 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentation Unlearning: Forgetting through Information Compression
Jan 29, 2026Machine unlearning seeks to remove the influence of specific training data from a model, a need driven by privacy regulations and robustness concerns. Existing approaches typically modify model parameters, but such updates can be unstable, computationally costly, and limited by local approximations. We introduce Representation Unlearning, a framework that performs unlearning directly in the model's representation space. Instead of modifying model parameters, we learn a transformation over representations that imposes an information bottleneck: maximizing mutual information with retained data while suppressing information about data to be forgotten. We derive variational surrogates that make this objective tractable and show how they can be instantiated in two practical regimes: when both retain and forget data are available, and in a zero-shot setting where only forget data can be accessed. Experiments across several benchmarks demonstrate that Representation Unlearning achieves more reliable forgetting, better utility retention, and greater computational efficiency than parameter-centric baselines.
Bridging Functional and Representational Similarity via Usable Information
Jan 29, 2026We present a unified framework for quantifying the similarity between representations through the lens of \textit{usable information}, offering a rigorous theoretical and empirical synthesis across three key dimensions. First, addressing functional similarity, we establish a formal link between stitching performance and conditional mutual information. We further reveal that stitching is inherently asymmetric, demonstrating that robust functional comparison necessitates a bidirectional analysis rather than a unidirectional mapping. Second, concerning representational similarity, we prove that reconstruction-based metrics and standard tools (e.g., CKA, RSA) act as estimators of usable information under specific constraints. Crucially, we show that similarity is relative to the capacity of the predictive family: representations that appear distinct to a rigid observer may be identical to a more expressive one. Third, we demonstrate that representational similarity is sufficient but not necessary for functional similarity. We unify these concepts through a task-granularity hierarchy: similarity on a complex task guarantees similarity on any coarser derivative, establishing representational similarity as the limit of maximum granularity: input reconstruction.
There Was Never a Bottleneck in Concept Bottleneck Models
Jun 05, 2025



Deep learning representations are often difficult to interpret, which can hinder their deployment in sensitive applications. Concept Bottleneck Models (CBMs) have emerged as a promising approach to mitigate this issue by learning representations that support target task performance while ensuring that each component predicts a concrete concept from a predefined set. In this work, we argue that CBMs do not impose a true bottleneck: the fact that a component can predict a concept does not guarantee that it encodes only information about that concept. This shortcoming raises concerns regarding interpretability and the validity of intervention procedures. To overcome this limitation, we propose Minimal Concept Bottleneck Models (MCBMs), which incorporate an Information Bottleneck (IB) objective to constrain each representation component to retain only the information relevant to its corresponding concept. This IB is implemented via a variational regularization term added to the training loss. As a result, MCBMs support concept-level interventions with theoretical guarantees, remain consistent with Bayesian principles, and offer greater flexibility in key design choices.
Aligning Multimodal Representations through an Information Bottleneck
Jun 05, 2025Contrastive losses have been extensively used as a tool for multimodal representation learning. However, it has been empirically observed that their use is not effective to learn an aligned representation space. In this paper, we argue that this phenomenon is caused by the presence of modality-specific information in the representation space. Although some of the most widely used contrastive losses maximize the mutual information between representations of both modalities, they are not designed to remove the modality-specific information. We give a theoretical description of this problem through the lens of the Information Bottleneck Principle. We also empirically analyze how different hyperparameters affect the emergence of this phenomenon in a controlled experimental setup. Finally, we propose a regularization term in the loss function that is derived by means of a variational approximation and aims to increase the representational alignment. We analyze in a set of controlled experiments and real-world applications the advantages of including this regularization term.
