 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBypassing the CSI Bottleneck: MARL-Driven Spatial Control for Reflector Arrays
Apr 06, 2026Reconfigurable Intelligent Surfaces (RIS) are pivotal for next-generation smart radio environments, yet their practical deployment is severely bottlenecked by the intractable computational overhead of Channel State Information (CSI) estimation. To bypass this fundamental physical-layer barrier, we propose an AI-native, data-driven paradigm that replaces complex channel modeling with spatial intelligence. This paper presents a fully autonomous Multi-Agent Reinforcement Learning (MARL) framework to control mechanically adjustable metallic reflector arrays. By mapping high-dimensional mechanical constraints to a reduced-order virtual focal point space, we deploy a Centralized Training with Decentralized Execution (CTDE) architecture. Using Multi-Agent Proximal Policy Optimization (MAPPO), our decentralized agents learn cooperative beam-focusing strategies relying on user coordinates, achieving CSI-free operation. High-fidelity ray-tracing simulations in dynamic non-line-of-sight (NLOS) environments demonstrate that this multi-agent approach rapidly adapts to user mobility, yielding up to a 26.86 dB enhancement over static flat reflectors and outperforming single-agent and hardware-constrained DRL baselines in both spatial selectivity and temporal stability. Crucially, the learned policies exhibit good deployment resilience, sustaining stable signal coverage even under 1.0-meter localization noise. These results validate the efficacy of MARL-driven spatial abstractions as a scalable, highly practical pathway toward AI-empowered wireless networks.
Learning to Focus: CSI-Free Hierarchical MARL for Reconfigurable Reflectors
Apr 06, 2026Reconfigurable Intelligent Surfaces (RIS) has a potential to engineer smart radio environments for next-generation millimeter-wave (mmWave) networks. However, the prohibitive computational overhead of Channel State Information (CSI) estimation and the dimensionality explosion inherent in centralized optimization severely hinder practical large-scale deployments. To overcome these bottlenecks, we introduce a ``CSI-free" paradigm powered by a Hierarchical Multi-Agent Reinforcement Learning (HMARL) architecture to control mechanically reconfigurable reflective surfaces. By substituting pilot-based channel estimation with accessible user localization data, our framework leverages spatial intelligence for macro-scale wave propagation management. The control problem is decomposed into a two-tier neural architecture: a high-level controller executes temporally extended, discrete user-to-reflector allocations, while low-level controllers autonomously optimize continuous focal points utilizing Multi-Agent Proximal Policy Optimization (MAPPO) under a Centralized Training with Decentralized Execution (CTDE) scheme. Comprehensive deterministic ray-tracing evaluations demonstrate that this hierarchical framework achieves massive RSSI improvements of up to 7.79 dB over centralized baselines. Furthermore, the system exhibits robust multi-user scalability and maintains highly resilient beam-focusing performance under practical sub-meter localization tracking errors. By eliminating CSI overhead while maintaining high-fidelity signal redirection, this work establishes a scalable and cost-effective blueprint for intelligent wireless environments.
