 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorkflow-GYM: Towards Long-Horizon Evaluation of Computer-use Agentic tasks in Real-World Professional Fields
Jun 09, 2026Recent years have witnessed the rapid evolution of AI agents toward handling increasingly complex, real-world tasks. However, existing benchmarks rarely evaluate whether agents can operate graphical user interfaces to complete long-horizon, high-value professional workflows across diverse domains. Current GUI benchmarks still predominantly focus on general-purpose software, relatively simple applications, and short-horizon tasks, leaving it largely unknown whether modern agents can follow user instructions to autonomously operate domain-specific professional software and accomplish economically valuable work in an end-to-end manner. To bridge this gap, we introduce Workflow-GYM, a benchmark for long-horizon GUI tasks centered on professional domains and specialized software environments. Through extensive experiments on state-of-the-art models, we find that even the strongest models achieve only slightly above 30% success rates, highlighting that professional long-horizon GUI workflows remain highly challenging for current GUI agents. Further analysis reveals that current agents struggle to maintain long-horizon workflow consistency, frequently exhibiting workflow stage omission, error propagation, objective drift, and insufficient understanding of professional software environments. Our findings provide important insights into the limitations of current agent systems and suggest key directions for the next generation of GUI-agent research.
When Can We Trust Deep Neural Networks? Towards Reliable Industrial Deployment with an Interpretability Guide
Apr 21, 2026The deployment of AI systems in safety-critical domains, such as industrial defect inspection, autonomous driving, and medical diagnosis, is severely hampered by their lack of reliability. A single undetected erroneous prediction can lead to catastrophic outcomes. Unfortunately, there is often no alternative but to place trust in the outputs of a trained AI system, which operates without an internal safeguard to flag unreliable predictions, even in cases of high accuracy. We propose a post-hoc explanation-based indicator to detect false negatives in binary defect detection networks. To our knowledge, this is the first method to proactively identify potentially erroneous network outputs. Our core idea leverages the difference between class-specific discriminative heatmaps and class-agnostic ones. We compute the difference in their intersection over union (IoU) as a reliability score. An adversarial enhancement method is further introduced to amplify this disparity. Evaluations on two industrial defect detection benchmarks show our method effectively identifies false negatives. With adversarial enhancement, it achieves 100\% recall, albeit with a trade-off for true negatives. Our work thus advocates for a new and trustworthy deployment paradigm: data-model-explanation-output, moving beyond conventional end-to-end systems to provide critical support for reliable AI in real-world applications.
Segmental Advantage Estimation: Enhancing PPO for Long-Context LLM Training
Jan 12, 2026Training Large Language Models (LLMs) for reasoning tasks is increasingly driven by Reinforcement Learning with Verifiable Rewards (RLVR), where Proximal Policy Optimization (PPO) provides a principled framework for stable policy updates. However, the practical application of PPO is hindered by unreliable advantage estimation in the sparse-reward RLVR regime. This issue arises because the sparse rewards in RLVR lead to inaccurate intermediate value predictions, which in turn introduce significant bias when aggregated at every token by Generalized Advantage Estimation (GAE). To address this, we introduce Segmental Advantage Estimation (SAE), which mitigates the bias that GAE can incur in RLVR. Our key insight is that aggregating $n$-step advantages at every token(as in GAE) is unnecessary and often introduces excessive bias, since individual tokens carry minimal information. Instead, SAE first partitions the generated sequence into coherent sub-segments using low-probability tokens as heuristic boundaries. It then selectively computes variance-reduced advantage estimates only from these information-rich segment transitions, effectively filtering out noise from intermediate tokens. Our experiments demonstrate that SAE achieves superior performance, with marked improvements in final scores, training stability, and sample efficiency. These gains are shown to be consistent across multiple model sizes, and a correlation analysis confirms that our proposed advantage estimator achieves a higher correlation with an approximate ground-truth advantage, justifying its superior performance.
