 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResults of the NeurIPS 2023 Neural MMO Competition on Multi-task Reinforcement Learning
Aug 17, 2025We present the results of the NeurIPS 2023 Neural MMO Competition, which attracted over 200 participants and submissions. Participants trained goal-conditional policies that generalize to tasks, maps, and opponents never seen during training. The top solution achieved a score 4x higher than our baseline within 8 hours of training on a single 4090 GPU. We open-source everything relating to Neural MMO and the competition under the MIT license, including the policy weights and training code for our baseline and for the top submissions.
Using Human Feedback to Fine-tune Diffusion Models without Any Reward Model
Nov 23, 2023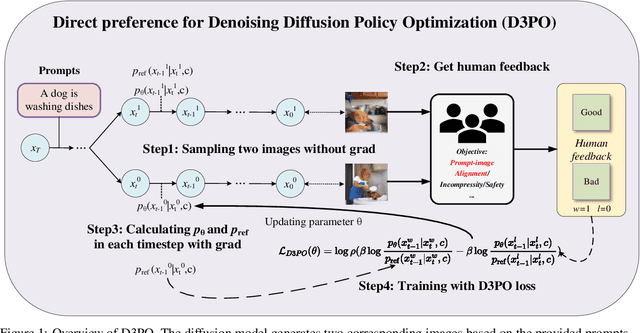

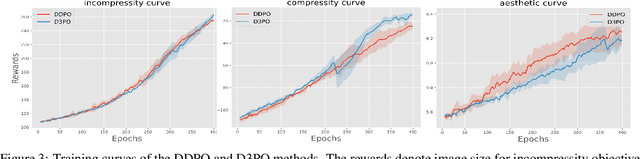
Using reinforcement learning with human feedback (RLHF) has shown significant promise in fine-tuning diffusion models. Previous methods start by training a reward model that aligns with human preferences, then leverage RL techniques to fine-tune the underlying models. However, crafting an efficient reward model demands extensive datasets, optimal architecture, and manual hyperparameter tuning, making the process both time and cost-intensive. The direct preference optimization (DPO) method, effective in fine-tuning large language models, eliminates the necessity for a reward model. However, the extensive GPU memory requirement of the diffusion model's denoising process hinders the direct application of the DPO method. To address this issue, we introduce the Direct Preference for Denoising Diffusion Policy Optimization (D3PO) method to directly fine-tune diffusion models. The theoretical analysis demonstrates that although D3PO omits training a reward model, it effectively functions as the optimal reward model trained using human feedback data to guide the learning process. This approach requires no training of a reward model, proving to be more direct, cost-effective, and minimizing computational overhead. In experiments, our method uses the relative scale of objectives as a proxy for human preference, delivering comparable results to methods using ground-truth rewards. Moreover, D3PO demonstrates the ability to reduce image distortion rates and generate safer images, overcoming challenges lacking robust reward models. Our code is publicly available in https://github.com/yk7333/D3PO/tree/main.
Neural MMO 2.0: A Massively Multi-task Addition to Massively Multi-agent Learning
Nov 07, 2023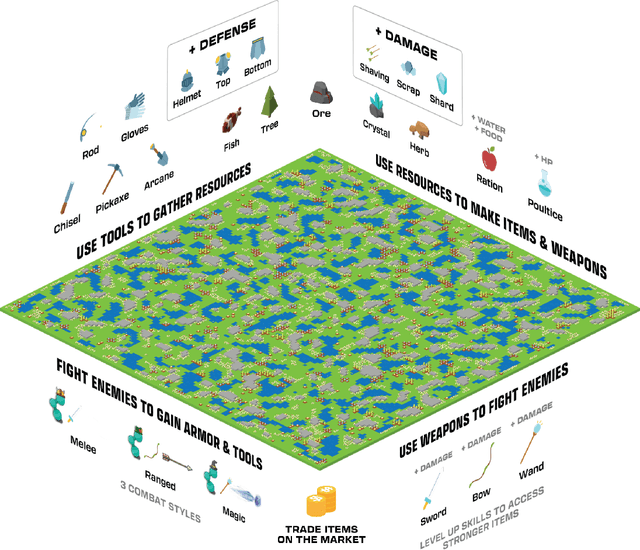

Neural MMO 2.0 is a massively multi-agent environment for reinforcement learning research. The key feature of this new version is a flexible task system that allows users to define a broad range of objectives and reward signals. We challenge researchers to train agents capable of generalizing to tasks, maps, and opponents never seen during training. Neural MMO features procedurally generated maps with 128 agents in the standard setting and support for up to. Version 2.0 is a complete rewrite of its predecessor with three-fold improved performance and compatibility with CleanRL. We release the platform as free and open-source software with comprehensive documentation available at neuralmmo.github.io and an active community Discord. To spark initial research on this new platform, we are concurrently running a competition at NeurIPS 2023.