Exploration by Random Distribution Distillation
May 16, 2025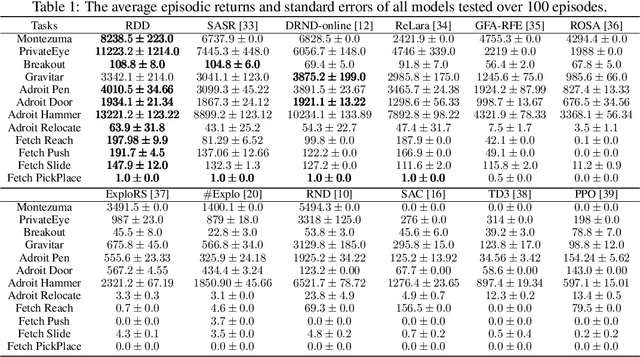
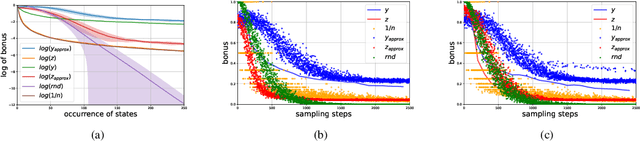
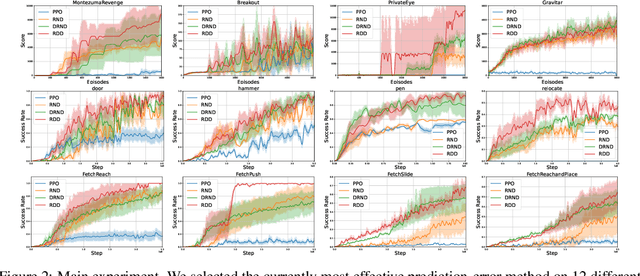
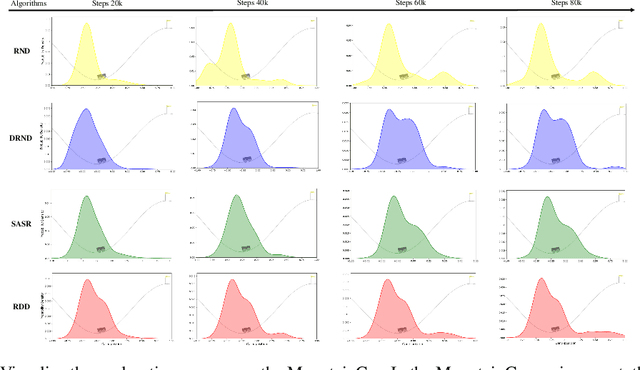
Exploration remains a critical challenge in online reinforcement learning, as an agent must effectively explore unknown environments to achieve high returns. Currently, the main exploration algorithms are primarily count-based methods and curiosity-based methods, with prediction-error methods being a prominent example. In this paper, we propose a novel method called \textbf{R}andom \textbf{D}istribution \textbf{D}istillation (RDD), which samples the output of a target network from a normal distribution. RDD facilitates a more extensive exploration by explicitly treating the difference between the prediction network and the target network as an intrinsic reward. Furthermore, by introducing randomness into the output of the target network for a given state and modeling it as a sample from a normal distribution, intrinsic rewards are bounded by two key components: a pseudo-count term ensuring proper exploration decay and a discrepancy term accounting for predictor convergence. We demonstrate that RDD effectively unifies both count-based and prediction-error approaches. It retains the advantages of prediction-error methods in high-dimensional spaces, while also implementing an intrinsic reward decay mode akin to the pseudo-count method. In the experimental section, RDD is compared with more advanced methods in a series of environments. Both theoretical analysis and experimental results confirm the effectiveness of our approach in improving online exploration for reinforcement learning tasks.
Signal Whisperers: Enhancing Wireless Reception Using DRL-Guided Reflector Arrays
Jan 25, 2025



This paper presents a novel approach for enhancing wireless signal reception through self-adjustable metallic surfaces, termed reflectors, which are guided by deep reinforcement learning (DRL). The designed reflector system aims to improve signal quality for multiple users in scenarios where a direct line-of-sight (LOS) from the access point (AP) and reflector to users is not guaranteed. Utilizing DRL techniques, the reflector autonomously modifies its configuration to optimize beam allocation from the AP to user equipment (UE), thereby maximizing path gain. Simulation results indicate substantial improvements in the average path gain for all UEs compared to baseline configurations, highlighting the potential of DRL-driven reflectors in creating adaptive communication environments.
Novelty-Guided Data Reuse for Efficient and Diversified Multi-Agent Reinforcement Learning
Dec 20, 2024Recently, deep Multi-Agent Reinforcement Learning (MARL) has demonstrated its potential to tackle complex cooperative tasks, pushing the boundaries of AI in collaborative environments. However, the efficiency of these systems is often compromised by inadequate sample utilization and a lack of diversity in learning strategies. To enhance MARL performance, we introduce a novel sample reuse approach that dynamically adjusts policy updates based on observation novelty. Specifically, we employ a Random Network Distillation (RND) network to gauge the novelty of each agent's current state, assigning additional sample update opportunities based on the uniqueness of the data. We name our method Multi-Agent Novelty-GuidEd sample Reuse (MANGER). This method increases sample efficiency and promotes exploration and diverse agent behaviors. Our evaluations confirm substantial improvements in MARL effectiveness in complex cooperative scenarios such as Google Research Football and super-hard StarCraft II micromanagement tasks.
