experiments show that C-REX achieves state-of-the-art results in REC, outperforming previous methods by more than 22\% in MAE and more than 10\% in RMSE, while also demonstrating strong performance in class-agnostic counting. Code is available at https://github.com/cvlab-stonybrook/c-rex.
Few-shot Personalized Scanpath Prediction
Apr 07, 2025A personalized model for scanpath prediction provides insights into the visual preferences and attention patterns of individual subjects. However, existing methods for training scanpath prediction models are data-intensive and cannot be effectively personalized to new individuals with only a few available examples. In this paper, we propose few-shot personalized scanpath prediction task (FS-PSP) and a novel method to address it, which aims to predict scanpaths for an unseen subject using minimal support data of that subject's scanpath behavior. The key to our method's adaptability is the Subject-Embedding Network (SE-Net), specifically designed to capture unique, individualized representations for each subject's scanpaths. SE-Net generates subject embeddings that effectively distinguish between subjects while minimizing variability among scanpaths from the same individual. The personalized scanpath prediction model is then conditioned on these subject embeddings to produce accurate, personalized results. Experiments on multiple eye-tracking datasets demonstrate that our method excels in FS-PSP settings and does not require any fine-tuning steps at test time. Code is available at: https://github.com/cvlab-stonybrook/few-shot-scanpath
AutoLike: Auditing Social Media Recommendations through User Interactions
Feb 13, 2025Modern social media platforms, such as TikTok, Facebook, and YouTube, rely on recommendation systems to personalize content for users based on user interactions with endless streams of content, such as "For You" pages. However, these complex algorithms can inadvertently deliver problematic content related to self-harm, mental health, and eating disorders. We introduce AutoLike, a framework to audit recommendation systems in social media platforms for topics of interest and their sentiments. To automate the process, we formulate the problem as a reinforcement learning problem. AutoLike drives the recommendation system to serve a particular type of content through interactions (e.g., liking). We apply the AutoLike framework to the TikTok platform as a case study. We evaluate how well AutoLike identifies TikTok content automatically across nine topics of interest; and conduct eight experiments to demonstrate how well it drives TikTok's recommendation system towards particular topics and sentiments. AutoLike has the potential to assist regulators in auditing recommendation systems for problematic content. (Warning: This paper contains qualitative examples that may be viewed as offensive or harmful.)
Signal Whisperers: Enhancing Wireless Reception Using DRL-Guided Reflector Arrays
Jan 25, 2025



This paper presents a novel approach for enhancing wireless signal reception through self-adjustable metallic surfaces, termed reflectors, which are guided by deep reinforcement learning (DRL). The designed reflector system aims to improve signal quality for multiple users in scenarios where a direct line-of-sight (LOS) from the access point (AP) and reflector to users is not guaranteed. Utilizing DRL techniques, the reflector autonomously modifies its configuration to optimize beam allocation from the AP to user equipment (UE), thereby maximizing path gain. Simulation results indicate substantial improvements in the average path gain for all UEs compared to baseline configurations, highlighting the potential of DRL-driven reflectors in creating adaptive communication environments.
MedTet: An Online Motion Model for 4D Heart Reconstruction
Dec 03, 2024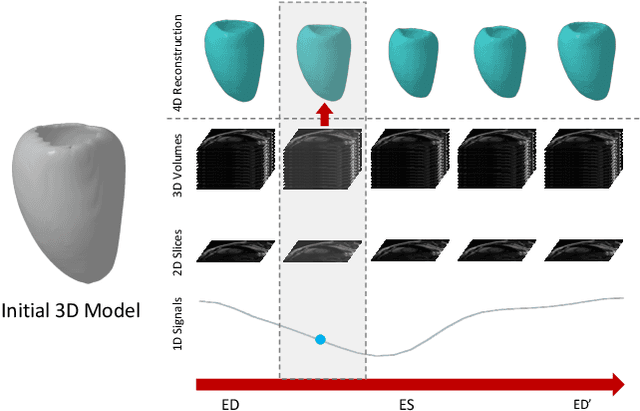
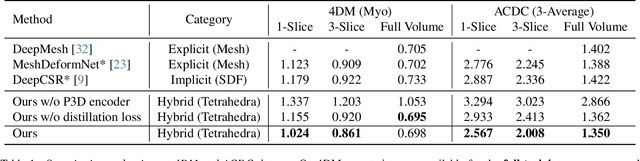
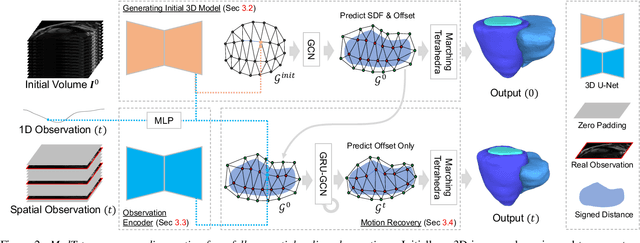
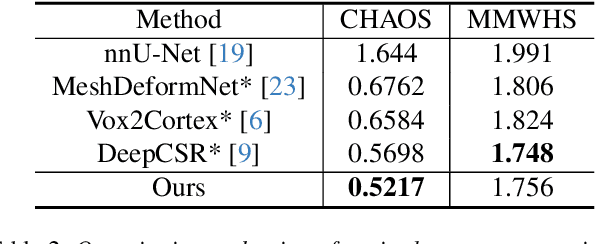
We present a novel approach to reconstruction of 3D cardiac motion from sparse intraoperative data. While existing methods can accurately reconstruct 3D organ geometries from full 3D volumetric imaging, they cannot be used during surgical interventions where usually limited observed data, such as a few 2D frames or 1D signals, is available in real-time. We propose a versatile framework for reconstructing 3D motion from such partial data. It discretizes the 3D space into a deformable tetrahedral grid with signed distance values, providing implicit unlimited resolution while maintaining explicit control over motion dynamics. Given an initial 3D model reconstructed from pre-operative full volumetric data, our system, equipped with an universal observation encoder, can reconstruct coherent 3D cardiac motion from full 3D volumes, a few 2D MRI slices or even 1D signals. Extensive experiments on cardiac intervention scenarios demonstrate our ability to generate plausible and anatomically consistent 3D motion reconstructions from various sparse real-time observations, highlighting its potential for multimodal cardiac imaging. Our code and model will be made available at https://github.com/Scalsol/MedTet.