 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Voice Identification after Speech Resynthesis using PPG
Aug 05, 2024Speech resynthesis is a generic task for which we want to synthesize audio with another audio as input, which finds applications for media monitors and journalists.Among different tasks addressed by speech resynthesis, voice conversion preserves the linguistic information while modifying the identity of the speaker, and speech edition preserves the identity of the speaker but some words are modified.In both cases, we need to disentangle speaker and phonetic contents in intermediate representations.Phonetic PosteriorGrams (PPG) are a frame-level probabilistic representation of phonemes, and are usually considered speaker-independent.This paper presents a PPG-based speech resynthesis system.A perceptive evaluation assesses that it produces correct audio quality.Then, we demonstrate that an automatic speaker verification model is not able to recover the source speaker after re-synthesis with PPG, even when the model is trained on synthetic data.
Predefined Prototypes for Intra-Class Separation and Disentanglement
Jun 23, 2024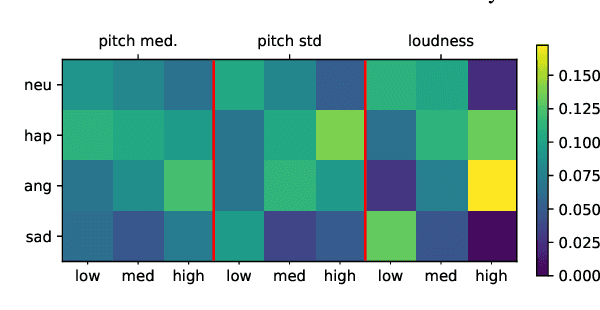
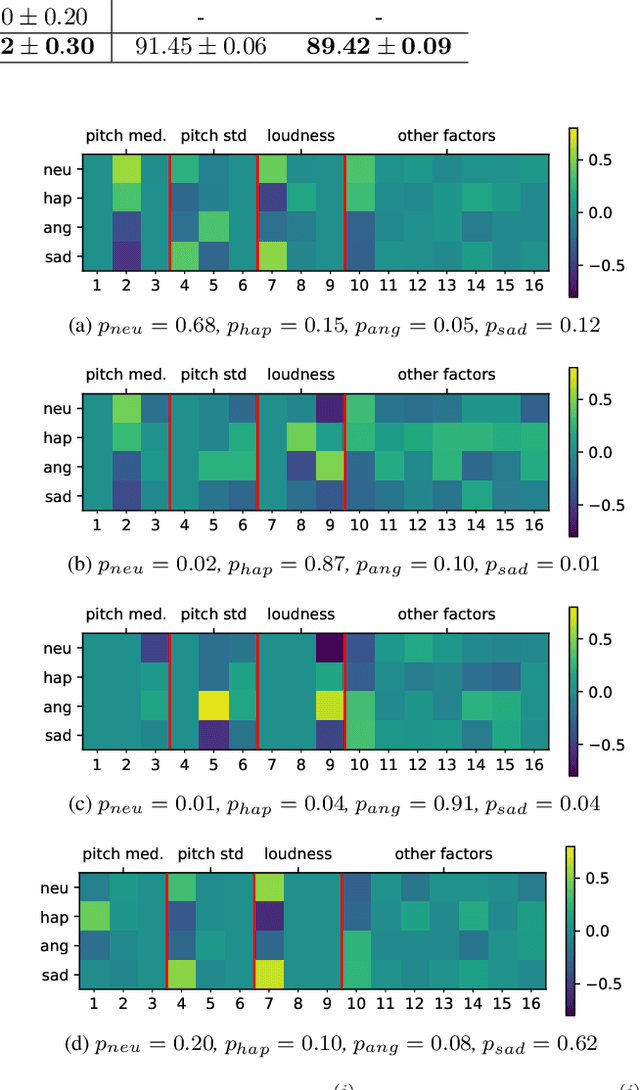
Prototypical Learning is based on the idea that there is a point (which we call prototype) around which the embeddings of a class are clustered. It has shown promising results in scenarios with little labeled data or to design explainable models. Typically, prototypes are either defined as the average of the embeddings of a class or are designed to be trainable. In this work, we propose to predefine prototypes following human-specified criteria, which simplify the training pipeline and brings different advantages. Specifically, in this work we explore two of these advantages: increasing the inter-class separability of embeddings and disentangling embeddings with respect to different variance factors, which can translate into the possibility of having explainable predictions. Finally, we propose different experiments that help to understand our proposal and demonstrate empirically the mentioned advantages.