Boosting Decision-Based Black-Box Adversarial Attack with Gradient Priors
Oct 29, 2023


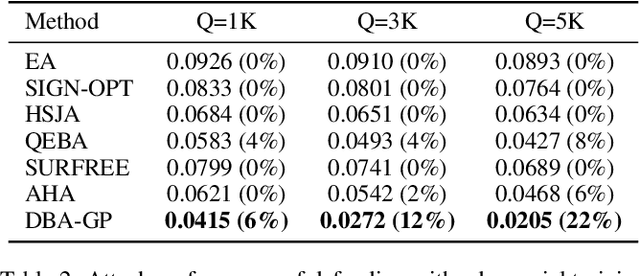
Decision-based methods have shown to be effective in black-box adversarial attacks, as they can obtain satisfactory performance and only require to access the final model prediction. Gradient estimation is a critical step in black-box adversarial attacks, as it will directly affect the query efficiency. Recent works have attempted to utilize gradient priors to facilitate score-based methods to obtain better results. However, these gradient priors still suffer from the edge gradient discrepancy issue and the successive iteration gradient direction issue, thus are difficult to simply extend to decision-based methods. In this paper, we propose a novel Decision-based Black-box Attack framework with Gradient Priors (DBA-GP), which seamlessly integrates the data-dependent gradient prior and time-dependent prior into the gradient estimation procedure. First, by leveraging the joint bilateral filter to deal with each random perturbation, DBA-GP can guarantee that the generated perturbations in edge locations are hardly smoothed, i.e., alleviating the edge gradient discrepancy, thus remaining the characteristics of the original image as much as possible. Second, by utilizing a new gradient updating strategy to automatically adjust the successive iteration gradient direction, DBA-GP can accelerate the convergence speed, thus improving the query efficiency. Extensive experiments have demonstrated that the proposed method outperforms other strong baselines significantly.
Recon: Reducing Conflicting Gradients from the Root for Multi-Task Learning
Feb 22, 2023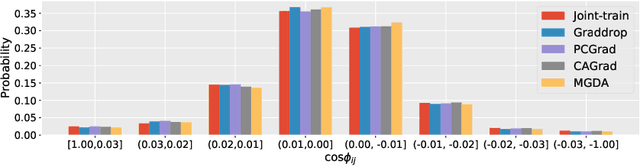

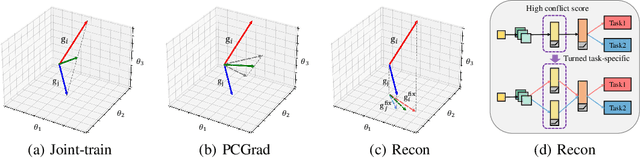
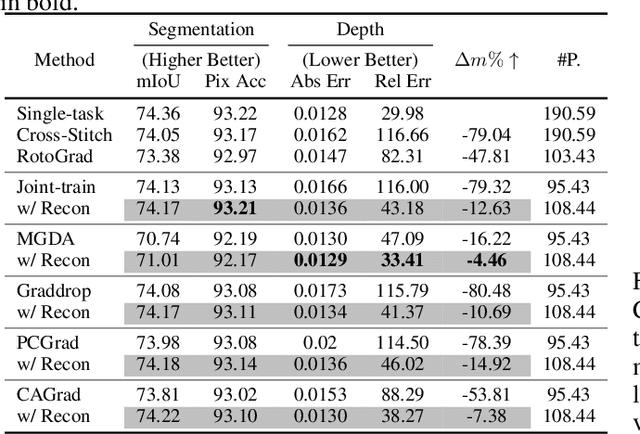
A fundamental challenge for multi-task learning is that different tasks may conflict with each other when they are solved jointly, and a cause of this phenomenon is conflicting gradients during optimization. Recent works attempt to mitigate the influence of conflicting gradients by directly altering the gradients based on some criteria. However, our empirical study shows that ``gradient