 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeR-GenIMA: Integrating Neuroimaging and Genetics with Interpretable Multimodal AI for Alzheimer's Disease Progression
Dec 22, 2025Early detection of Alzheimer's disease (AD) requires models capable of integrating macro-scale neuroanatomical alterations with micro-scale genetic susceptibility, yet existing multimodal approaches struggle to align these heterogeneous signals. We introduce R-GenIMA, an interpretable multimodal large language model that couples a novel ROI-wise vision transformer with genetic prompting to jointly model structural MRI and single nucleotide polymorphisms (SNPs) variations. By representing each anatomically parcellated brain region as a visual token and encoding SNP profiles as structured text, the framework enables cross-modal attention that links regional atrophy patterns to underlying genetic factors. Applied to the ADNI cohort, R-GenIMA achieves state-of-the-art performance in four-way classification across normal cognition (NC), subjective memory concerns (SMC), mild cognitive impairment (MCI), and AD. Beyond predictive accuracy, the model yields biologically meaningful explanations by identifying stage-specific brain regions and gene signatures, as well as coherent ROI-Gene association patterns across the disease continuum. Attention-based attribution revealed genes consistently enriched for established GWAS-supported AD risk loci, including APOE, BIN1, CLU, and RBFOX1. Stage-resolved neuroanatomical signatures identified shared vulnerability hubs across disease stages alongside stage-specific patterns: striatal involvement in subjective decline, frontotemporal engagement during prodromal impairment, and consolidated multimodal network disruption in AD. These results demonstrate that interpretable multimodal AI can synthesize imaging and genetics to reveal mechanistic insights, providing a foundation for clinically deployable tools that enable earlier risk stratification and inform precision therapeutic strategies in Alzheimer's disease.
Step-GUI Technical Report
Dec 19, 2025



Recent advances in multimodal large language models unlock unprecedented opportunities for GUI automation. However, a fundamental challenge remains: how to efficiently acquire high-quality training data while maintaining annotation reliability? We introduce a self-evolving training pipeline powered by the Calibrated Step Reward System, which converts model-generated trajectories into reliable training signals through trajectory-level calibration, achieving >90% annotation accuracy with 10-100x lower cost. Leveraging this pipeline, we introduce Step-GUI, a family of models (4B/8B) that achieves state-of-the-art GUI performance (8B: 80.2% AndroidWorld, 48.5% OSWorld, 62.6% ScreenShot-Pro) while maintaining robust general capabilities. As GUI agent capabilities improve, practical deployment demands standardized interfaces across heterogeneous devices while protecting user privacy. To this end, we propose GUI-MCP, the first Model Context Protocol for GUI automation with hierarchical architecture that combines low-level atomic operations and high-level task delegation to local specialist models, enabling high-privacy execution where sensitive data stays on-device. Finally, to assess whether agents can handle authentic everyday usage, we introduce AndroidDaily, a benchmark grounded in real-world mobile usage patterns with 3146 static actions and 235 end-to-end tasks across high-frequency daily scenarios (8B: static 89.91%, end-to-end 52.50%). Our work advances the development of practical GUI agents and demonstrates strong potential for real-world deployment in everyday digital interactions.
Zeus: Zero-shot LLM Instruction for Union Segmentation in Multimodal Medical Imaging
Apr 09, 2025Medical image segmentation has achieved remarkable success through the continuous advancement of UNet-based and Transformer-based foundation backbones. However, clinical diagnosis in the real world often requires integrating domain knowledge, especially textual information. Conducting multimodal learning involves visual and text modalities shown as a solution, but collecting paired vision-language datasets is expensive and time-consuming, posing significant challenges. Inspired by the superior ability in numerous cross-modal tasks for Large Language Models (LLMs), we proposed a novel Vision-LLM union framework to address the issues. Specifically, we introduce frozen LLMs for zero-shot instruction generation based on corresponding medical images, imitating the radiology scanning and report generation process. {To better approximate real-world diagnostic processes}, we generate more precise text instruction from multimodal radiology images (e.g., T1-w or T2-w MRI and CT). Based on the impressive ability of semantic understanding and rich knowledge of LLMs. This process emphasizes extracting special features from different modalities and reunion the information for the ultimate clinical diagnostic. With generated text instruction, our proposed union segmentation framework can handle multimodal segmentation without prior collected vision-language datasets. To evaluate our proposed method, we conduct comprehensive experiments with influential baselines, the statistical results and the visualized case study demonstrate the superiority of our novel method.}
A Self-guided Multimodal Approach to Enhancing Graph Representation Learning for Alzheimer's Diseases
Dec 09, 2024