Explainable by-design Audio Segmentation through Non-Negative Matrix Factorization and Probing
Jun 19, 2024
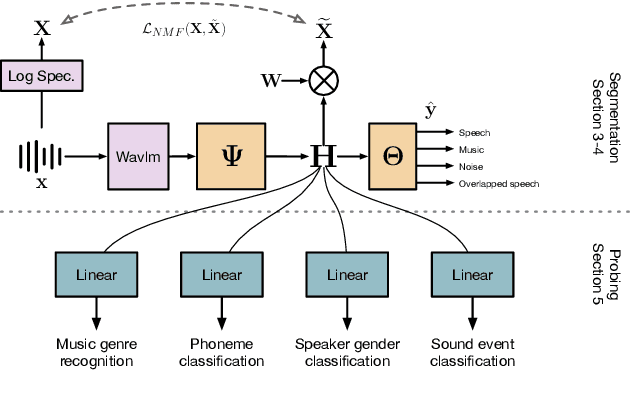
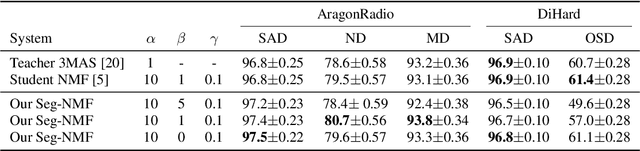
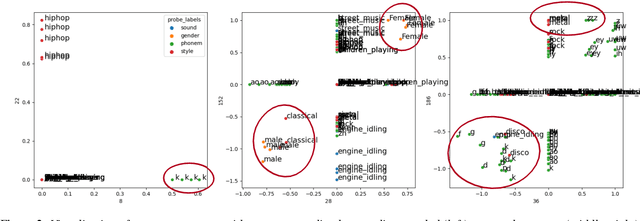
Audio segmentation is a key task for many speech technologies, most of which are based on neural networks, usually considered as black boxes, with high-level performances. However, in many domains, among which health or forensics, there is not only a need for good performance but also for explanations about the output decision. Explanations derived directly from latent representations need to satisfy "good" properties, such as informativeness, compactness, or modularity, to be interpretable. In this article, we propose an explainable-by-design audio segmentation model based on non-negative matrix factorization (NMF) which is a good candidate for the design of interpretable representations. This paper shows that our model reaches good segmentation performances, and presents deep analyses of the latent representation extracted from the non-negative matrix. The proposed approach opens new perspectives toward the evaluation of interpretable representations according to "good" properties.
Detecting the terminality of speech-turn boundary for spoken interactions in French TV and Radio content
Jun 14, 2024



Transition Relevance Places are defined as the end of an utterance where the interlocutor may take the floor without interrupting the current speaker --i.e., a place where the turn is terminal. Analyzing turn terminality is useful to study the dynamic of turn-taking in spontaneous conversations. This paper presents an automatic classification of spoken utterances as Terminal or Non-Terminal in multi-speaker settings. We compared audio, text, and fusions of both approaches on a French corpus of TV and Radio extracts annotated with turn-terminality information at each speaker change. Our models are based on pre-trained self-supervised representations. We report results for different fusion strategies and varying context sizes. This study also questions the problem of performance variability by analyzing the differences in results for multiple training runs with random initialization. The measured accuracy would allow the use of these models for large-scale analysis of turn-taking.
A Semi-Automatic Approach to Create Large Gender- and Age-Balanced Speaker Corpora: Usefulness of Speaker Diarization & Identification
Apr 26, 2024This paper presents a semi-automatic approach to create a diachronic corpus of voices balanced for speaker's age, gender, and recording period, according to 32 categories (2 genders, 4 age ranges and 4 recording periods). Corpora were selected at French National Institute of Audiovisual (INA) to obtain at least 30 speakers per category (a total of 960 speakers; only 874 have be found yet). For each speaker, speech excerpts were extracted from audiovisual documents using an automatic pipeline consisting of speech detection, background music and overlapped speech removal and speaker diarization, used to present clean speaker segments to human annotators identifying target speakers. This pipeline proved highly effective, cutting down manual processing by a factor of ten. Evaluation of the quality of the automatic processing and of the final output is provided. It shows the automatic processing compare to up-to-date process, and that the output provides high quality speech for most of the selected excerpts. This method shows promise for creating large corpora of known target speakers.
