 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Focus: CSI-Free Hierarchical MARL for Reconfigurable Reflectors
Apr 06, 2026Reconfigurable Intelligent Surfaces (RIS) has a potential to engineer smart radio environments for next-generation millimeter-wave (mmWave) networks. However, the prohibitive computational overhead of Channel State Information (CSI) estimation and the dimensionality explosion inherent in centralized optimization severely hinder practical large-scale deployments. To overcome these bottlenecks, we introduce a ``CSI-free" paradigm powered by a Hierarchical Multi-Agent Reinforcement Learning (HMARL) architecture to control mechanically reconfigurable reflective surfaces. By substituting pilot-based channel estimation with accessible user localization data, our framework leverages spatial intelligence for macro-scale wave propagation management. The control problem is decomposed into a two-tier neural architecture: a high-level controller executes temporally extended, discrete user-to-reflector allocations, while low-level controllers autonomously optimize continuous focal points utilizing Multi-Agent Proximal Policy Optimization (MAPPO) under a Centralized Training with Decentralized Execution (CTDE) scheme. Comprehensive deterministic ray-tracing evaluations demonstrate that this hierarchical framework achieves massive RSSI improvements of up to 7.79 dB over centralized baselines. Furthermore, the system exhibits robust multi-user scalability and maintains highly resilient beam-focusing performance under practical sub-meter localization tracking errors. By eliminating CSI overhead while maintaining high-fidelity signal redirection, this work establishes a scalable and cost-effective blueprint for intelligent wireless environments.
Bypassing the CSI Bottleneck: MARL-Driven Spatial Control for Reflector Arrays
Apr 06, 2026Reconfigurable Intelligent Surfaces (RIS) are pivotal for next-generation smart radio environments, yet their practical deployment is severely bottlenecked by the intractable computational overhead of Channel State Information (CSI) estimation. To bypass this fundamental physical-layer barrier, we propose an AI-native, data-driven paradigm that replaces complex channel modeling with spatial intelligence. This paper presents a fully autonomous Multi-Agent Reinforcement Learning (MARL) framework to control mechanically adjustable metallic reflector arrays. By mapping high-dimensional mechanical constraints to a reduced-order virtual focal point space, we deploy a Centralized Training with Decentralized Execution (CTDE) architecture. Using Multi-Agent Proximal Policy Optimization (MAPPO), our decentralized agents learn cooperative beam-focusing strategies relying on user coordinates, achieving CSI-free operation. High-fidelity ray-tracing simulations in dynamic non-line-of-sight (NLOS) environments demonstrate that this multi-agent approach rapidly adapts to user mobility, yielding up to a 26.86 dB enhancement over static flat reflectors and outperforming single-agent and hardware-constrained DRL baselines in both spatial selectivity and temporal stability. Crucially, the learned policies exhibit good deployment resilience, sustaining stable signal coverage even under 1.0-meter localization noise. These results validate the efficacy of MARL-driven spatial abstractions as a scalable, highly practical pathway toward AI-empowered wireless networks.
Signal Whisperers: Enhancing Wireless Reception Using DRL-Guided Reflector Arrays
Jan 25, 2025



This paper presents a novel approach for enhancing wireless signal reception through self-adjustable metallic surfaces, termed reflectors, which are guided by deep reinforcement learning (DRL). The designed reflector system aims to improve signal quality for multiple users in scenarios where a direct line-of-sight (LOS) from the access point (AP) and reflector to users is not guaranteed. Utilizing DRL techniques, the reflector autonomously modifies its configuration to optimize beam allocation from the AP to user equipment (UE), thereby maximizing path gain. Simulation results indicate substantial improvements in the average path gain for all UEs compared to baseline configurations, highlighting the potential of DRL-driven reflectors in creating adaptive communication environments.
Block Phase Tracking Reference Signal (PTRS) Allocation for DFT-s-OFDM
Jan 20, 2025This study introduces a Block Phase Tracking Reference Signal (PTRS) allocation approach for Discrete Fourier Transform-spread-Orthogonal Frequency Division Multiplexing (DFT-s-OFDM) systems to enhance phase noise tracking and compensation. Our proposed block allocation methodology leverages the concepts of multiresolution time-frequency tiling for more effective sampling, thereby mitigating aliasing effects and improving phase noise resilience. A key contribution of our approach is a novel modulation and demodulation scheme, incorporating a dedicated DFT-s-OFDM symbol, a modulator branch for block PTRS generation, and a dedicated demodulator for accurate phase noise estimation and correction.
