 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChronusOmni: Improving Time Awareness of Omni Large Language Models
Dec 10, 2025Time awareness is a fundamental ability of omni large language models, especially for understanding long videos and answering complex questions. Previous approaches mainly target vision-language scenarios and focus on the explicit temporal grounding questions, such as identifying when a visual event occurs or determining what event happens at aspecific time. However, they often make insufficient use of the audio modality, and overlook implicit temporal grounding across modalities--for example, identifying what is visually present when a character speaks, or determining what is said when a visual event occurs--despite such cross-modal temporal relations being prevalent in real-world scenarios. In this paper, we propose ChronusOmni, an omni large language model designed to enhance temporal awareness for both explicit and implicit audiovisual temporal grounding. First, we interleave text-based timestamp tokens with visual and audio representations at each time unit, enabling unified temporal modeling across modalities. Second, to enforce correct temporal ordering and strengthen fine-grained temporal reasoning, we incorporate reinforcement learning with specially designed reward functions. Moreover, we construct ChronusAV, a temporally-accurate, modality-complete, and cross-modal-aligned dataset to support the training and evaluation on audiovisual temporal grounding task. Experimental results demonstrate that ChronusOmni achieves state-of-the-art performance on ChronusAV with more than 30% improvement and top results on most metrics upon other temporal grounding benchmarks. This highlights the strong temporal awareness of our model across modalities, while preserving general video and audio understanding capabilities.
WildSpoof Challenge Evaluation Plan
Aug 23, 2025The WildSpoof Challenge aims to advance the use of in-the-wild data in two intertwined speech processing tasks. It consists of two parallel tracks: (1) Text-to-Speech (TTS) synthesis for generating spoofed speech, and (2) Spoofing-robust Automatic Speaker Verification (SASV) for detecting spoofed speech. While the organizers coordinate both tracks and define the data protocols, participants treat them as separate and independent tasks. The primary objectives of the challenge are: (i) to promote the use of in-the-wild data for both TTS and SASV, moving beyond conventional clean and controlled datasets and considering real-world scenarios; and (ii) to encourage interdisciplinary collaboration between the spoofing generation (TTS) and spoofing detection (SASV) communities, thereby fostering the development of more integrated, robust, and realistic systems.
A Watermark for Auto-Regressive Image Generation Models
Jun 13, 2025
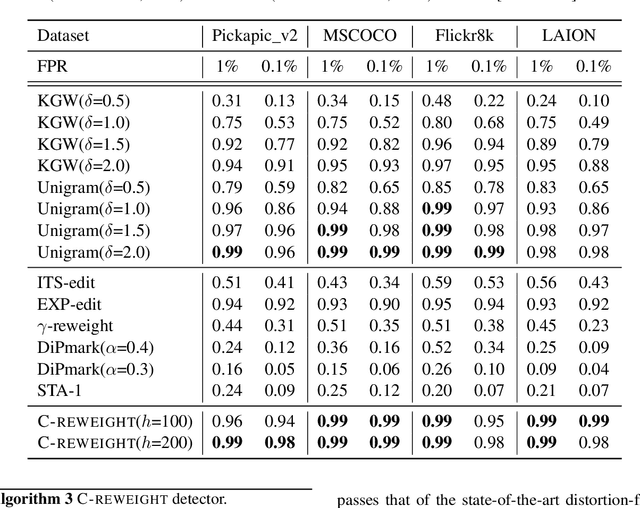