surgery'' cannot effectively reduce the occurrence of conflicting gradients. In this paper, we take a different approach to reduce conflicting gradients from the root. In essence, we investigate the task gradients w.r.t. each shared network layer, select the layers with high conflict scores, and turn them to task-specific layers. Our experiments show that such a simple approach can greatly reduce the occurrence of conflicting gradients in the remaining shared layers and achieve better performance, with only a slight increase in model parameters in many cases. Our approach can be easily applied to improve various state-of-the-art methods including gradient manipulation methods and branched architecture search methods. Given a network architecture (e.g., ResNet18), it only needs to search for the conflict layers once, and the network can be modified to be used with different methods on the same or even different datasets to gain performance improvement. The source code is available at https://github.com/moukamisama/Recon.
Simple yet Effective Gradient-Free Graph Convolutional Networks
Feb 01, 2023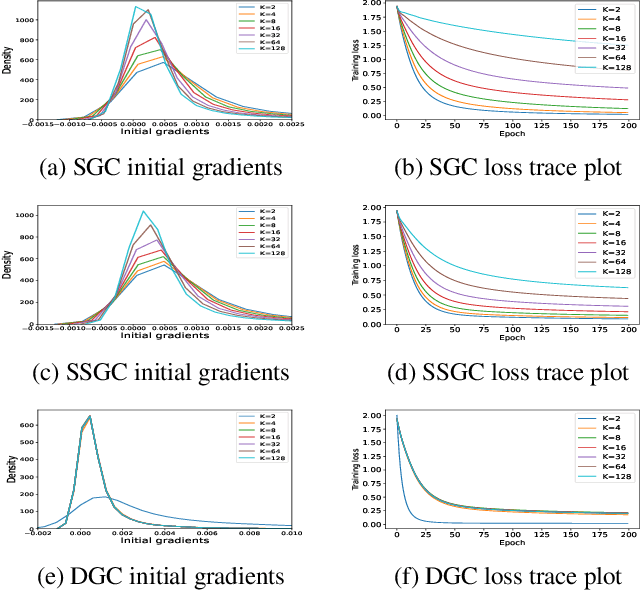
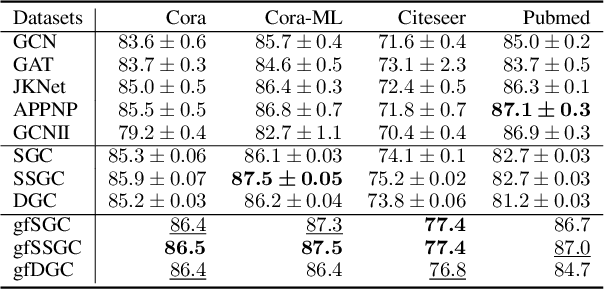
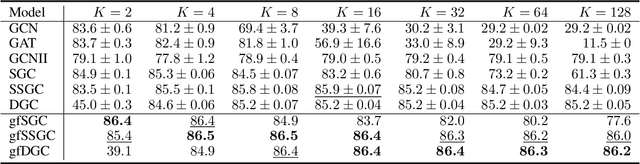
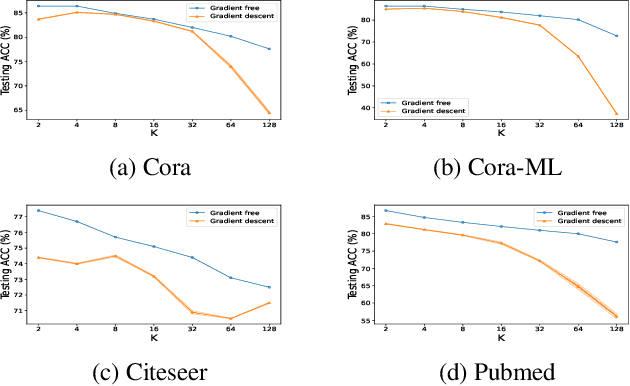
Linearized Graph Neural Networks (GNNs) have attracted great attention in recent years for graph representation learning. Compared with nonlinear Graph Neural Network (GNN) models, linearized GNNs are much more time-efficient and can achieve comparable performances on typical downstream tasks such as node classification. Although some linearized GNN variants are purposely crafted to mitigate ``over-smoothing", empirical studies demonstrate that they still somehow suffer from this issue. In this paper, we instead relate over-smoothing with the vanishing gradient phenomenon and craft a gradient-free training framework to achieve more efficient and effective linearized GNNs which can significantly overcome over-smoothing and enhance the generalization of the model. The experimental results demonstrate that our methods achieve better and more stable performances on node classification tasks with varying depths and cost much less training time.
