Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agent Path Finding via Tree LSTM
Paper and Code
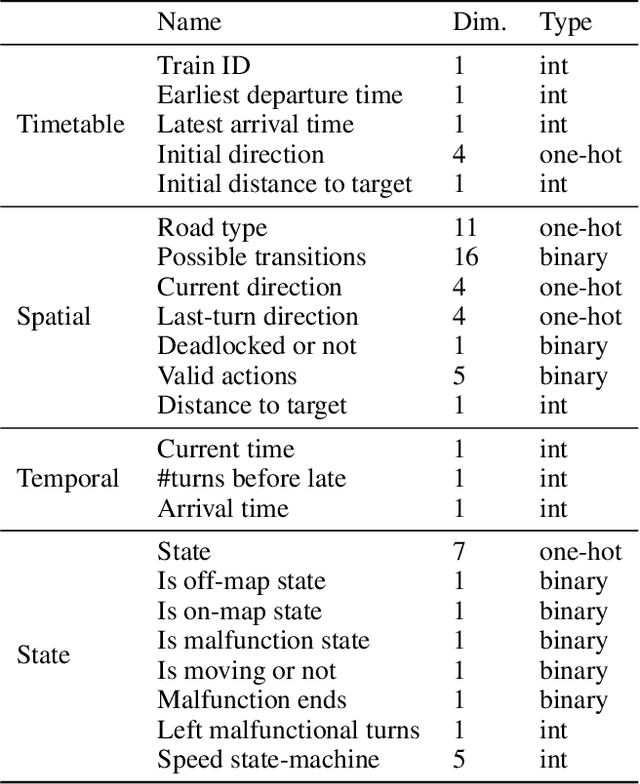

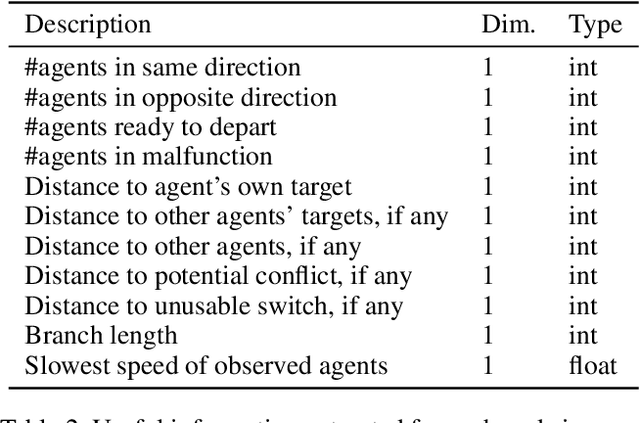
In recent years, Multi-Agent Path Finding (MAPF) has attracted attention from the fields of both Operations Research (OR) and Reinforcement Learning (RL). However, in the 2021 Flatland3 Challenge, a competition on MAPF, the best RL method scored only 27.9, far less than the best OR method. This paper proposes a new RL solution to Flatland3 Challenge, which scores 125.3, several times higher than the best RL solution before. We creatively apply a novel network architecture, TreeLSTM, to MAPF in our solution. Together with several other RL techniques, including reward shaping, multiple-phase training, and centralized control, our solution is comparable to the top 2-3 OR methods.
* In submission to AAAI23-MAPF
View paper on