 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredefined Prototypes for Intra-Class Separation and Disentanglement
Paper and Code
Jun 23, 2024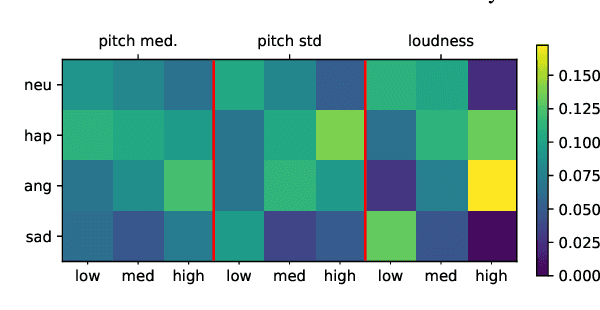
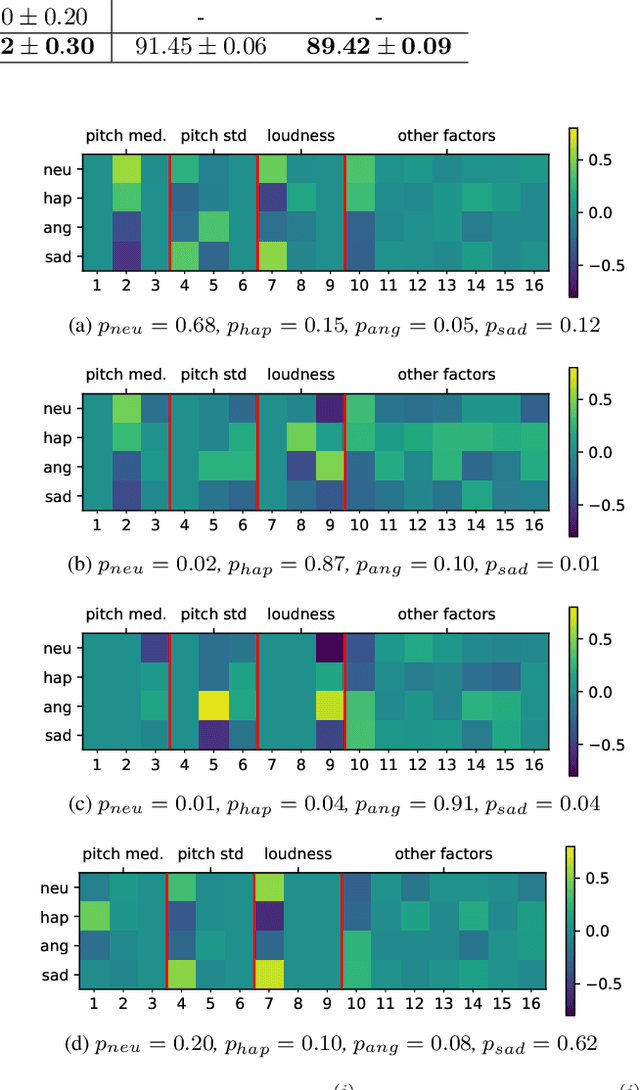
Prototypical Learning is based on the idea that there is a point (which we call prototype) around which the embeddings of a class are clustered. It has shown promising results in scenarios with little labeled data or to design explainable models. Typically, prototypes are either defined as the average of the embeddings of a class or are designed to be trainable. In this work, we propose to predefine prototypes following human-specified criteria, which simplify the training pipeline and brings different advantages. Specifically, in this work we explore two of these advantages: increasing the inter-class separability of embeddings and disentangling embeddings with respect to different variance factors, which can translate into the possibility of having explainable predictions. Finally, we propose different experiments that help to understand our proposal and demonstrate empirically the mentioned advantages.