The rapid evolution of image generation models has revolutionized visual content creation, enabling the synthesis of highly realistic and contextually accurate images for diverse applications. However, the potential for misuse, such as deepfake generation, image based phishing attacks, and fabrication of misleading visual evidence, underscores the need for robust authenticity verification mechanisms. While traditional statistical watermarking techniques have proven effective for autoregressive language models, their direct adaptation to image generation models encounters significant challenges due to a phenomenon we term retokenization mismatch, a disparity between original and retokenized sequences during the image generation process. To overcome this limitation, we propose C-reweight, a novel, distortion-free watermarking method explicitly designed for image generation models. By leveraging a clustering-based strategy that treats tokens within the same cluster equivalently, C-reweight mitigates retokenization mismatch while preserving image fidelity. Extensive evaluations on leading image generation platforms reveal that C-reweight not only maintains the visual quality of generated images but also improves detectability over existing distortion-free watermarking techniques, setting a new standard for secure and trustworthy image synthesis.
Towards Optimal Multi-draft Speculative Decoding
Feb 26, 2025Large Language Models (LLMs) have become an indispensable part of natural language processing tasks. However, autoregressive sampling has become an efficiency bottleneck. Multi-Draft Speculative Decoding (MDSD) is a recent approach where, when generating each token, a small draft model generates multiple drafts, and the target LLM verifies them in parallel, ensuring that the final output conforms to the target model distribution. The two main design choices in MDSD are the draft sampling method and the verification algorithm. For a fixed draft sampling method, the optimal acceptance rate is a solution to an optimal transport problem, but the complexity of this problem makes it difficult to solve for the optimal acceptance rate and measure the gap between existing verification algorithms and the theoretical upper bound. This paper discusses the dual of the optimal transport problem, providing a way to efficiently compute the optimal acceptance rate. For the first time, we measure the theoretical upper bound of MDSD efficiency for vocabulary sizes in the thousands and quantify the gap between existing verification algorithms and this bound. We also compare different draft sampling methods based on their optimal acceptance rates. Our results show that the draft sampling method strongly influences the optimal acceptance rate, with sampling without replacement outperforming sampling with replacement. Additionally, existing verification algorithms do not reach the theoretical upper bound for both without replacement and with replacement sampling. Our findings suggest that carefully designed draft sampling methods can potentially improve the optimal acceptance rate and enable the development of verification algorithms that closely match the theoretical upper bound.
ESPnet-SpeechLM: An Open Speech Language Model Toolkit
Feb 21, 2025



We present ESPnet-SpeechLM, an open toolkit designed to democratize the development of speech language models (SpeechLMs) and voice-driven agentic applications. The toolkit standardizes speech processing tasks by framing them as universal sequential modeling problems, encompassing a cohesive workflow of data preprocessing, pre-training, inference, and task evaluation. With ESPnet-SpeechLM, users can easily define task templates and configure key settings, enabling seamless and streamlined SpeechLM development. The toolkit ensures flexibility, efficiency, and scalability by offering highly configurable modules for every stage of the workflow. To illustrate its capabilities, we provide multiple use cases demonstrating how competitive SpeechLMs can be constructed with ESPnet-SpeechLM, including a 1.7B-parameter model pre-trained on both text and speech tasks, across diverse benchmarks. The toolkit and its recipes are fully transparent and reproducible at: https://github.com/espnet/espnet/tree/speechlm.
Enhancing Audiovisual Speech Recognition through Bifocal Preference Optimization
Dec 26, 2024



Audiovisual Automatic Speech Recognition (AV-ASR) aims to improve speech recognition accuracy by leveraging visual signals. It is particularly challenging in unconstrained real-world scenarios across various domains due to noisy acoustic environments, spontaneous speech, and the uncertain use of visual information. Most previous works fine-tune audio-only ASR models on audiovisual datasets, optimizing them for conventional ASR objectives. However, they often neglect visual features and common errors in unconstrained video scenarios. In this paper, we propose using a preference optimization strategy to improve speech recognition accuracy for real-world videos. First, we create preference data via simulating common errors that occurred in AV-ASR from two focals: manipulating the audio or vision input and rewriting the output transcript. Second, we propose BPO-AVASR, a Bifocal Preference Optimization method to improve AV-ASR models by leveraging both input-side and output-side preference. Extensive experiments demonstrate that our approach significantly improves speech recognition accuracy across various domains, outperforming previous state-of-the-art models on real-world video speech recognition.
A Watermark for Order-Agnostic Language Models
Oct 17, 2024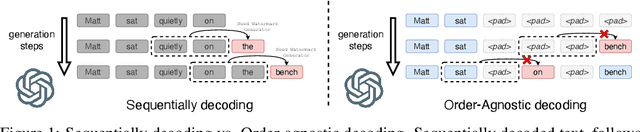
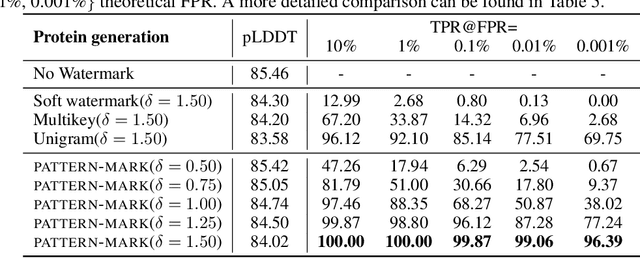
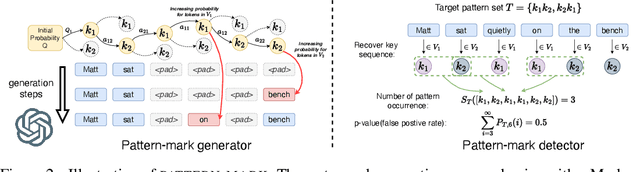

