 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFactorized RVQ-GAN For Disentangled Speech Tokenization
Jun 18, 2025We propose Hierarchical Audio Codec (HAC), a unified neural speech codec that factorizes its bottleneck into three linguistic levels-acoustic, phonetic, and lexical-within a single model. HAC leverages two knowledge distillation objectives: one from a pre-trained speech encoder (HuBERT) for phoneme-level structure, and another from a text-based encoder (LaBSE) for lexical cues. Experiments on English and multilingual data show that HAC's factorized bottleneck yields disentangled token sets: one aligns with phonemes, while another captures word-level semantics. Quantitative evaluations confirm that HAC tokens preserve naturalness and provide interpretable linguistic information, outperforming single-level baselines in both disentanglement and reconstruction quality. These findings underscore HAC's potential as a unified discrete speech representation, bridging acoustic detail and lexical meaning for downstream speech generation and understanding tasks.
Light and 3D: a methodological exploration of digitisation techniques adapted to a selection of objects from the Mus{é}e d'Arch{é}ologie Nationale
Jun 05, 2025The need to digitize heritage objects is now widely accepted. This article presents the very fashionable context of the creation of ''digital twins''. It illustrates the diversity of photographic 3D digitization methods, but this is not its only objective. Using a selection of objects from the collections of the mus{\'e}e d'Arch{\'e}ologie nationale, it shows that no single method is suitable for all cases. Rather, the method to be recommended for a given object should be the result of a concerted choice between those involved in heritage and those involved in the digital domain, as each new object may require the adaptation of existing tools. It would therefore be pointless to attempt an absolute classification of 3D digitization methods. On the contrary, we need to find the digital tool best suited to each object, taking into account not only its characteristics, but also the future use of its digital twin.
* in French language
Text-Speech Language Models with Improved Cross-Modal Transfer by Aligning Abstraction Levels
Mar 08, 2025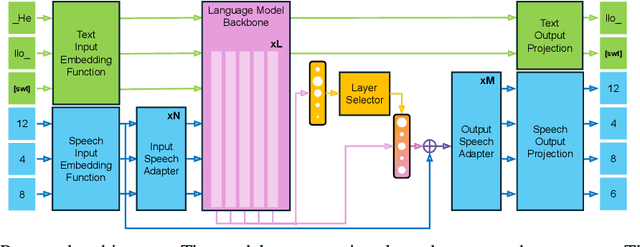
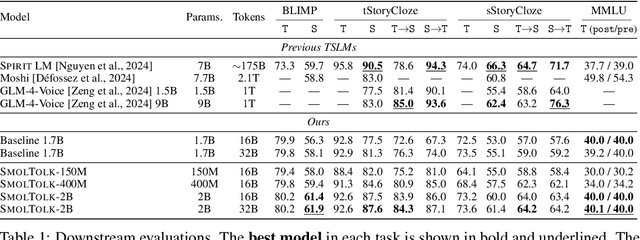
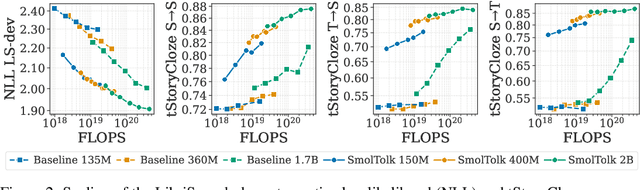
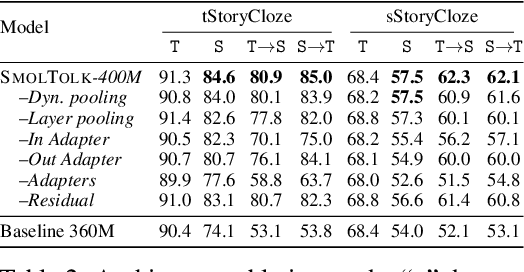
Text-Speech Language Models (TSLMs) -- language models trained to jointly process and generate text and speech -- aim to enable cross-modal knowledge transfer to overcome the scaling limitations of unimodal speech LMs. The predominant approach to TSLM training expands the vocabulary of a pre-trained text LM by appending new embeddings and linear projections for speech, followed by fine-tuning on speech data. We hypothesize that this method limits cross-modal transfer by neglecting feature compositionality, preventing text-learned functions from being fully leveraged at appropriate abstraction levels. To address this, we propose augmenting vocabulary expansion with modules that better align abstraction levels across layers. Our models, \textsc{SmolTolk}, rival or surpass state-of-the-art TSLMs trained with orders of magnitude more compute. Representation analyses and improved multimodal performance suggest our method enhances cross-modal transfer.
Detecting the terminality of speech-turn boundary for spoken interactions in French TV and Radio content
Jun 14, 2024



Transition Relevance Places are defined as the end of an utterance where the interlocutor may take the floor without interrupting the current speaker --i.e., a place where the turn is terminal. Analyzing turn terminality is useful to study the dynamic of turn-taking in spontaneous conversations. This paper presents an automatic classification of spoken utterances as Terminal or Non-Terminal in multi-speaker settings. We compared audio, text, and fusions of both approaches on a French corpus of TV and Radio extracts annotated with turn-terminality information at each speaker change. Our models are based on pre-trained self-supervised representations. We report results for different fusion strategies and varying context sizes. This study also questions the problem of performance variability by analyzing the differences in results for multiple training runs with random initialization. The measured accuracy would allow the use of these models for large-scale analysis of turn-taking.