Graph neural networks (GNNs) are powerful machine learning models designed to handle irregularly structured data. However, their generic design often proves inadequate for analyzing brain connectomes in Alzheimer's Disease (AD), highlighting the need to incorporate domain knowledge for optimal performance. Infusing AD-related knowledge into GNNs is a complicated task. Existing methods typically rely on collaboration between computer scientists and domain experts, which can be both time-intensive and resource-demanding. To address these limitations, this paper presents a novel self-guided, knowledge-infused multimodal GNN that autonomously incorporates domain knowledge into the model development process. Our approach conceptualizes domain knowledge as natural language and introduces a specialized multimodal GNN capable of leveraging this uncurated knowledge to guide the learning process of the GNN, such that it can improve the model performance and strengthen the interpretability of the predictions. To evaluate our framework, we curated a comprehensive dataset of recent peer-reviewed papers on AD and integrated it with multiple real-world AD datasets. Experimental results demonstrate the ability of our method to extract relevant domain knowledge, provide graph-based explanations for AD diagnosis, and improve the overall performance of the GNN. This approach provides a more scalable and efficient alternative to inject domain knowledge for AD compared with the manual design from the domain expert, advancing both prediction accuracy and interpretability in AD diagnosis.
Contrastive Disentangling: Fine-grained representation learning through multi-level contrastive learning without class priors
Sep 07, 2024Recent advancements in unsupervised representation learning often leverage class information to enhance feature extraction and clustering performance. However, this reliance on class priors limits the applicability of such methods in real-world scenarios where class information is unavailable or ambiguous. In this paper, we propose Contrastive Disentangling (CD), a simple and effective framework that learns representations without any reliance on class priors. Our framework employs a multi-level contrastive learning strategy that combines instance-level and feature-level losses with a normalized entropy loss to learn semantically rich and fine-grained representations. Specifically, (1) the instance-level contrastive loss encourages the separation of feature representations for different samples, (2) the feature-level contrastive loss promotes independence among the feature head predictions, and (3) the normalized entropy loss encourages the feature heads to capture meaningful and prevalent attributes from the data. These components work together to enable CD to significantly outperform existing methods, as demonstrated by extensive experiments on benchmark datasets including CIFAR-10, CIFAR-100, STL-10, and ImageNet-10, particularly in scenarios where class priors are absent. The code is available at https://github.com/Hoper-J/Contrastive-Disentangling.
Interpretable Spatio-Temporal Embedding for Brain Structural-Effective Network with Ordinary Differential Equation
May 21, 2024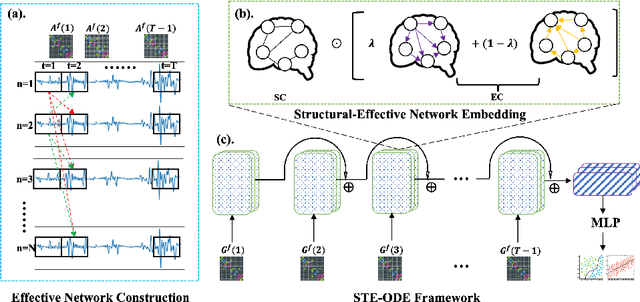
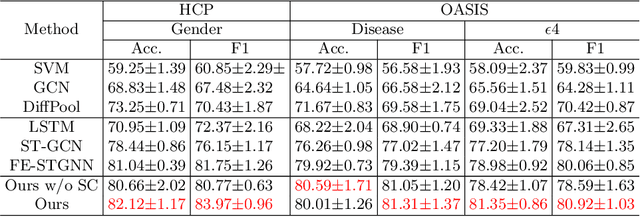
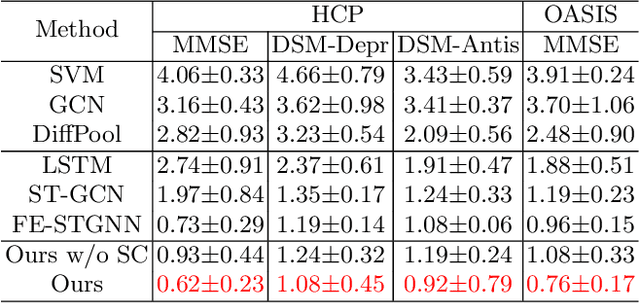
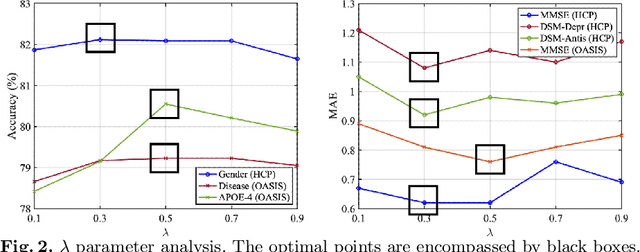
The MRI-derived brain network serves as a pivotal instrument in elucidating both the structural and functional aspects of the brain, encompassing the ramifications of diseases and developmental processes. However, prevailing methodologies, often focusing on synchronous BOLD signals from functional MRI (fMRI), may not capture directional influences among brain regions and rarely tackle temporal functional dynamics. In this study, we first construct the brain-effective network via the dynamic causal model. Subsequently, we introduce an interpretable graph learning framework termed Spatio-Temporal Embedding ODE (STE-ODE). This framework incorporates specifically designed directed node embedding layers, aiming at capturing the dynamic interplay between structural and effective networks via an ordinary differential equation (ODE) model, which characterizes spatial-temporal brain dynamics. Our framework is validated on several clinical phenotype prediction tasks using two independent publicly available datasets (HCP and OASIS). The experimental results clearly demonstrate the advantages of our model compared to several state-of-the-art methods.
Boosting Meta-Training with Base Class Information for Few-Shot Learning
Mar 06, 2024