Multi-Agent Path Finding via Tree LSTM
Oct 24, 2022
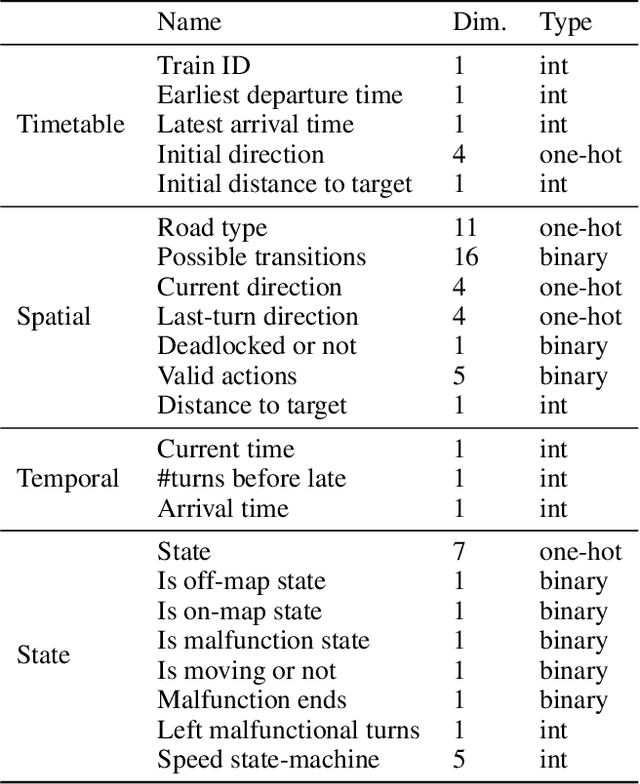

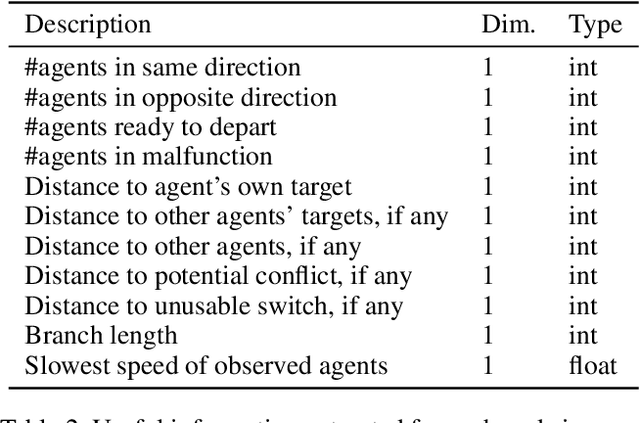
In recent years, Multi-Agent Path Finding (MAPF) has attracted attention from the fields of both Operations Research (OR) and Reinforcement Learning (RL). However, in the 2021 Flatland3 Challenge, a competition on MAPF, the best RL method scored only 27.9, far less than the best OR method. This paper proposes a new RL solution to Flatland3 Challenge, which scores 125.3, several times higher than the best RL solution before. We creatively apply a novel network architecture, TreeLSTM, to MAPF in our solution. Together with several other RL techniques, including reward shaping, multiple-phase training, and centralized control, our solution is comparable to the top 2-3 OR methods.