A Semi-Automatic Approach to Create Large Gender- and Age-Balanced Speaker Corpora: Usefulness of Speaker Diarization & Identification
Apr 26, 2024This paper presents a semi-automatic approach to create a diachronic corpus of voices balanced for speaker's age, gender, and recording period, according to 32 categories (2 genders, 4 age ranges and 4 recording periods). Corpora were selected at French National Institute of Audiovisual (INA) to obtain at least 30 speakers per category (a total of 960 speakers; only 874 have be found yet). For each speaker, speech excerpts were extracted from audiovisual documents using an automatic pipeline consisting of speech detection, background music and overlapped speech removal and speaker diarization, used to present clean speaker segments to human annotators identifying target speakers. This pipeline proved highly effective, cutting down manual processing by a factor of ten. Evaluation of the quality of the automatic processing and of the final output is provided. It shows the automatic processing compare to up-to-date process, and that the output provides high quality speech for most of the selected excerpts. This method shows promise for creating large corpora of known target speakers.
* Keywords:, semi-automatic processing, corpus creation, diarization, speaker identification, gender-balanced, age-balanced, speaker corpus, diachrony
Direct Text to Speech Translation System using Acoustic Units
Sep 14, 2023This paper proposes a direct text to speech translation system using discrete acoustic units. This framework employs text in different source languages as input to generate speech in the target language without the need for text transcriptions in this language. Motivated by the success of acoustic units in previous works for direct speech to speech translation systems, we use the same pipeline to extract the acoustic units using a speech encoder combined with a clustering algorithm. Once units are obtained, an encoder-decoder architecture is trained to predict them. Then a vocoder generates speech from units. Our approach for direct text to speech translation was tested on the new CVSS corpus with two different text mBART models employed as initialisation. The systems presented report competitive performance for most of the language pairs evaluated. Besides, results show a remarkable improvement when initialising our proposed architecture with a model pre-trained with more languages.
Joint speech and overlap detection: a benchmark over multiple audio setup and speech domains
Jul 24, 2023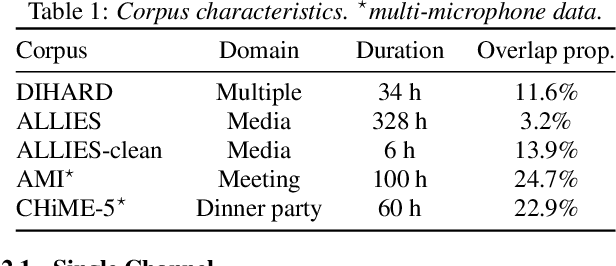
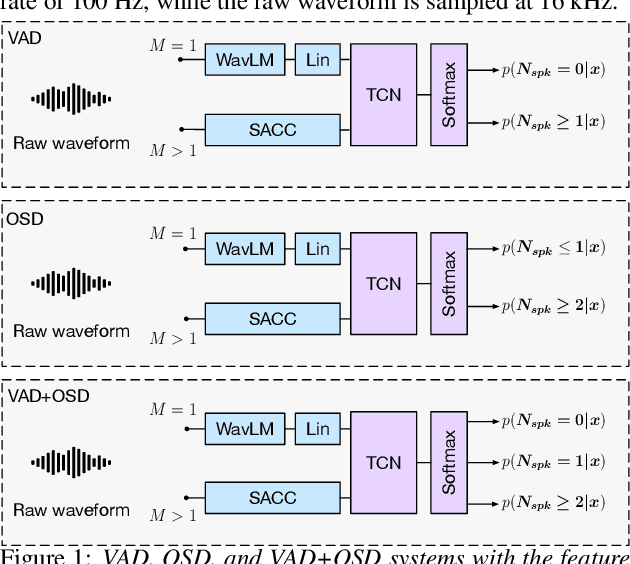

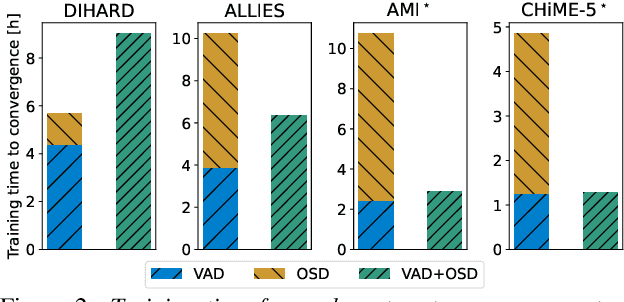
Voice activity and overlapped speech detection (respectively VAD and OSD) are key pre-processing tasks for speaker diarization. The final segmentation performance highly relies on the robustness of these sub-tasks. Recent studies have shown VAD and OSD can be trained jointly using a multi-class classification model. However, these works are often restricted to a specific speech domain, lacking information about the generalization capacities of the systems. This paper proposes a complete and new benchmark of different VAD and OSD models, on multiple audio setups (single/multi-channel) and speech domains (e.g. media, meeting...). Our 2/3-class systems, which combine a Temporal Convolutional Network with speech representations adapted to the setup, outperform state-of-the-art results. We show that the joint training of these two tasks offers similar performances in terms of F1-score to two dedicated VAD and OSD systems while reducing the training cost. This unique architecture can also be used for single and multichannel speech processing.