Simulation-Based Optimistic Policy Iteration For Multi-Agent MDPs with Kullback-Leibler Control Cost
Oct 19, 2024

This paper proposes an agent-based optimistic policy iteration (OPI) scheme for learning stationary optimal stochastic policies in multi-agent Markov Decision Processes (MDPs), in which agents incur a Kullback-Leibler (KL) divergence cost for their control efforts and an additional cost for the joint state. The proposed scheme consists of a greedy policy improvement step followed by an m-step temporal difference (TD) policy evaluation step. We use the separable structure of the instantaneous cost to show that the policy improvement step follows a Boltzmann distribution that depends on the current value function estimate and the uncontrolled transition probabilities. This allows agents to compute the improved joint policy independently. We show that both the synchronous (entire state space evaluation) and asynchronous (a uniformly sampled set of substates) versions of the OPI scheme with finite policy evaluation rollout converge to the optimal value function and an optimal joint policy asymptotically. Simulation results on a multi-agent MDP with KL control cost variant of the Stag-Hare game validates our scheme's performance in terms of minimizing the cost return.
Guiding Wireless Signals with Arrays of Metallic Linear Fresnel Reflectors: A Low-cost, Frequency-versatile, and Practical Approach
Jul 27, 2024This study presents a novel mechanical metallic reflector array to guide wireless signals to the point of interest, thereby enhancing received signal quality. Comprised of numerous individual units, this device, which acts as a linear Fresnel reflector (LFR), facilitates the reflection of incoming signals to a desired location. Leveraging geometric principles, we present a systematic approach for redirecting beams from an Access Point (AP) toward User Equipment (UE) positions. This methodology is geared towards optimizing beam allocation, thereby maximizing the number of beams directed towards the UE. Ray tracing simulations conducted for two 3D wireless communication scenarios demonstrate significant increases in path gains and received signal strengths (RSS) by at least 50dB with strategically positioned devices.
Propeller Modulation Equalization via Reference Tones
Jul 26, 2024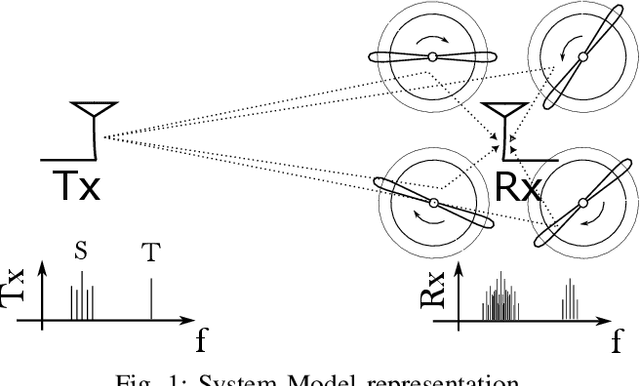
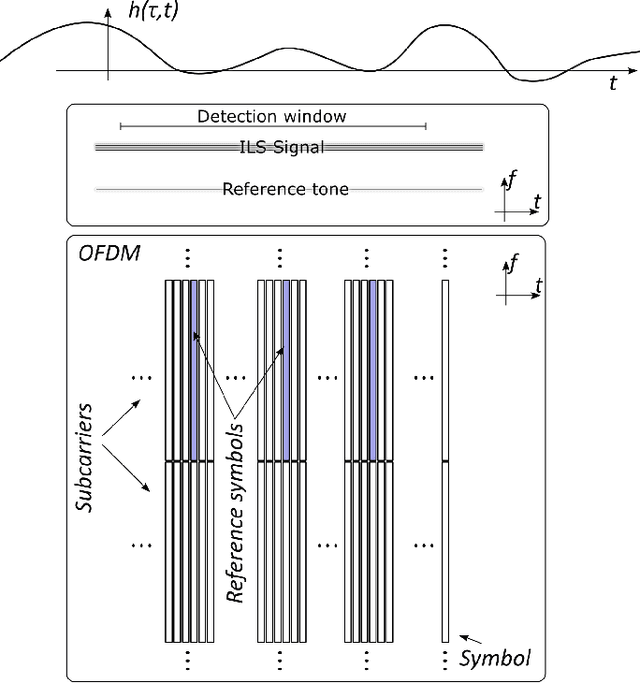
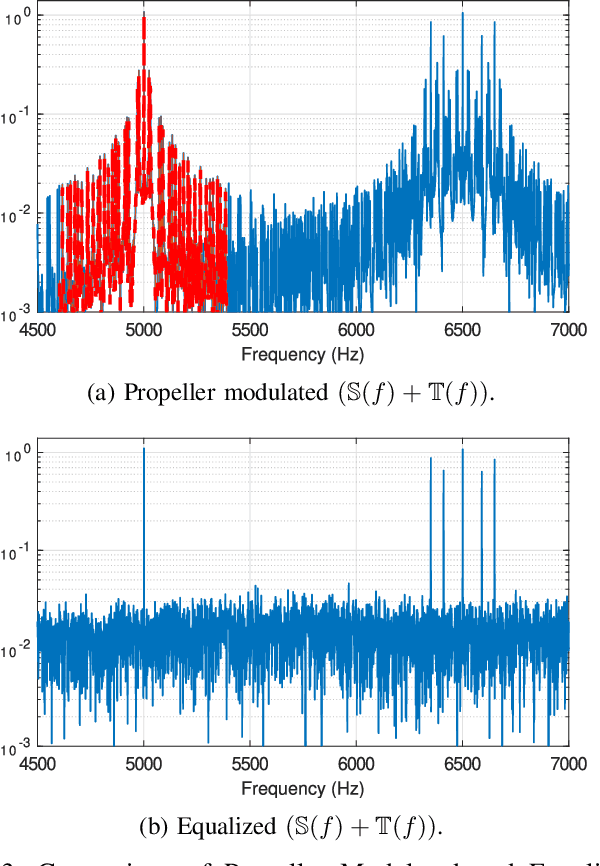
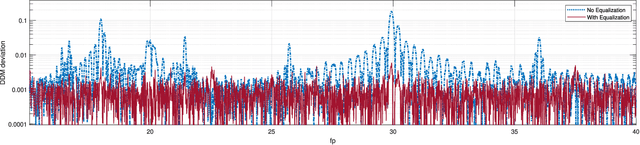
Propeller modulation, also known as micro-Doppler modulation, presents a significant challenge in radio frequency (RF) inspection operations conducted via drones. This paper investigates the equalization of propeller modulation effects on RF signals, specifically targeting applications in navigation aids such as Instrument Landing Systems (ILS). By employing a continuous reference tone, the propeller-induced Doppler spread can be effectively captured and equalized, improving signal integrity and accuracy. Simulation results demonstrate that the proposed equalization method significantly reduces DDM deviation caused by propeller modulation, even under various propeller speeds. The findings suggest that incorporating such equalization techniques can enhance the reliability and efficiency of drone-based RF inspections.
A Perspective on the Impact of Group Delay Dispersion in Future Terahertz Wireless Systems