* Keywords:, semi-automatic processing, corpus creation, diarization, speaker identification, gender-balanced, age-balanced, speaker corpus, diachrony
Unsupervised Multiple Domain Translation through Controlled Disentanglement in Variational Autoencoder
Jan 18, 2024



Unsupervised Multiple Domain Translation is the task of transforming data from one domain to other domains without having paired data to train the systems. Typically, methods based on Generative Adversarial Networks (GANs) are used to address this task. However, our proposal exclusively relies on a modified version of a Variational Autoencoder. This modification consists of the use of two latent variables disentangled in a controlled way by design. One of this latent variables is imposed to depend exclusively on the domain, while the other one must depend on the rest of the variability factors of the data. Additionally, the conditions imposed over the domain latent variable allow for better control and understanding of the latent space. We empirically demonstrate that our approach works on different vision datasets improving the performance of other well known methods. Finally, we prove that, indeed, one of the latent variables stores all the information related to the domain and the other one hardly contains any domain information.
An Explainable Proxy Model for Multiabel Audio Segmentation
Jan 17, 2024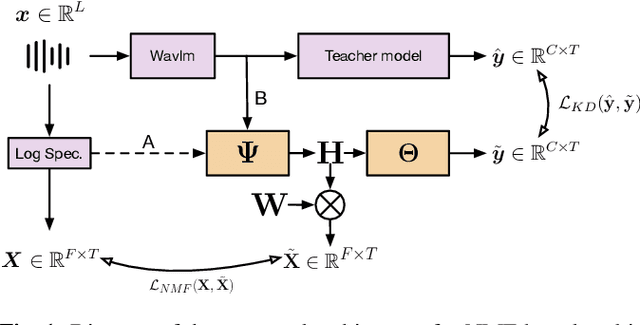
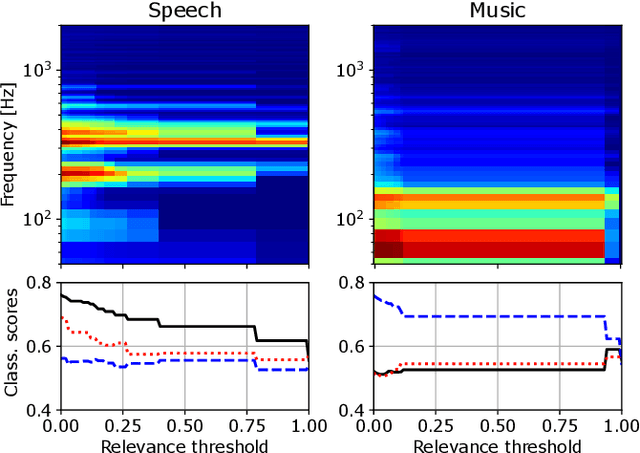
Audio signal segmentation is a key task for automatic audio indexing. It consists of detecting the boundaries of class-homogeneous segments in the signal. In many applications, explainable AI is a vital process for transparency of decision-making with machine learning. In this paper, we propose an explainable multilabel segmentation model that solves speech activity (SAD), music (MD), noise (ND), and overlapped speech detection (OSD) simultaneously. This proxy uses the non-negative matrix factorization (NMF) to map the embedding used for the segmentation to the frequency domain. Experiments conducted on two datasets show similar performances as the pre-trained black box model while showing strong explainability features. Specifically, the frequency bins used for the decision can be easily identified at both the segment level (local explanations) and global level (class prototypes).
Acoustic and linguistic representations for speech continuous emotion recognition in call center conversations
Oct 06, 2023The goal of our research is to automatically retrieve the satisfaction and the frustration in real-life call-center conversations. This study focuses an industrial application in which the customer satisfaction is continuously tracked down to improve customer services. To compensate the lack of large annotated emotional databases, we explore the use of pre-trained speech representations as a form of transfer learning towards AlloSat corpus. Moreover, several studies have pointed out that emotion can be detected not only in speech but also in facial trait, in biological response or in textual information. In the context of telephone conversations, we can break down the audio information into acoustic and linguistic by using the speech signal and its transcription. Our experiments confirms the large gain in performance obtained with the use of pre-trained features. Surprisingly, we found that the linguistic content is clearly the major contributor for the prediction of satisfaction and best generalizes to unseen data. Our experiments conclude to the definitive advantage of using CamemBERT representations, however the benefit of the fusion of acoustic and linguistic modalities is not as obvious. With models learnt on individual annotations, we found that fusion approaches are more robust to the subjectivity of the annotation task. This study also tackles the problem of performances variability and intends to estimate this variability from different views: weights initialization, confidence intervals and annotation subjectivity. A deep analysis on the linguistic content investigates interpretable factors able to explain the high contribution of the linguistic modality for this task.