Improved Cross-Lingual Transfer Learning For Automatic Speech Translation
Jun 01, 2023Research in multilingual speech-to-text translation is topical. Having a single model that supports multiple translation tasks is desirable. The goal of this work it to improve cross-lingual transfer learning in multilingual speech-to-text translation via semantic knowledge distillation. We show that by initializing the encoder of the encoder-decoder sequence-to-sequence translation model with SAMU-XLS-R, a multilingual speech transformer encoder trained using multi-modal (speech-text) semantic knowledge distillation, we achieve significantly better cross-lingual task knowledge transfer than the baseline XLS-R, a multilingual speech transformer encoder trained via self-supervised learning. We demonstrate the effectiveness of our approach on two popular datasets, namely, CoVoST-2 and Europarl. On the 21 translation tasks of the CoVoST-2 benchmark, we achieve an average improvement of 12.8 BLEU points over the baselines. In the zero-shot translation scenario, we achieve an average gain of 18.8 and 11.9 average BLEU points on unseen medium and low-resource languages. We make similar observations on Europarl speech translation benchmark.
On Unsupervised Uncertainty-Driven Speech Pseudo-Label Filtering and Model Calibration
Nov 14, 2022



Pseudo-label (PL) filtering forms a crucial part of Self-Training (ST) methods for unsupervised domain adaptation. Dropout-based Uncertainty-driven Self-Training (DUST) proceeds by first training a teacher model on source domain labeled data. Then, the teacher model is used to provide PLs for the unlabeled target domain data. Finally, we train a student on augmented labeled and pseudo-labeled data. The process is iterative, where the student becomes the teacher for the next DUST iteration. A crucial step that precedes the student model training in each DUST iteration is filtering out noisy PLs that could lead the student model astray. In DUST, we proposed a simple, effective, and theoretically sound PL filtering strategy based on the teacher model's uncertainty about its predictions on unlabeled speech utterances. We estimate the model's uncertainty by computing disagreement amongst multiple samples drawn from the teacher model during inference by injecting noise via dropout. In this work, we show that DUST's PL filtering, as initially used, may fail under severe source and target domain mismatch. We suggest several approaches to eliminate or alleviate this issue. Further, we bring insights from the research in neural network model calibration to DUST and show that a well-calibrated model correlates strongly with a positive outcome of the DUST PL filtering step.
Overlapped speech and gender detection with WavLM pre-trained features
Sep 09, 2022
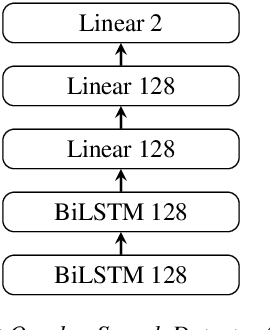

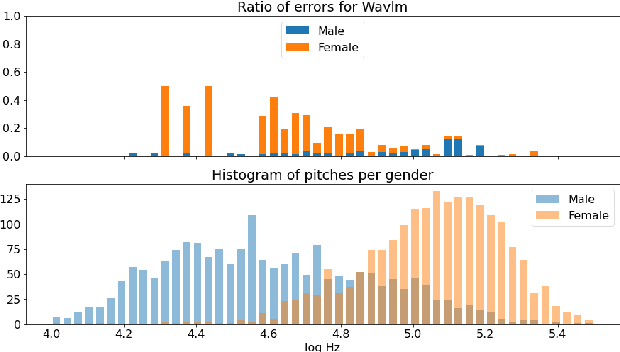
This article focuses on overlapped speech and gender detection in order to study interactions between women and men in French audiovisual media (Gender Equality Monitoring project). In this application context, we need to automatically segment the speech signal according to speakers gender, and to identify when at least two speakers speak at the same time. We propose to use WavLM model which has the advantage of being pre-trained on a huge amount of speech data, to build an overlapped speech detection (OSD) and a gender detection (GD) systems. In this study, we use two different corpora. The DIHARD III corpus which is well adapted for the OSD task but lack gender information. The ALLIES corpus fits with the project application context. Our best OSD system is a Temporal Convolutional Network (TCN) with WavLM pre-trained features as input, which reaches a new state-of-the-art F1-score performance on DIHARD. A neural GD is trained with WavLM inputs on a gender balanced subset of the French broadcast news ALLIES data, and obtains an accuracy of 97.9%. This work opens new perspectives for human science researchers regarding the differences of representation between women and men in French media.