Beyond Global Metrics: A Fairness Analysis for Interpretable Voice Disorder Detection Systems
Apr 11, 2025

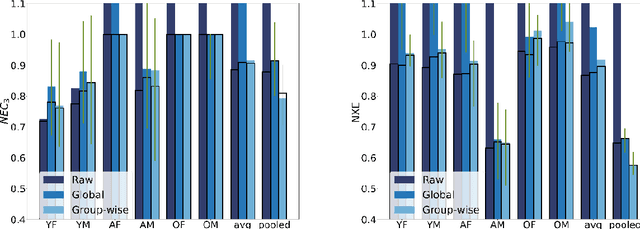

We conducted a comprehensive analysis of an Automatic Voice Disorders Detection (AVDD) system using existing voice disorder datasets with available demographic metadata. The study involved analysing system performance across various demographic groups, particularly focusing on gender and age-based cohorts. Performance evaluation was based on multiple metrics, including normalised costs and cross-entropy. We employed calibration techniques trained separately on predefined demographic groups to address group-dependent miscalibration. Analysis revealed significant performance disparities across groups despite strong global metrics. The system showed systematic biases, misclassifying healthy speakers over 55 as having a voice disorder and speakers with disorders aged 14-30 as healthy. Group-specific calibration improved posterior probability quality, reducing overconfidence. For young disordered speakers, low severity scores were identified as contributing to poor system performance. For older speakers, age-related voice characteristics and potential limitations in the pretrained Hubert model used as feature extractor likely affected results. The study demonstrates that global performance metrics are insufficient for evaluating AVDD system performance. Group-specific analysis may unmask problems in system performance which are hidden within global metrics. Further, group-dependent calibration strategies help mitigate biases, resulting in a more reliable indication of system confidence. These findings emphasize the need for demographic-specific evaluation and calibration in voice disorder detection systems, while providing a methodological framework applicable to broader biomedical classification tasks where demographic metadata is available.
Angular Distance Distribution Loss for Audio Classification
Oct 31, 2024Classification is a pivotal task in deep learning not only because of its intrinsic importance, but also for providing embeddings with desirable properties in other tasks. To optimize these properties, a wide variety of loss functions have been proposed that attempt to minimize the intra-class distance and maximize the inter-class distance in the embeddings space. In this paper we argue that, in addition to these two, eliminating hierarchies within and among classes are two other desirable properties for classification embeddings. Furthermore, we propose the Angular Distance Distribution (ADD) Loss, which aims to enhance the four previous properties jointly. For this purpose, it imposes conditions on the first and second order statistical moments of the angular distance between embeddings. Finally, we perform experiments showing that our loss function improves all four properties and, consequently, performs better than other loss functions in audio classification tasks.
Audio-Visual Speaker Diarization: Current Databases, Approaches and Challenges
Sep 09, 2024Nowadays, the large amount of audio-visual content available has fostered the need to develop new robust automatic speaker diarization systems to analyse and characterise it. This kind of system helps to reduce the cost of doing this process manually and allows the use of the speaker information for different applications, as a huge quantity of information is present, for example, images of faces, or audio recordings. Therefore, this paper aims to address a critical area in the field of speaker diarization systems, the integration of audio-visual content of different domains. This paper seeks to push beyond current state-of-the-art practices by developing a robust audio-visual speaker diarization framework adaptable to various data domains, including TV scenarios, meetings, and daily activities. Unlike most of the existing audio-visual speaker diarization systems, this framework will also include the proposal of an approach to lead the precise assignment of specific identities in TV scenarios where celebrities appear. In addition, in this work, we have conducted an extensive compilation of the current state-of-the-art approaches and the existing databases for developing audio-visual speaker diarization.
