 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASoBO: Attentive Beamformer Selection for Distant Speaker Diarization in Meetings
Jun 05, 2024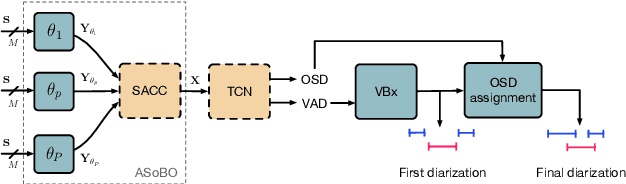
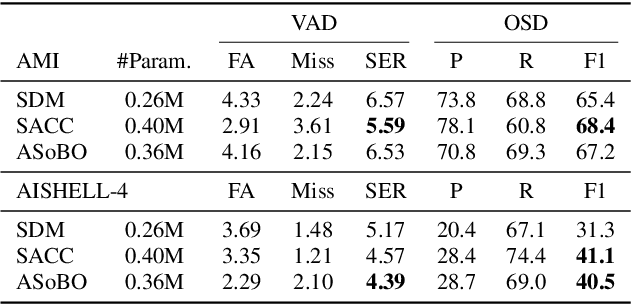
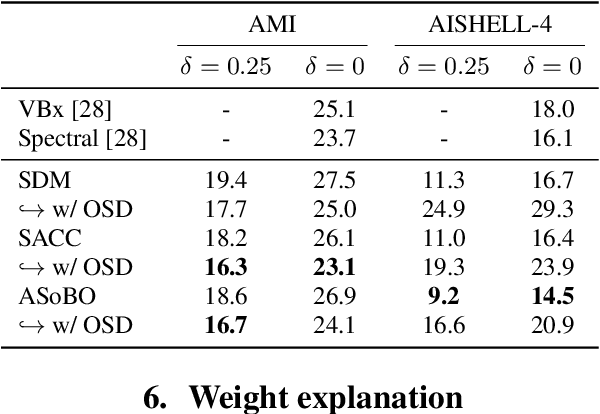
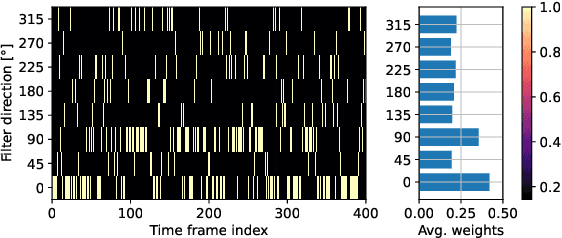
Speaker Diarization (SD) aims at grouping speech segments that belong to the same speaker. This task is required in many speech-processing applications, such as rich meeting transcription. In this context, distant microphone arrays usually capture the audio signal. Beamforming, i.e., spatial filtering, is a common practice to process multi-microphone audio data. However, it often requires an explicit localization of the active source to steer the filter. This paper proposes a self-attention-based algorithm to select the output of a bank of fixed spatial filters. This method serves as a feature extractor for joint Voice Activity (VAD) and Overlapped Speech Detection (OSD). The speaker diarization is then inferred from the detected segments. The approach shows convincing distant VAD, OSD, and SD performance, e.g. 14.5% DER on the AISHELL-4 dataset. The analysis of the self-attention weights demonstrates their explainability, as they correlate with the speaker's angular locations.