AutoFLUKA: A Large Language Model Based Framework for Automating Monte Carlo Simulations in FLUKA
Oct 19, 2024

Monte Carlo (MC) simulations, particularly using FLUKA, are essential for replicating real-world scenarios across scientific and engineering fields. Despite the robustness and versatility, FLUKA faces significant limitations in automation and integration with external post-processing tools, leading to workflows with a steep learning curve, which are time-consuming and prone to human errors. Traditional methods involving the use of shell and Python scripts, MATLAB, and Microsoft Excel require extensive manual intervention and lack flexibility, adding complexity to evolving scenarios. This study explores the potential of Large Language Models (LLMs) and AI agents to address these limitations. AI agents, integrate natural language processing with autonomous reasoning for decision-making and adaptive planning, making them ideal for automation. We introduce AutoFLUKA, an AI agent application developed using the LangChain Python Framework to automate typical MC simulation workflows in FLUKA. AutoFLUKA can modify FLUKA input files, execute simulations, and efficiently process results for visualization, significantly reducing human labor and error. Our case studies demonstrate that AutoFLUKA can handle both generalized and domain-specific cases, such as Microdosimetry, with an streamlined automated workflow, showcasing its scalability and flexibility. The study also highlights the potential of Retrieval Augmentation Generation (RAG) tools to act as virtual assistants for FLUKA, further improving user experience, time and efficiency. In conclusion, AutoFLUKA represents a significant advancement in automating MC simulation workflows, offering a robust solution to the inherent limitations. This innovation not only saves time and resources but also opens new paradigms for research and development in high energy physics, medical physics, nuclear engineering space and environmental science.
Dynamic Data-Driven Digital Twin Testbed for Enhanced First Responder Training and Communication
Oct 18, 2024


The study focuses on developing a digital twin testbed tailored for public safety technologies, incorporating simulated wireless communication within the digital world. The integration enables rapid analysis of signal strength, facilitating effective communication among personnel during catastrophic incidents in the virtual environment. The virtual world also helps with the training of first responders. The digital environment is constructed using the actual training facility for first responders as a blueprint. Using the photo-reference method, we meticulously constructed all buildings and objects within this environment. These reconstructed models are precisely placed relative to their real-world counterparts. Subsequently, all structures and objects are integrated into the Unreal Engine (UE) to create an interactive environment tailored specifically to the requirements of first responders.
Guiding Wireless Signals with Arrays of Metallic Linear Fresnel Reflectors: A Low-cost, Frequency-versatile, and Practical Approach
Jul 27, 2024This study presents a novel mechanical metallic reflector array to guide wireless signals to the point of interest, thereby enhancing received signal quality. Comprised of numerous individual units, this device, which acts as a linear Fresnel reflector (LFR), facilitates the reflection of incoming signals to a desired location. Leveraging geometric principles, we present a systematic approach for redirecting beams from an Access Point (AP) toward User Equipment (UE) positions. This methodology is geared towards optimizing beam allocation, thereby maximizing the number of beams directed towards the UE. Ray tracing simulations conducted for two 3D wireless communication scenarios demonstrate significant increases in path gains and received signal strengths (RSS) by at least 50dB with strategically positioned devices.