Few-shot learning, a challenging task in machine learning, aims to learn a classifier adaptable to recognize new, unseen classes with limited labeled examples. Meta-learning has emerged as a prominent framework for few-shot learning. Its training framework is originally a task-level learning method, such as Model-Agnostic Meta-Learning (MAML) and Prototypical Networks. And a recently proposed training paradigm called Meta-Baseline, which consists of sequential pre-training and meta-training stages, gains state-of-the-art performance. However, as a non-end-to-end training method, indicating the meta-training stage can only begin after the completion of pre-training, Meta-Baseline suffers from higher training cost and suboptimal performance due to the inherent conflicts of the two training stages. To address these limitations, we propose an end-to-end training paradigm consisting of two alternative loops. In the outer loop, we calculate cross entropy loss on the entire training set while updating only the final linear layer. In the inner loop, we employ the original meta-learning training mode to calculate the loss and incorporate gradients from the outer loss to guide the parameter updates. This training paradigm not only converges quickly but also outperforms existing baselines, indicating that information from the overall training set and the meta-learning training paradigm could mutually reinforce one another. Moreover, being model-agnostic, our framework achieves significant performance gains, surpassing the baseline systems by approximate 1%.
Your Vision-Language Model Itself Is a Strong Filter: Towards High-Quality Instruction Tuning with Data Selection
Feb 19, 2024



Data selection in instruction tuning emerges as a pivotal process for acquiring high-quality data and training instruction-following large language models (LLMs), but it is still a new and unexplored research area for vision-language models (VLMs). Existing data selection approaches on LLMs either rely on single unreliable scores, or use downstream tasks for selection, which is time-consuming and can lead to potential over-fitting on the chosen evaluation datasets. To address this challenge, we introduce a novel dataset selection method, Self-Filter, that utilizes the VLM itself as a filter. This approach is inspired by the observation that VLMs benefit from training with the most challenging instructions. Self-Filter operates in two stages. In the first stage, we devise a scoring network to evaluate the difficulty of training instructions, which is co-trained with the VLM. In the second stage, we use the trained score net to measure the difficulty of each instruction, select the most challenging samples, and penalize similar samples to encourage diversity. Comprehensive experiments on LLaVA and MiniGPT-4 show that Self-Filter can reach better results compared to full data settings with merely about 15% samples, and can achieve superior performance against competitive baselines.
GPT-4 Vision on Medical Image Classification -- A Case Study on COVID-19 Dataset
Oct 27, 2023
This technical report delves into the application of GPT-4 Vision (GPT-4V) in the nuanced realm of COVID-19 image classification, leveraging the transformative potential of in-context learning to enhance diagnostic processes.
Rethinking Class Activation Maps for Segmentation: Revealing Semantic Information in Shallow Layers by Reducing Noise
Aug 04, 2023



Class activation maps are widely used for explaining deep neural networks. Due to its ability to highlight regions of interest, it has evolved in recent years as a key step in weakly supervised learning. A major limitation to the performance of the class activation maps is the small spatial resolution of the feature maps in the last layer of the convolutional neural network. Therefore, we expect to generate high-resolution feature maps that result in high-quality semantic information. In this paper, we rethink the properties of semantic information in shallow feature maps. We find that the shallow feature maps still have fine-grained non-discriminative features while mixing considerable non-target noise. Furthermore, we propose a simple gradient-based denoising method to filter the noise by truncating the positive gradient. Our proposed scheme can be easily deployed in other CAM-related methods, facilitating these methods to obtain higher-quality class activation maps. We evaluate the proposed approach through a weakly-supervised semantic segmentation task, and a large number of experiments demonstrate the effectiveness of our approach.