Cumulative Path-Level Semantic Reasoning for Inductive Knowledge Graph Completion
Jan 09, 2026Conventional Knowledge Graph Completion (KGC) methods aim to infer missing information in incomplete Knowledge Graphs (KGs) by leveraging existing information, which struggle to perform effectively in scenarios involving emerging entities. Inductive KGC methods can handle the emerging entities and relations in KGs, offering greater dynamic adaptability. While existing inductive KGC methods have achieved some success, they also face challenges, such as susceptibility to noisy structural information during reasoning and difficulty in capturing long-range dependencies in reasoning paths. To address these challenges, this paper proposes the Cumulative Path-Level Semantic Reasoning for inductive knowledge graph completion (CPSR) framework, which simultaneously captures both the structural and semantic information of KGs to enhance the inductive KGC task. Specifically, the proposed CPSR employs a query-dependent masking module to adaptively mask noisy structural information while retaining important information closely related to the targets. Additionally, CPSR introduces a global semantic scoring module that evaluates both the individual contributions and the collective impact of nodes along the reasoning path within KGs. The experimental results demonstrate that CPSR achieves state-of-the-art performance.
Training Report of TeleChat3-MoE
Dec 30, 2025TeleChat3-MoE is the latest series of TeleChat large language models, featuring a Mixture-of-Experts (MoE) architecture with parameter counts ranging from 105 billion to over one trillion,trained end-to-end on Ascend NPU cluster. This technical report mainly presents the underlying training infrastructure that enables reliable and efficient scaling to frontier model sizes. We detail systematic methodologies for operator-level and end-to-end numerical accuracy verification, ensuring consistency across hardware platforms and distributed parallelism strategies. Furthermore, we introduce a suite of performance optimizations, including interleaved pipeline scheduling, attention-aware data scheduling for long-sequence training,hierarchical and overlapped communication for expert parallelism, and DVM-based operator fusion. A systematic parallelization framework, leveraging analytical estimation and integer linear programming, is also proposed to optimize multi-dimensional parallelism configurations. Additionally, we present methodological approaches to cluster-level optimizations, addressing host- and device-bound bottlenecks during large-scale training tasks. These infrastructure advancements yield significant throughput improvements and near-linear scaling on clusters comprising thousands of devices, providing a robust foundation for large-scale language model development on hardware ecosystems.
Flexible and Foldable: Workspace Analysis and Object Manipulation Using a Soft, Interconnected, Origami-Inspired Actuator Array
Sep 17, 2025Object manipulation is a fundamental challenge in robotics, where systems must balance trade-offs among manipulation capabilities, system complexity, and throughput. Distributed manipulator systems (DMS) use the coordinated motion of actuator arrays to perform complex object manipulation tasks, seeing widespread exploration within the literature and in industry. However, existing DMS designs typically rely on high actuator densities and impose constraints on object-to-actuator scale ratios, limiting their adaptability. We present a novel DMS design utilizing an array of 3-DoF, origami-inspired robotic tiles interconnected by a compliant surface layer. Unlike conventional DMS, our approach enables manipulation not only at the actuator end effectors but also across a flexible surface connecting all actuators; creating a continuous, controllable manipulation surface. We analyse the combined workspace of such a system, derive simple motion primitives, and demonstrate its capabilities to translate simple geometric objects across an array of tiles. By leveraging the inter-tile connective material, our approach significantly reduces actuator density, increasing the area over which an object can be manipulated by x1.84 without an increase in the number of actuators. This design offers a lower cost and complexity alternative to traditional high-density arrays, and introduces new opportunities for manipulation strategies that leverage the flexibility of the interconnected surface.
Results of the NeurIPS 2023 Neural MMO Competition on Multi-task Reinforcement Learning
Aug 17, 2025We present the results of the NeurIPS 2023 Neural MMO Competition, which attracted over 200 participants and submissions. Participants trained goal-conditional policies that generalize to tasks, maps, and opponents never seen during training. The top solution achieved a score 4x higher than our baseline within 8 hours of training on a single 4090 GPU. We open-source everything relating to Neural MMO and the competition under the MIT license, including the policy weights and training code for our baseline and for the top submissions.