Channel-Combination Algorithms for Robust Distant Voice Activity and Overlapped Speech Detection
Feb 13, 2024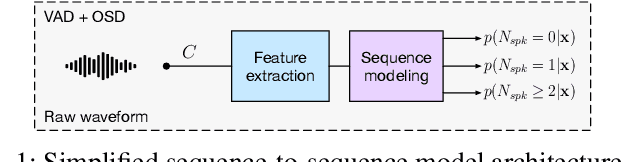
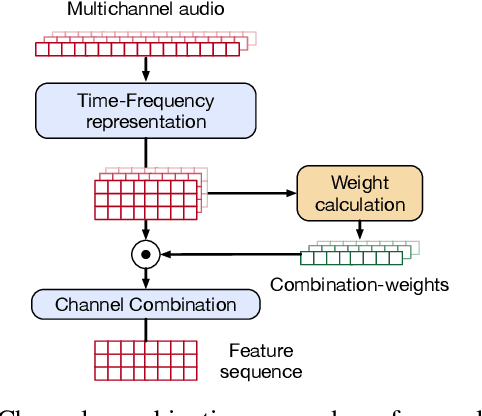
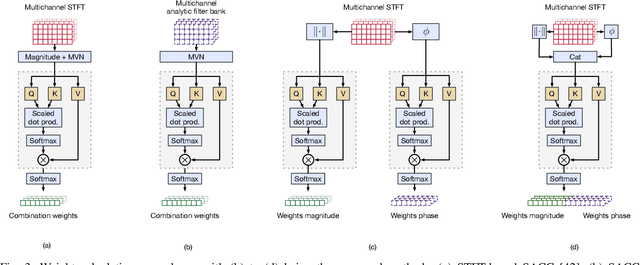

Voice Activity Detection (VAD) and Overlapped Speech Detection (OSD) are key pre-processing tasks for speaker diarization. In the meeting context, it is often easier to capture speech with a distant device. This consideration however leads to severe performance degradation. We study a unified supervised learning framework to solve distant multi-microphone joint VAD and OSD (VAD+OSD). This paper investigates various multi-channel VAD+OSD front-ends that weight and combine incoming channels. We propose three algorithms based on the Self-Attention Channel Combinator (SACC), previously proposed in the literature. Experiments conducted on the AMI meeting corpus exhibit that channel combination approaches bring significant VAD+OSD improvements in the distant speech scenario. Specifically, we explore the use of learned complex combination weights and demonstrate the benefits of such an approach in terms of explainability. Channel combination-based VAD+OSD systems are evaluated on the final back-end task, i.e. speaker diarization, and show significant improvements. Finally, since multi-channel systems are trained given a fixed array configuration, they may fail in generalizing to other array set-ups, e.g. mismatched number of microphones. A channel-number invariant loss is proposed to learn a unique feature representation regardless of the number of available microphones. The evaluation conducted on mismatched array configurations highlights the robustness of this training strategy.
Joint speech and overlap detection: a benchmark over multiple audio setup and speech domains
Jul 24, 2023
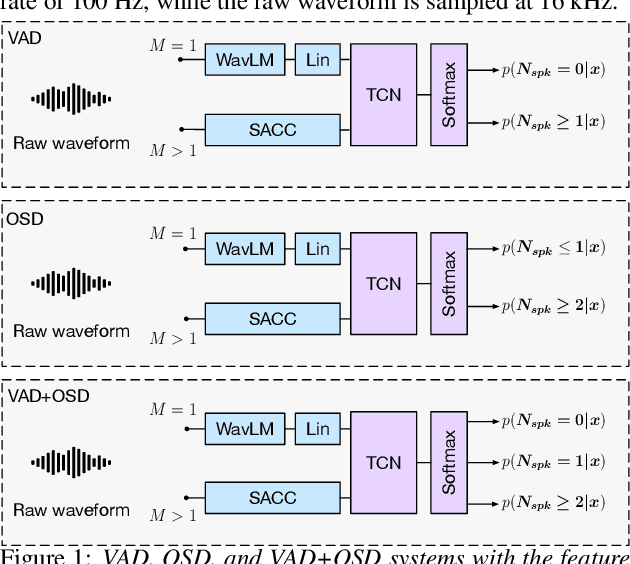

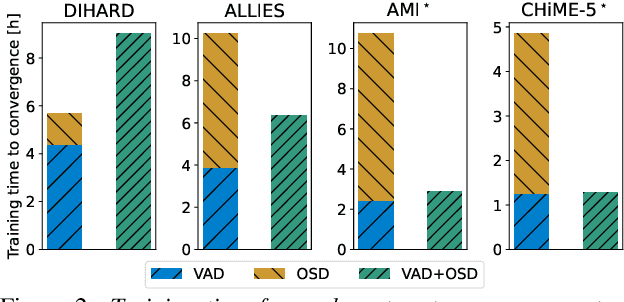
Voice activity and overlapped speech detection (respectively VAD and OSD) are key pre-processing tasks for speaker diarization. The final segmentation performance highly relies on the robustness of these sub-tasks. Recent studies have shown VAD and OSD can be trained jointly using a multi-class classification model. However, these works are often restricted to a specific speech domain, lacking information about the generalization capacities of the systems. This paper proposes a complete and new benchmark of different VAD and OSD models, on multiple audio setups (single/multi-channel) and speech domains (e.g. media, meeting...). Our 2/3-class systems, which combine a Temporal Convolutional Network with speech representations adapted to the setup, outperform state-of-the-art results. We show that the joint training of these two tasks offers similar performances in terms of F1-score to two dedicated VAD and OSD systems while reducing the training cost. This unique architecture can also be used for single and multichannel speech processing.
