 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredictive-Generative Drift Decomposition for Speech Enhancement and Separation
May 07, 2026We propose a plug-and-play framework for speech enhancement and separation that augments predictive methods with a generative speech prior. Our approach, termed Stochastic Interpolant Prior for Speech (SIPS), builds on stochastic interpolants and leverages their flexibility to bridge predictive and generative modeling. Specifically, we decompose the interpolation dynamics into a task-specific drift and a stochastic denoising component, allowing a predictive estimate to be integrated directly into the generative sampling process. This results in a mathematically grounded framework for combining strong pretrained predictors with the expressive power of generative models. To this end, we train a score model using only clean speech, yielding a degradation-agnostic prior that can be reused across tasks. During inference, the predictor provides a deterministic drift that steers the sampling process toward a task-consistent estimate, while the score model preserves perceptual naturalness. Unlike prior hybrid approaches, which typically rely on architecture-specific conditioning and are tied to particular predictors or degradation settings, SIPS provides a unified framework that generalizes across predictors and additive degradation tasks. We demonstrate its effectiveness for both speech enhancement and speech separation using recent predictors such as SEMamba and FlexIO. The proposed method consistently improves perceptual quality, achieving gains up +1.0 NISQA for speech separation.
Velocity Potential Neural Field for Efficient Ambisonics Impulse Response Modeling
Mar 23, 2026First-order Ambisonics (FOA) is a standard spatial audio format based on spherical harmonic decomposition. Its zeroth- and first-order components capture the sound pressure and particle velocity, respectively. Recently, physics-informed neural networks have been applied to the spatial interpolation of FOA signals, regularizing the network outputs based on soft penalty terms derived from physical principles, e.g., the linearized momentum equation. In this paper, we reformulate the task so that the predicted FOA signal automatically satisfies the linearized momentum equation. Our network approximates a scalar function called velocity potential, rather than the FOA signal itself. Then, the FOA signal can be readily recovered through the partial derivatives of the velocity potential with respect to the network inputs (i.e., time and microphone position) according to physics of sound propagation. By deriving the four channels of FOA from the single-channel velocity potential, the reconstructed signal follows the physical principle at any time and position by construction. Experimental results on room impulse response reconstruction confirm the effectiveness of the proposed framework.
FlexIO: Flexible Single- and Multi-Channel Speech Separation and Enhancement
Oct 24, 2025Speech separation and enhancement (SSE) has advanced remarkably and achieved promising results in controlled settings, such as a fixed number of speakers and a fixed array configuration. Towards a universal SSE system, single-channel systems have been extended to deal with a variable number of speakers (i.e., outputs). Meanwhile, multi-channel systems accommodating various array configurations (i.e., inputs) have been developed. However, these attempts have been pursued separately. In this paper, we propose a flexible input and output SSE system, named FlexIO. It performs conditional separation using prompt vectors, one per speaker as a condition, allowing separation of an arbitrary number of speakers. Multi-channel mixtures are processed together with the prompt vectors via an array-agnostic channel communication mechanism. Our experiments demonstrate that FlexIO successfully covers diverse conditions with one to five microphones and one to three speakers. We also confirm the robustness of FlexIO on CHiME-4 real data.
Exploring Disentangled Neural Speech Codecs from Self-Supervised Representations
Aug 11, 2025Neural audio codecs (NACs), which use neural networks to generate compact audio representations, have garnered interest for their applicability to many downstream tasks -- especially quantized codecs due to their compatibility with large language models. However, unlike text, speech conveys not only linguistic content but also rich paralinguistic features. Encoding these elements in an entangled fashion may be suboptimal, as it limits flexibility. For instance, voice conversion (VC) aims to convert speaker characteristics while preserving the original linguistic content, which requires a disentangled representation. Inspired by VC methods utilizing $k$-means quantization with self-supervised features to disentangle phonetic information, we develop a discrete NAC capable of structured disentanglement. Experimental evaluations show that our approach achieves reconstruction performance on par with conventional NACs that do not explicitly perform disentanglement, while also matching the effectiveness of conventional VC techniques.
FasTUSS: Faster Task-Aware Unified Source Separation
Jul 15, 2025Time-Frequency (TF) dual-path models are currently among the best performing audio source separation network architectures, achieving state-of-the-art performance in speech enhancement, music source separation, and cinematic audio source separation. While they are characterized by a relatively low parameter count, they still require a considerable number of operations, implying a higher execution time. This problem is exacerbated by the trend towards bigger models trained on large amounts of data to solve more general tasks, such as the recently introduced task-aware unified source separation (TUSS) model. TUSS, which aims to solve audio source separation tasks using a single, conditional model, is built upon TF-Locoformer, a TF dual-path model combining convolution and attention layers. The task definition comes in the form of a sequence of prompts that specify the number and type of sources to be extracted. In this paper, we analyze the design choices of TUSS with the goal of optimizing its performance-complexity trade-off. We derive two more efficient models, FasTUSS-8.3G and FasTUSS-11.7G that reduce the original model's operations by 81\% and 73\% with minor performance drops of 1.2~dB and 0.4~dB averaged over all benchmarks, respectively. Additionally, we investigate the impact of prompt conditioning to derive a causal TUSS model.
Physics-Informed Direction-Aware Neural Acoustic Fields
Jul 09, 2025
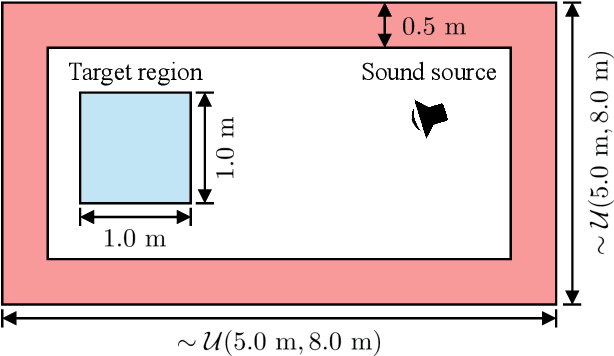
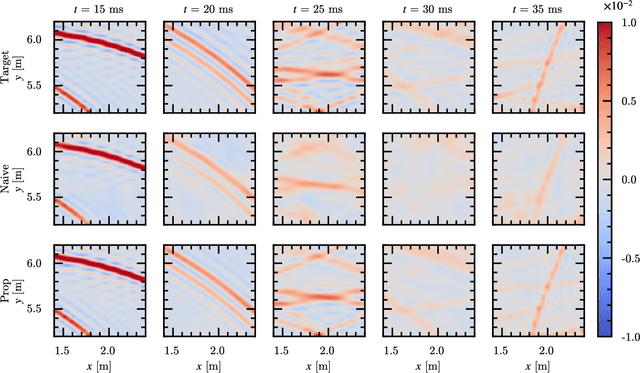