Modeling User Behavior with Graph Convolution for Personalized Product Search
Feb 12, 2022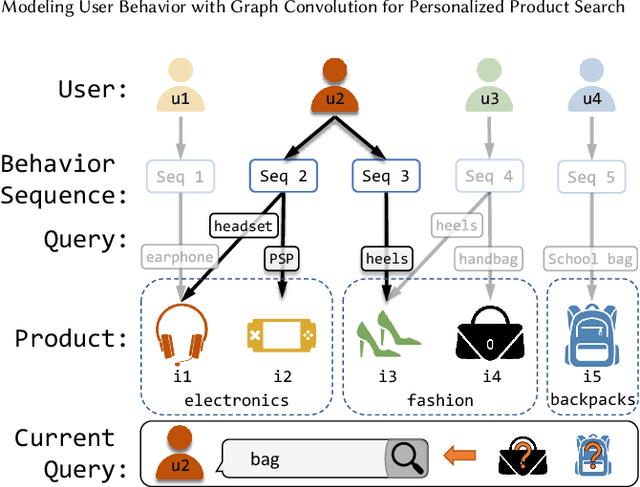
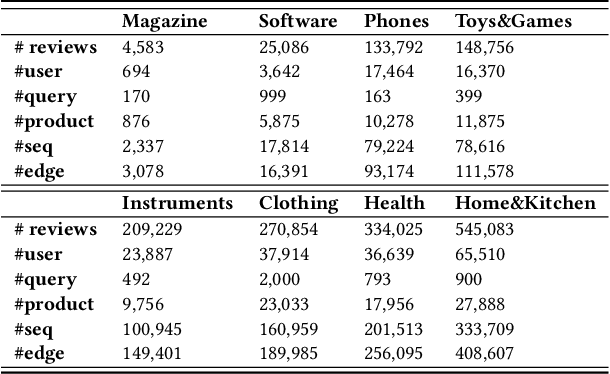
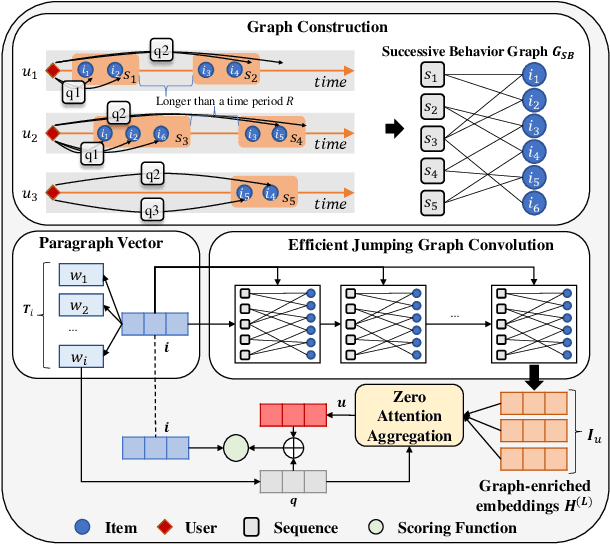
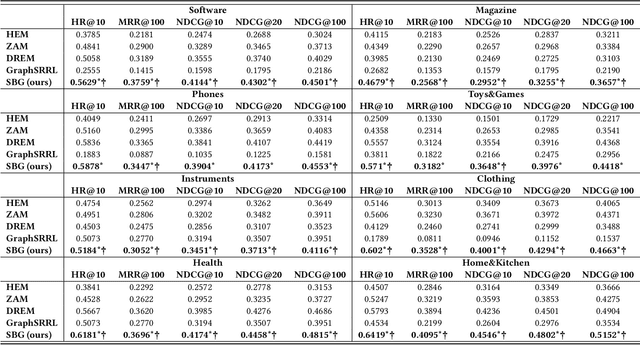
User preference modeling is a vital yet challenging problem in personalized product search. In recent years, latent space based methods have achieved state-of-the-art performance by jointly learning semantic representations of products, users, and text tokens. However, existing methods are limited in their ability to model user preferences. They typically represent users by the products they visited in a short span of time using attentive models and lack the ability to exploit relational information such as user-product interactions or item co-occurrence relations. In this work, we propose to address the limitations of prior arts by exploring local and global user behavior patterns on a user successive behavior graph, which is constructed by utilizing short-term actions of all users. To capture implicit user preference signals and collaborative patterns, we use an efficient jumping graph convolution to explore high-order relations to enrich product representations for user preference modeling. Our approach can be seamlessly integrated with existing latent space based methods and be potentially applied in any product retrieval method that uses purchase history to model user preferences. Extensive experiments on eight Amazon benchmarks demonstrate the effectiveness and potential of our approach. The source code is available at \url{https://github.com/floatSDSDS/SBG}.