Defining and Measuring Disentanglement for non-Independent Factors of Variation
Aug 13, 2024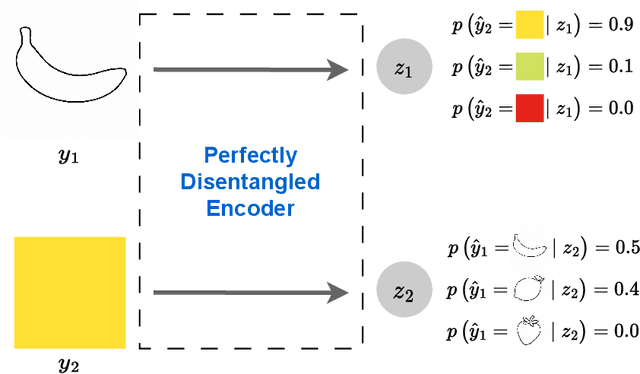
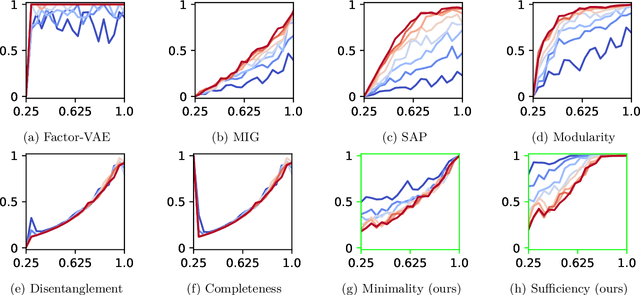

Representation learning is an approach that allows to discover and extract the factors of variation from the data. Intuitively, a representation is said to be disentangled if it separates the different factors of variation in a way that is understandable to humans. Definitions of disentanglement and metrics to measure it usually assume that the factors of variation are independent of each other. However, this is generally false in the real world, which limits the use of these definitions and metrics to very specific and unrealistic scenarios. In this paper we give a definition of disentanglement based on information theory that is also valid when the factors of variation are not independent. Furthermore, we relate this definition to the Information Bottleneck Method. Finally, we propose a method to measure the degree of disentanglement from the given definition that works when the factors of variation are not independent. We show through different experiments that the method proposed in this paper correctly measures disentanglement with non-independent factors of variation, while other methods fail in this scenario.
Predefined Prototypes for Intra-Class Separation and Disentanglement
Jun 23, 2024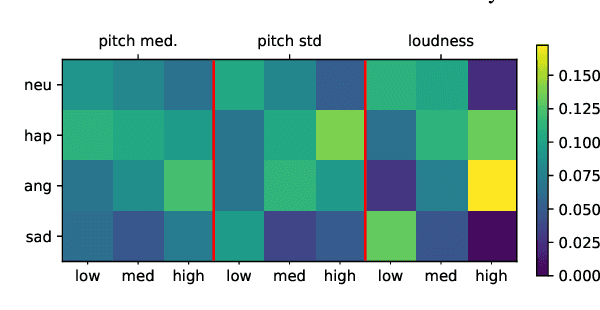
Prototypical Learning is based on the idea that there is a point (which we call prototype) around which the embeddings of a class are clustered. It has shown promising results in scenarios with little labeled data or to design explainable models. Typically, prototypes are either defined as the average of the embeddings of a class or are designed to be trainable. In this work, we propose to predefine prototypes following human-specified criteria, which simplify the training pipeline and brings different advantages. Specifically, in this work we explore two of these advantages: increasing the inter-class separability of embeddings and disentangling embeddings with respect to different variance factors, which can translate into the possibility of having explainable predictions. Finally, we propose different experiments that help to understand our proposal and demonstrate empirically the mentioned advantages.