World Models with Hints of Large Language Models for Goal Achieving
Jun 11, 2024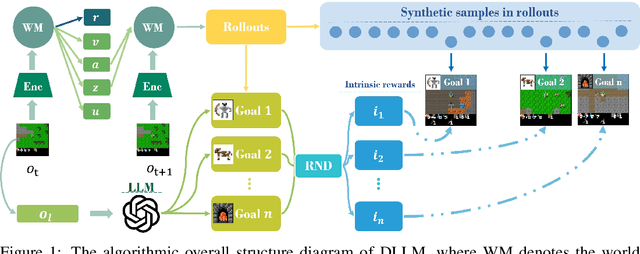

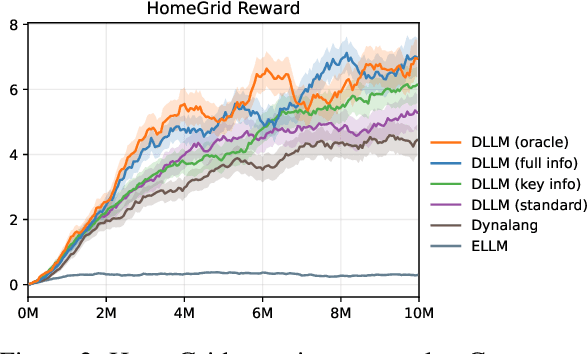
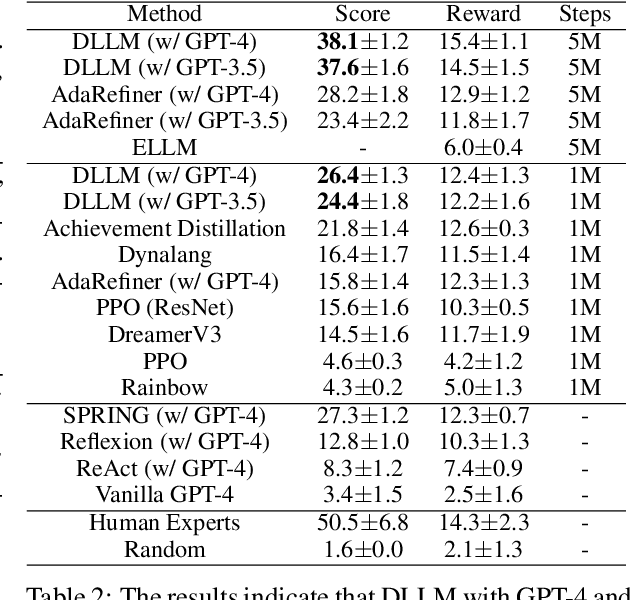
Reinforcement learning struggles in the face of long-horizon tasks and sparse goals due to the difficulty in manual reward specification. While existing methods address this by adding intrinsic rewards, they may fail to provide meaningful guidance in long-horizon decision-making tasks with large state and action spaces, lacking purposeful exploration. Inspired by human cognition, we propose a new multi-modal model-based RL approach named Dreaming with Large Language Models (DLLM). DLLM integrates the proposed hinting subgoals from the LLMs into the model rollouts to encourage goal discovery and reaching in challenging tasks. By assigning higher intrinsic rewards to samples that align with the hints outlined by the language model during model rollouts, DLLM guides the agent toward meaningful and efficient exploration. Extensive experiments demonstrate that the DLLM outperforms recent methods in various challenging, sparse-reward environments such as HomeGrid, Crafter, and Minecraft by 27.7\%, 21.1\%, and 9.9\%, respectively.
Exploration and Anti-Exploration with Distributional Random Network Distillation
Jan 25, 2024



Exploration remains a critical issue in deep reinforcement learning for an agent to attain high returns in unknown environments. Although the prevailing exploration Random Network Distillation (RND) algorithm has been demonstrated to be effective in numerous environments, it often needs more discriminative power in bonus allocation. This paper highlights the ``bonus inconsistency'' issue within RND, pinpointing its primary limitation. To address this issue, we introduce the Distributional RND (DRND), a derivative of the RND. DRND enhances the exploration process by distilling a distribution of random networks and implicitly incorporating pseudo counts to improve the precision of bonus allocation. This refinement encourages agents to engage in more extensive exploration. Our method effectively mitigates the inconsistency issue without introducing significant computational overhead. Both theoretical analysis and experimental results demonstrate the superiority of our approach over the original RND algorithm. Our method excels in challenging online exploration scenarios and effectively serves as an anti-exploration mechanism in D4RL offline tasks.