 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Class Activation Maps for Segmentation: Revealing Semantic Information in Shallow Layers by Reducing Noise
Aug 04, 2023



Class activation maps are widely used for explaining deep neural networks. Due to its ability to highlight regions of interest, it has evolved in recent years as a key step in weakly supervised learning. A major limitation to the performance of the class activation maps is the small spatial resolution of the feature maps in the last layer of the convolutional neural network. Therefore, we expect to generate high-resolution feature maps that result in high-quality semantic information. In this paper, we rethink the properties of semantic information in shallow feature maps. We find that the shallow feature maps still have fine-grained non-discriminative features while mixing considerable non-target noise. Furthermore, we propose a simple gradient-based denoising method to filter the noise by truncating the positive gradient. Our proposed scheme can be easily deployed in other CAM-related methods, facilitating these methods to obtain higher-quality class activation maps. We evaluate the proposed approach through a weakly-supervised semantic segmentation task, and a large number of experiments demonstrate the effectiveness of our approach.
Training Neural Networks for Solving 1-D Optimal Piecewise Linear Approximation
Oct 14, 2021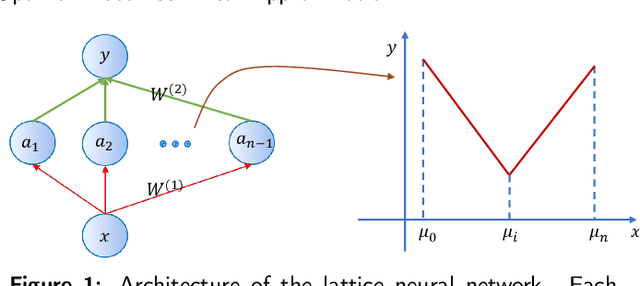
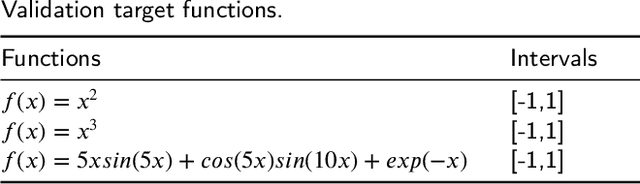
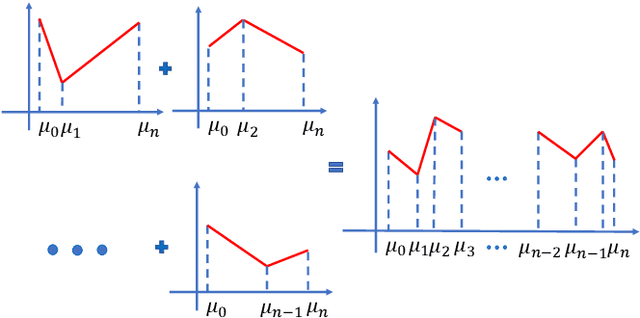
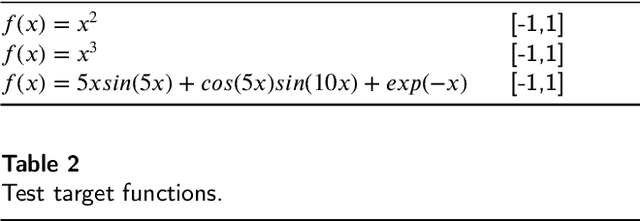
Recently, the interpretability of deep learning has attracted a lot of attention. A plethora of methods have attempted to explain neural networks by feature visualization, saliency maps, model distillation, and so on. However, it is hard for these methods to reveal the intrinsic properties of neural networks. In this work, we studied the 1-D optimal piecewise linear approximation (PWLA) problem, and associated it with a designed neural network, named lattice neural network (LNN). We asked four essential questions as following: (1) What are the characters of the optimal solution of the PWLA problem? (2) Can an LNN converge to the global optimum? (3) Can an LNN converge to the local optimum? (4) Can an LNN solve the PWLA problem? Our main contributions are that we propose the theorems to characterize the optimal solution of the PWLA problem and present the LNN method for solving it. We evaluated the proposed LNNs on approximation tasks, forged an empirical method to improve the performance of LNNs. The experiments verified that our LNN method is competitive with the start-of-the-art method.