Technical Report of TeleChat2, TeleChat2.5 and T1
Jul 24, 2025
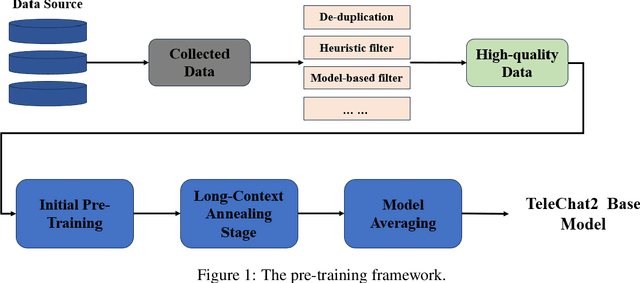

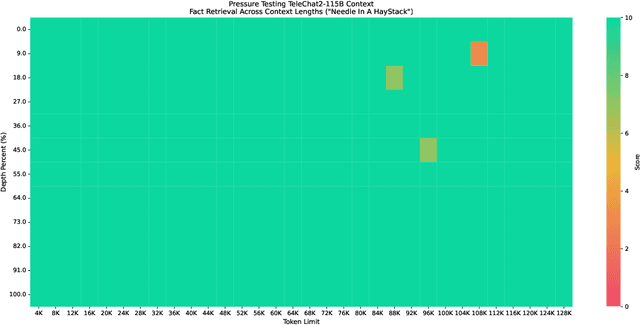
We introduce the latest series of TeleChat models: \textbf{TeleChat2}, \textbf{TeleChat2.5}, and \textbf{T1}, offering a significant upgrade over their predecessor, TeleChat. Despite minimal changes to the model architecture, the new series achieves substantial performance gains through enhanced training strategies in both pre-training and post-training stages. The series begins with \textbf{TeleChat2}, which undergoes pretraining on 10 trillion high-quality and diverse tokens. This is followed by Supervised Fine-Tuning (SFT) and Direct Preference Optimization (DPO) to further enhance its capabilities. \textbf{TeleChat2.5} and \textbf{T1} expand the pipeline by incorporating a continual pretraining phase with domain-specific datasets, combined with reinforcement learning (RL) to improve performance in code generation and mathematical reasoning tasks. The \textbf{T1} variant is designed for complex reasoning, supporting long Chain-of-Thought (CoT) reasoning and demonstrating substantial improvements in mathematics and coding. In contrast, \textbf{TeleChat2.5} prioritizes speed, delivering rapid inference. Both flagship models of \textbf{T1} and \textbf{TeleChat2.5} are dense Transformer-based architectures with 115B parameters, showcasing significant advancements in reasoning and general task performance compared to the original TeleChat. Notably, \textbf{T1-115B} outperform proprietary models such as OpenAI's o1-mini and GPT-4o. We publicly release \textbf{TeleChat2}, \textbf{TeleChat2.5} and \textbf{T1}, including post-trained versions with 35B and 115B parameters, to empower developers and researchers with state-of-the-art language models tailored for diverse applications.
Adaptive Termination for Multi-round Parallel Reasoning: An Universal Semantic Entropy-Guided Framework
Jul 09, 2025Recent advances in large language models (LLMs) have accelerated progress toward artificial general intelligence, with inference-time scaling emerging as a key technique. Contemporary approaches leverage either sequential reasoning (iteratively extending chains of thought) or parallel reasoning (generating multiple solutions simultaneously) to scale inference. However, both paradigms face fundamental limitations: sequential scaling typically relies on arbitrary token budgets for termination, leading to inefficiency or premature cutoff; while parallel scaling often lacks coordination among parallel branches and requires intrusive fine-tuning to perform effectively. In light of these challenges, we aim to design a flexible test-time collaborative inference framework that exploits the complementary strengths of both sequential and parallel reasoning paradigms. Towards this goal, the core challenge lies in developing an efficient and accurate intrinsic quality metric to assess model responses during collaborative inference, enabling dynamic control and early termination of the reasoning trace. To address this challenge, we introduce semantic entropy (SE), which quantifies the semantic diversity of parallel model responses and serves as a robust indicator of reasoning quality due to its strong negative correlation with accuracy...
Vibration of Soft, Twisted Beams for Under-Actuated Quadrupedal Locomotion
Jul 03, 2025Under-actuated compliant robotic systems offer a promising approach to mitigating actuation and control challenges by harnessing pre-designed, embodied dynamic behaviors. This paper presents Flix-Walker, a novel, untethered, centimeter-scale quadrupedal robot inspired by compliant under-actuated mechanisms. Flix-Walker employs flexible, helix-shaped beams as legs, which are actuated by vibrations from just two motors to achieve three distinct mobility modes. We analyze the actuation parameters required to generate various locomotion modes through both simulation and prototype experiments. The effects of system and environmental variations on locomotion performance are examined, and we propose a generic metric for selecting control parameters that produce robust and functional motions. Experiments validate the effectiveness and robustness of these actuation parameters within a closed-loop control framework, demonstrating reliable trajectory-tracking and self-navigation capabilities.