Explainable by-design Audio Segmentation through Non-Negative Matrix Factorization and Probing
Jun 19, 2024
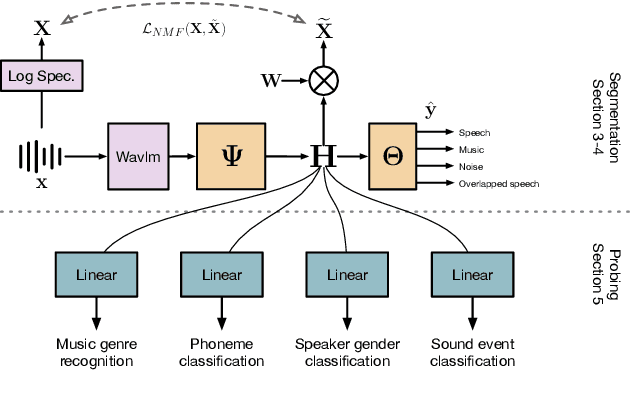
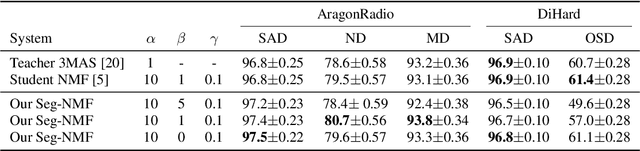
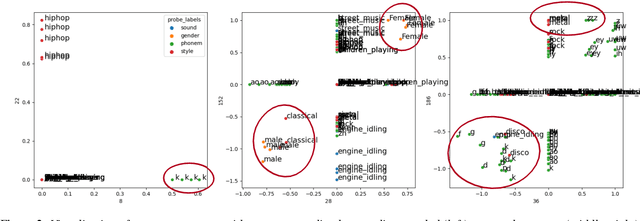
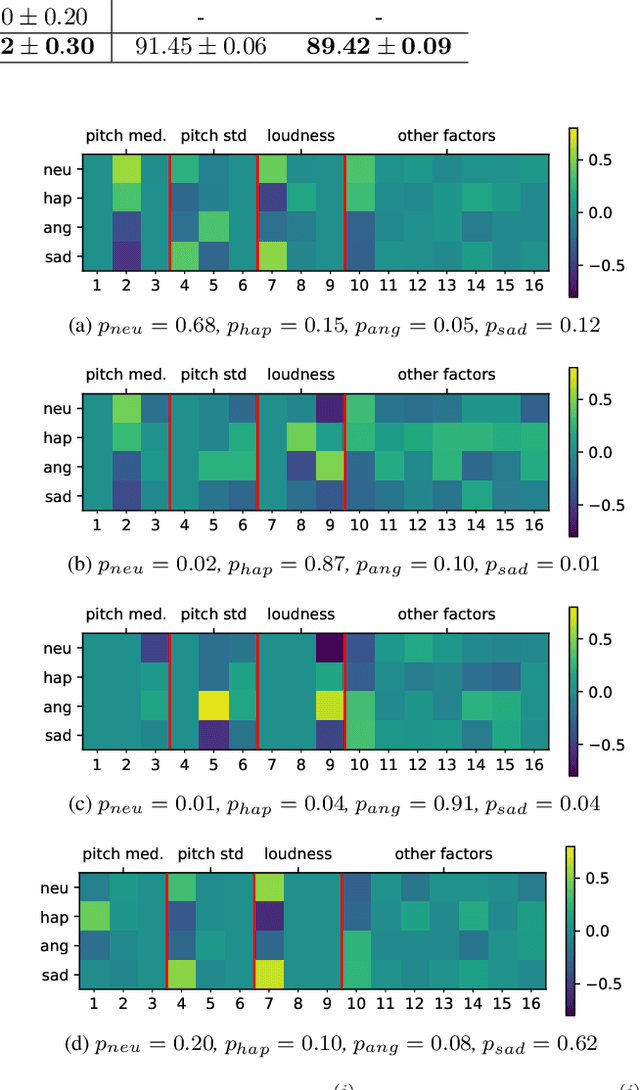
Audio segmentation is a key task for many speech technologies, most of which are based on neural networks, usually considered as black boxes, with high-level performances. However, in many domains, among which health or forensics, there is not only a need for good performance but also for explanations about the output decision. Explanations derived directly from latent representations need to satisfy "good" properties, such as informativeness, compactness, or modularity, to be interpretable. In this article, we propose an explainable-by-design audio segmentation model based on non-negative matrix factorization (NMF) which is a good candidate for the design of interpretable representations. This paper shows that our model reaches good segmentation performances, and presents deep analyses of the latent representation extracted from the non-negative matrix. The proposed approach opens new perspectives toward the evaluation of interpretable representations according to "good" properties.