 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Global Metrics: A Fairness Analysis for Interpretable Voice Disorder Detection Systems
Apr 11, 2025

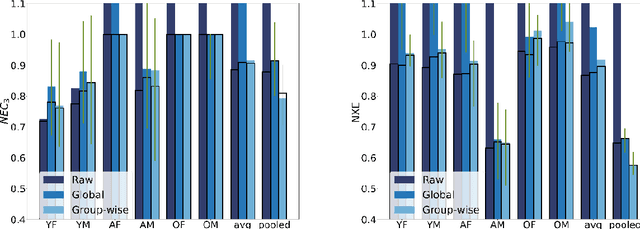

We conducted a comprehensive analysis of an Automatic Voice Disorders Detection (AVDD) system using existing voice disorder datasets with available demographic metadata. The study involved analysing system performance across various demographic groups, particularly focusing on gender and age-based cohorts. Performance evaluation was based on multiple metrics, including normalised costs and cross-entropy. We employed calibration techniques trained separately on predefined demographic groups to address group-dependent miscalibration. Analysis revealed significant performance disparities across groups despite strong global metrics. The system showed systematic biases, misclassifying healthy speakers over 55 as having a voice disorder and speakers with disorders aged 14-30 as healthy. Group-specific calibration improved posterior probability quality, reducing overconfidence. For young disordered speakers, low severity scores were identified as contributing to poor system performance. For older speakers, age-related voice characteristics and potential limitations in the pretrained Hubert model used as feature extractor likely affected results. The study demonstrates that global performance metrics are insufficient for evaluating AVDD system performance. Group-specific analysis may unmask problems in system performance which are hidden within global metrics. Further, group-dependent calibration strategies help mitigate biases, resulting in a more reliable indication of system confidence. These findings emphasize the need for demographic-specific evaluation and calibration in voice disorder detection systems, while providing a methodological framework applicable to broader biomedical classification tasks where demographic metadata is available.
An improved uncertainty propagation method for robust i-vector based speaker recognition
Feb 19, 2019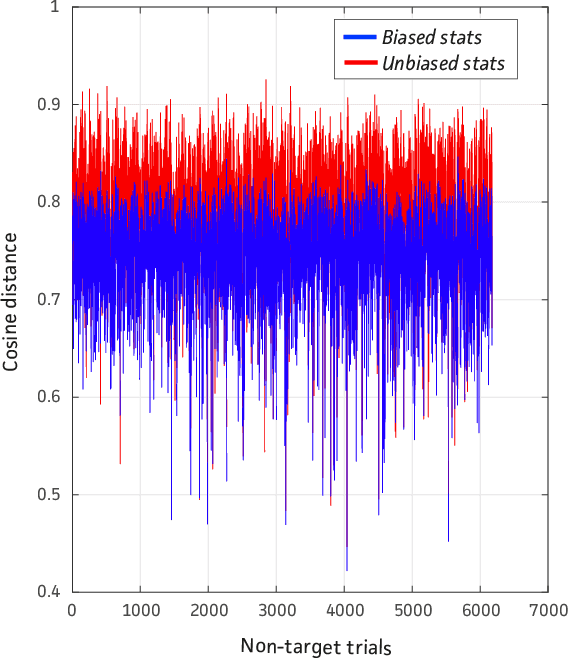
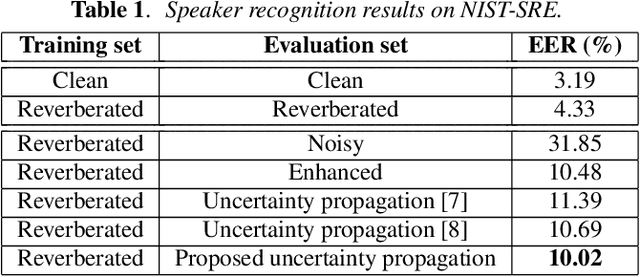
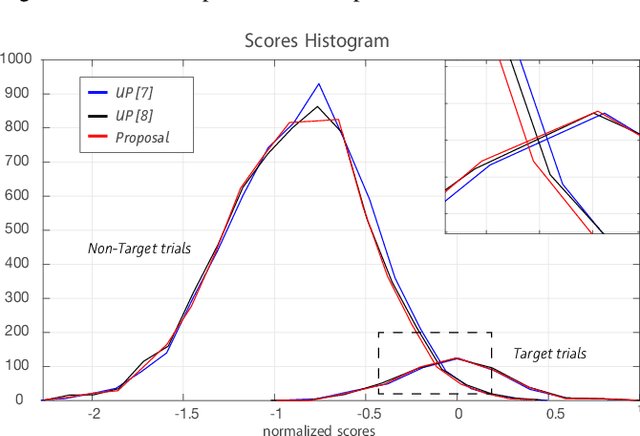
The performance of automatic speaker recognition systems degrades when facing distorted speech data containing additive noise and/or reverberation. Statistical uncertainty propagation has been introduced as a promising paradigm to address this challenge. So far, different uncertainty propagation methods have been proposed to compensate noise and reverberation in i-vectors in the context of speaker recognition. They have achieved promising results on small datasets such as YOHO and Wall Street Journal, but little or no improvement on the larger, highly variable NIST Speaker Recognition Evaluation (SRE) corpus. In this paper, we propose a complete uncertainty propagation method, whereby we model the effect of uncertainty both in the computation of unbiased Baum-Welch statistics and in the derivation of the posterior expectation of the i-vector. We conduct experiments on the NIST-SRE corpus mixed with real domestic noise and reverberation from the CHiME-2 corpus and preprocessed by multichannel speech enhancement. The proposed method improves the equal error rate (EER) by 4% relative compared to a conventional i-vector based speaker verification baseline. This is to be compared with previous methods which degrade performance.