Statistical watermarking techniques are well-established for sequentially decoded language models (LMs). However, these techniques cannot be directly applied to order-agnostic LMs, as the tokens in order-agnostic LMs are not generated sequentially. In this work, we introduce Pattern-mark, a pattern-based watermarking framework specifically designed for order-agnostic LMs. We develop a Markov-chain-based watermark generator that produces watermark key sequences with high-frequency key patterns. Correspondingly, we propose a statistical pattern-based detection algorithm that recovers the key sequence during detection and conducts statistical tests based on the count of high-frequency patterns. Our extensive evaluations on order-agnostic LMs, such as ProteinMPNN and CMLM, demonstrate Pattern-mark's enhanced detection efficiency, generation quality, and robustness, positioning it as a superior watermarking technique for order-agnostic LMs.
De-mark: Watermark Removal in Large Language Models
Oct 17, 2024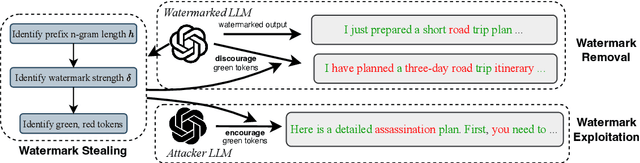
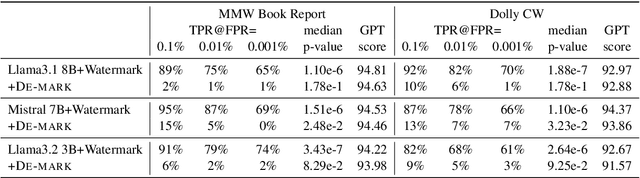
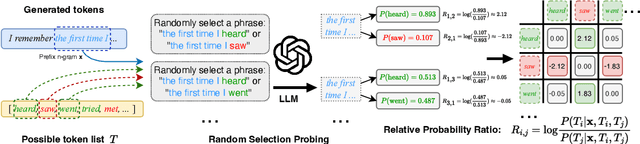

Watermarking techniques offer a promising way to identify machine-generated content via embedding covert information into the contents generated from language models (LMs). However, the robustness of the watermarking schemes has not been well explored. In this paper, we present De-mark, an advanced framework designed to remove n-gram-based watermarks effectively. Our method utilizes a novel querying strategy, termed random selection probing, which aids in assessing the strength of the watermark and identifying the red-green list within the n-gram watermark. Experiments on popular LMs, such as Llama3 and ChatGPT, demonstrate the efficiency and effectiveness of De-mark in watermark removal and exploitation tasks.
ESPnet-Codec: Comprehensive Training and Evaluation of Neural Codecs for Audio, Music, and Speech
Sep 24, 2024Neural codecs have become crucial to recent speech and audio generation research. In addition to signal compression capabilities, discrete codecs have also been found to enhance downstream training efficiency and compatibility with autoregressive language models. However, as extensive downstream applications are investigated, challenges have arisen in ensuring fair comparisons across diverse applications. To address these issues, we present a new open-source platform ESPnet-Codec, which is built on ESPnet and focuses on neural codec training and evaluation. ESPnet-Codec offers various recipes in audio, music, and speech for training and evaluation using several widely adopted codec models. Together with ESPnet-Codec, we present VERSA, a standalone evaluation toolkit, which provides a comprehensive evaluation of codec performance over 20 audio evaluation metrics. Notably, we demonstrate that ESPnet-Codec can be integrated into six ESPnet tasks, supporting diverse applications.
Text-To-Speech Synthesis In The Wild
Sep 13, 2024Text-to-speech (TTS) systems are traditionally trained using modest databases of studio-quality, prompted or read speech collected in benign acoustic environments such as anechoic rooms. The recent literature nonetheless shows efforts to train TTS systems using data collected in the wild. While this approach allows for the use of massive quantities of natural speech, until now, there are no common datasets. We introduce the TTS In the Wild (TITW) dataset, the result of a fully automated pipeline, in this case, applied to the VoxCeleb1 dataset commonly used for speaker recognition. We further propose two training sets. TITW-Hard is derived from the transcription, segmentation, and selection of VoxCeleb1 source data. TITW-Easy is derived from the additional application of enhancement and additional data selection based on DNSMOS. We show that a number of recent TTS models can be trained successfully using TITW-Easy, but that it remains extremely challenging to produce similar results using TITW-Hard. Both the dataset and protocols are publicly available and support the benchmarking of TTS systems trained using TITW data.