Multi-microphone Automatic Speech Segmentation in Meetings Based on Circular Harmonics Features
Jun 07, 2023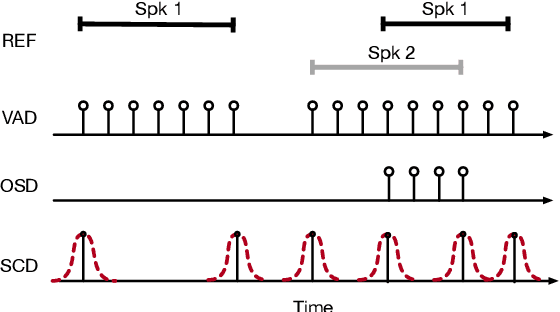
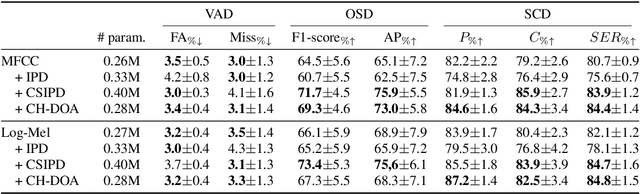
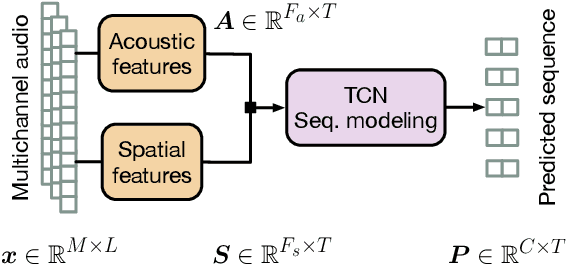
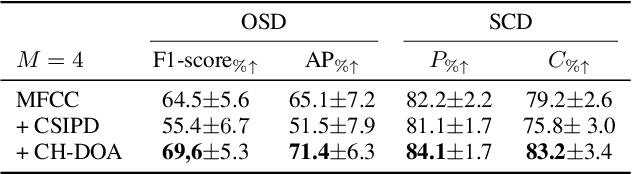
Speaker diarization is the task of answering Who spoke and when? in an audio stream. Pipeline systems rely on speech segmentation to extract speakers' segments and achieve robust speaker diarization. This paper proposes a common framework to solve three segmentation tasks in the distant speech scenario: Voice Activity Detection (VAD), Overlapped Speech Detection (OSD), and Speaker Change Detection (SCD). In the literature, a few studies investigate the multi-microphone distant speech scenario. In this work, we propose a new set of spatial features based on direction-of-arrival estimations in the circular harmonic domain (CH-DOA). These spatial features are extracted from multi-microphone audio data and combined with standard acoustic features. Experiments on the AMI meeting corpus show that CH-DOA can improve the segmentation while being robust in the case of deactivated microphones.