 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Global Metrics: A Fairness Analysis for Interpretable Voice Disorder Detection Systems
Paper and Code
Apr 11, 2025

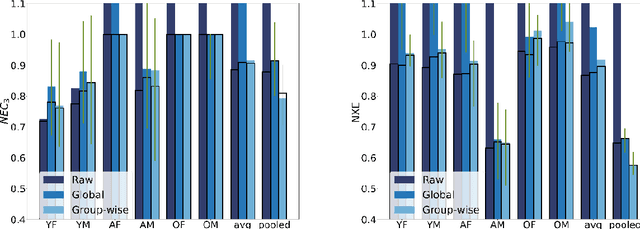

We conducted a comprehensive analysis of an Automatic Voice Disorders Detection (AVDD) system using existing voice disorder datasets with available demographic metadata. The study involved analysing system performance across various demographic groups, particularly focusing on gender and age-based cohorts. Performance evaluation was based on multiple metrics, including normalised costs and cross-entropy. We employed calibration techniques trained separately on predefined demographic groups to address group-dependent miscalibration. Analysis revealed significant performance disparities across groups despite strong global metrics. The system showed systematic biases, misclassifying healthy speakers over 55 as having a voice disorder and speakers with disorders aged 14-30 as healthy. Group-specific calibration improved posterior probability quality, reducing overconfidence. For young disordered speakers, low severity scores were identified as contributing to poor system performance. For older speakers, age-related voice characteristics and potential limitations in the pretrained Hubert model used as feature extractor likely affected results. The study demonstrates that global performance metrics are insufficient for evaluating AVDD system performance. Group-specific analysis may unmask problems in system performance which are hidden within global metrics. Further, group-dependent calibration strategies help mitigate biases, resulting in a more reliable indication of system confidence. These findings emphasize the need for demographic-specific evaluation and calibration in voice disorder detection systems, while providing a methodological framework applicable to broader biomedical classification tasks where demographic metadata is available.