May 30, 2024This article discusses the challenges and opportunities of managing group delay dispersion (GDD) and its relation to the performance standards of future sixth-generation (6G) wireless communication systems utilizing terahertz frequency waves. The unique susceptibilities of 6G systems to GDD are described, along with a quantitative description of the sources of GDD, including multipath, rough surface scattering, intelligent reflecting surfaces, and propagation through the atmosphere. An experimental case-study is presented that confirms previous models quantifying the impact of atmospheric GDD. Several GDD manipulation strategies are presented illustrating their hindered effectiveness in the 6G context. Conversely, some benefits of leveraging GDD to enhance 6G systems, such as improved security and simplified hardware, are also discussed. Finally, a perspective on using photonic GDD control devices is provided, revealing quantitative benefits that may unburden existing equalization schemes. The article argues that GDD will uniquely and significantly impact some 6G systems, but that its careful consideration along with new mitigation strategies, including photonic devices, will help optimize system performance. The conclusion provides a perspective to guide future research in this area.
Free-Space Optical Channel Turbulence Prediction: A Machine Learning Approach
May 27, 2024



Channel turbulence presents a formidable obstacle for free-space optical (FSO) communication. Anticipation of turbulence levels is highly important for mitigating disruptions. We study the application of machine learning (ML) to FSO data streams to rapidly predict channel turbulence levels with no additional sensing hardware. An optical bit stream was transmitted through a controlled channel in the lab under six distinct turbulence levels, and the efficacy of using ML to classify turbulence levels was examined. ML-based turbulence level classification was found to be >98% accurate with multiple ML training parameters, but highly dependent upon the timescale of changes between turbulence levels.
Large Language Models (LLMs) Assisted Wireless Network Deployment in Urban Settings
May 22, 2024



The advent of Large Language Models (LLMs) has revolutionized language understanding and human-like text generation, drawing interest from many other fields with this question in mind: What else are the LLMs capable of? Despite their widespread adoption, ongoing research continues to explore new ways to integrate LLMs into diverse systems. This paper explores new techniques to harness the power of LLMs for 6G (6th Generation) wireless communication technologies, a domain where automation and intelligent systems are pivotal. The inherent adaptability of LLMs to domain-specific tasks positions them as prime candidates for enhancing wireless systems in the 6G landscape. We introduce a novel Reinforcement Learning (RL) based framework that leverages LLMs for network deployment in wireless communications. Our approach involves training an RL agent, utilizing LLMs as its core, in an urban setting to maximize coverage. The agent's objective is to navigate the complexities of urban environments and identify the network parameters for optimal area coverage. Additionally, we integrate LLMs with Convolutional Neural Networks (CNNs) to capitalize on their strengths while mitigating their limitations. The Deep Deterministic Policy Gradient (DDPG) algorithm is employed for training purposes. The results suggest that LLM-assisted models can outperform CNN-based models in some cases while performing at least as well in others.