This paper presents a physics-informed neural network (PINN) for modeling first-order Ambisonic (FOA) room impulse responses (RIRs). PINNs have demonstrated promising performance in sound field interpolation by combining the powerful modeling capability of neural networks and the physical principles of sound propagation. In room acoustics, PINNs have typically been trained to represent the sound pressure measured by omnidirectional microphones where the wave equation or its frequency-domain counterpart, i.e., the Helmholtz equation, is leveraged. Meanwhile, FOA RIRs additionally provide spatial characteristics and are useful for immersive audio generation with a wide range of applications. In this paper, we extend the PINN framework to model FOA RIRs. We derive two physics-informed priors for FOA RIRs based on the correspondence between the particle velocity and the (X, Y, Z)-channels of FOA. These priors associate the predicted W-channel and other channels through their partial derivatives and impose the physically feasible relationship on the four channels. Our experiments confirm the effectiveness of the proposed method compared with a neural network without the physics-informed prior.
Factorized RVQ-GAN For Disentangled Speech Tokenization
Jun 18, 2025We propose Hierarchical Audio Codec (HAC), a unified neural speech codec that factorizes its bottleneck into three linguistic levels-acoustic, phonetic, and lexical-within a single model. HAC leverages two knowledge distillation objectives: one from a pre-trained speech encoder (HuBERT) for phoneme-level structure, and another from a text-based encoder (LaBSE) for lexical cues. Experiments on English and multilingual data show that HAC's factorized bottleneck yields disentangled token sets: one aligns with phonemes, while another captures word-level semantics. Quantitative evaluations confirm that HAC tokens preserve naturalness and provide interpretable linguistic information, outperforming single-level baselines in both disentanglement and reconstruction quality. These findings underscore HAC's potential as a unified discrete speech representation, bridging acoustic detail and lexical meaning for downstream speech generation and understanding tasks.
Direction-Aware Neural Acoustic Fields for Few-Shot Interpolation of Ambisonic Impulse Responses
May 19, 2025



The characteristics of a sound field are intrinsically linked to the geometric and spatial properties of the environment surrounding a sound source and a listener. The physics of sound propagation is captured in a time-domain signal known as a room impulse response (RIR). Prior work using neural fields (NFs) has allowed learning spatially-continuous representations of RIRs from finite RIR measurements. However, previous NF-based methods have focused on monaural omnidirectional or at most binaural listeners, which does not precisely capture the directional characteristics of a real sound field at a single point. We propose a direction-aware neural field (DANF) that more explicitly incorporates the directional information by Ambisonic-format RIRs. While DANF inherently captures spatial relations between sources and listeners, we further propose a direction-aware loss. In addition, we investigate the ability of DANF to adapt to new rooms in various ways including low-rank adaptation.
Data Augmentation Using Neural Acoustic Fields With Retrieval-Augmented Pre-training
Apr 19, 2025


This report details MERL's system for room impulse response (RIR) estimation submitted to the Generative Data Augmentation Workshop at ICASSP 2025 for Augmenting RIR Data (Task 1) and Improving Speaker Distance Estimation (Task 2). We first pre-train a neural acoustic field conditioned by room geometry on an external large-scale dataset in which pairs of RIRs and the geometries are provided. The neural acoustic field is then adapted to each target room by using the enrollment data, where we leverage either the provided room geometries or geometries retrieved from the external dataset, depending on availability. Lastly, we predict the RIRs for each pair of source and receiver locations specified by Task 1, and use these RIRs to train the speaker distance estimation model in Task 2.
ESPnet-SpeechLM: An Open Speech Language Model Toolkit
Feb 21, 2025



We present ESPnet-SpeechLM, an open toolkit designed to democratize the development of speech language models (SpeechLMs) and voice-driven agentic applications. The toolkit standardizes speech processing tasks by framing them as universal sequential modeling problems, encompassing a cohesive workflow of data preprocessing, pre-training, inference, and task evaluation. With ESPnet-SpeechLM, users can easily define task templates and configure key settings, enabling seamless and streamlined SpeechLM development. The toolkit ensures flexibility, efficiency, and scalability by offering highly configurable modules for every stage of the workflow. To illustrate its capabilities, we provide multiple use cases demonstrating how competitive SpeechLMs can be constructed with ESPnet-SpeechLM, including a 1.7B-parameter model pre-trained on both text and speech tasks, across diverse benchmarks. The toolkit and its recipes are fully transparent and reproducible at: https://github.com/espnet/espnet/tree/speechlm.