Attributed Graph Learning with 2-D Graph Convolution
Sep 27, 2019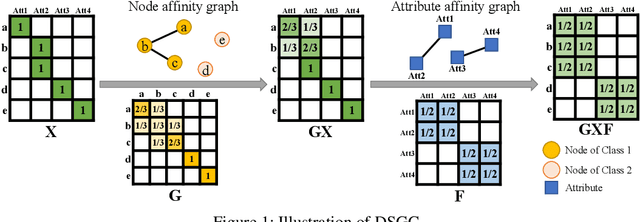

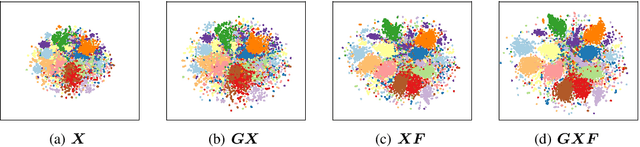

Graph convolutional neural networks have demonstrated promising performance in attributed graph learning, thanks to the use of graph convolution that effectively combines graph structures and node features for learning node representations. However, one intrinsic limitation of the commonly adopted 1-D graph convolution is that it only exploits graph connectivity for feature smoothing, which may lead to inferior performance on sparse and noisy real-world attributed networks. To address this problem, we propose to explore relational information among node attributes to complement node relations for representation learning. In particular, we propose to use 2-D graph convolution to jointly model the two kinds of relations and develop a computationally efficient dimensionwise separable 2-D graph convolution (DSGC). Theoretically, we show that DSGC can reduce intra-class variance of node features on both the node dimension and the attribute dimension to facilitate learning. Empirically, we demonstrate that by incorporating attribute relations, DSGC achieves significant performance gain over state-of-the-art methods on node classification and clustering on several real-world attributed networks.
Clustering Uncertain Data via Representative Possible Worlds with Consistency Learning
Sep 27, 2019


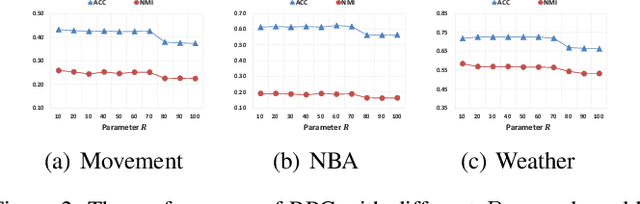
Clustering uncertain data is an essential task in data mining for the internet of things. Possible world based algorithms seem promising for clustering uncertain data. However, there are two issues in existing possible world based algorithms: (1) They rely on all the possible worlds and treat them equally, but some marginal possible worlds may cause negative effects. (2) They do not well utilize the consistency among possible worlds, since they conduct clustering or construct the affinity matrix on each possible world independently. In this paper, we propose a representative possible world based consistent clustering (RPC) algorithm for uncertain data. First, by introducing representative loss and using Jensen-Shannon divergence as the distribution measure, we design a heuristic strategy for the selection of representative possible worlds, thus avoiding the negative effects caused by marginal possible worlds. Second, we integrate a consistency learning procedure into spectral clustering to deal with the representative possible worlds synergistically, thus utilizing the consistency to achieve better performance. Experimental results show that our proposed algorithm performs better than the state-of-the-art algorithms.