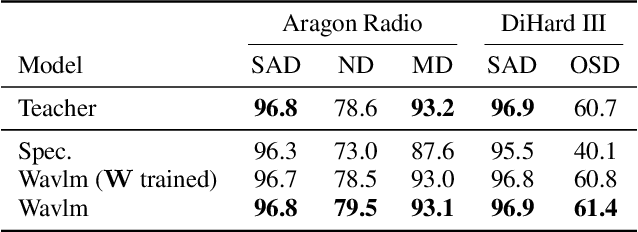
Joint speech and overlap detection: a benchmark over multiple audio setup and speech domains
Jul 24, 2023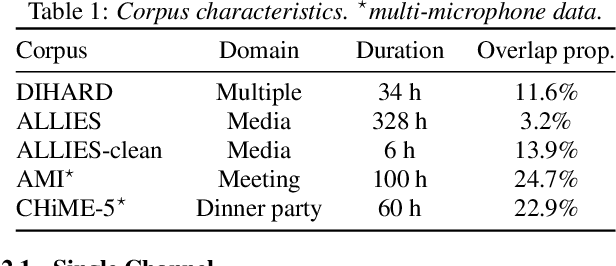
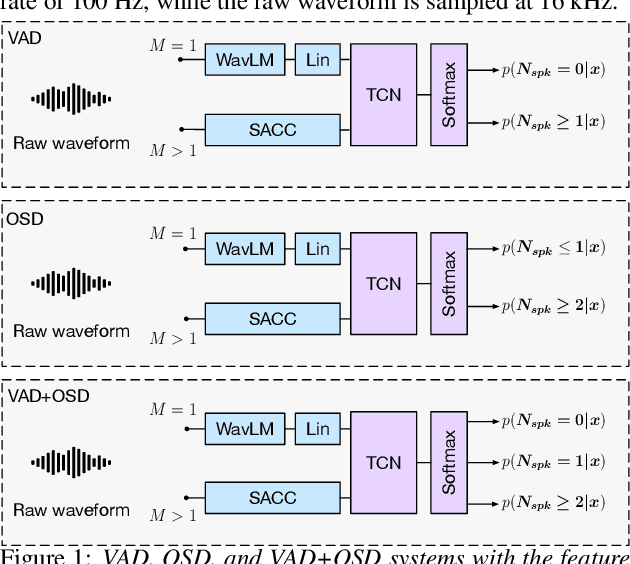

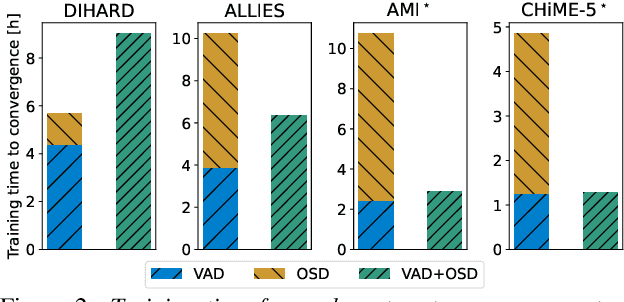
Voice activity and overlapped speech detection (respectively VAD and OSD) are key pre-processing tasks for speaker diarization. The final segmentation performance highly relies on the robustness of these sub-tasks. Recent studies have shown VAD and OSD can be trained jointly using a multi-class classification model. However, these works are often restricted to a specific speech domain, lacking information about the generalization capacities of the systems. This paper proposes a complete and new benchmark of different VAD and OSD models, on multiple audio setups (single/multi-channel) and speech domains (e.g. media, meeting...). Our 2/3-class systems, which combine a Temporal Convolutional Network with speech representations adapted to the setup, outperform state-of-the-art results. We show that the joint training of these two tasks offers similar performances in terms of F1-score to two dedicated VAD and OSD systems while reducing the training cost. This unique architecture can also be used for single and multichannel speech processing.
Evaluation of Speaker Anonymization on Emotional Speech
Apr 15, 2023Speech data carries a range of personal information, such as the speaker's identity and emotional state. These attributes can be used for malicious purposes. With the development of virtual assistants, a new generation of privacy threats has emerged. Current studies have addressed the topic of preserving speech privacy. One of them, the VoicePrivacy initiative aims to promote the development of privacy preservation tools for speech technology. The task selected for the VoicePrivacy 2020 Challenge (VPC) is about speaker anonymization. The goal is to hide the source speaker's identity while preserving the linguistic information. The baseline of the VPC makes use of a voice conversion. This paper studies the impact of the speaker anonymization baseline system of the VPC on emotional information present in speech utterances. Evaluation is performed following the VPC rules regarding the attackers' knowledge about the anonymization system. Our results show that the VPC baseline system does not suppress speakers' emotions against informed attackers. When comparing anonymized speech to original speech, the emotion recognition performance is degraded by 15\% relative to IEMOCAP data, similar to the degradation observed for automatic speech recognition used to evaluate the preservation of the linguistic information.