Deep Speech Enhancement for Reverberated and Noisy Signals using Wide Residual Networks
Jan 03, 2019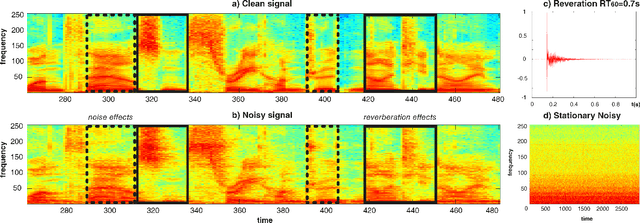
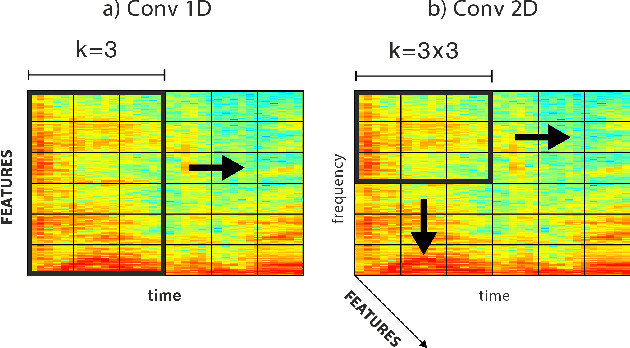
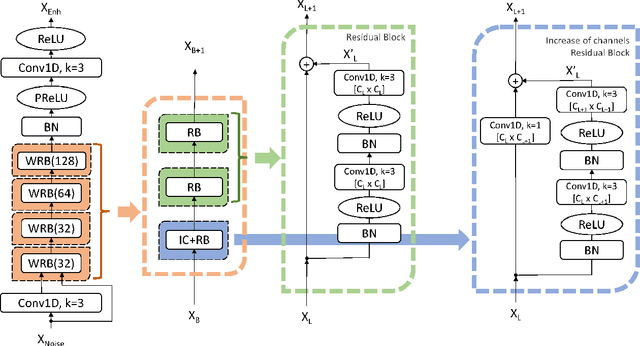
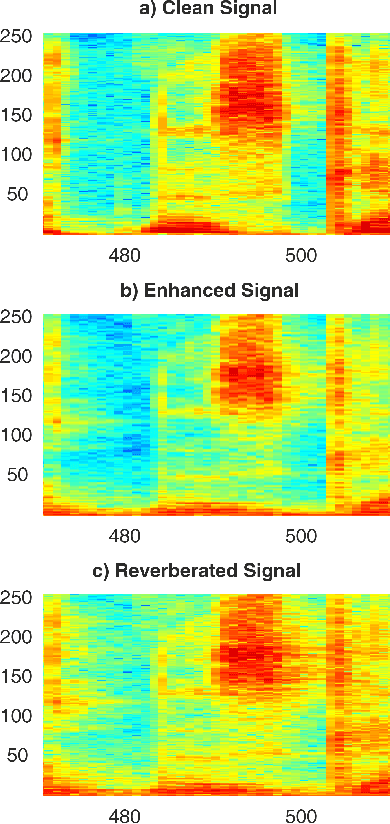
This paper proposes a deep speech enhancement method which exploits the high potential of residual connections in a wide neural network architecture, a topology known as Wide Residual Network. This is supported on single dimensional convolutions computed alongside the time domain, which is a powerful approach to process contextually correlated representations through the temporal domain, such as speech feature sequences. We find the residual mechanism extremely useful for the enhancement task since the signal always has a linear shortcut and the non-linear path enhances it in several steps by adding or subtracting corrections. The enhancement capacity of the proposal is assessed by objective quality metrics and the performance of a speech recognition system. This was evaluated in the framework of the REVERB Challenge dataset, including simulated and real samples of reverberated and noisy speech signals. Results showed that enhanced speech from the proposed method succeeded for both, the enhancement task with intelligibility purposes and the speech recognition system. The DNN model, trained with artificial synthesized reverberation data, was able to deal with far-field reverberated speech from real scenarios. Furthermore, the method was able to take advantage of the residual connection achieving to enhance signals with low noise level, which is usually a strong handicap of traditional enhancement methods.