 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Time-localized Explanations for Audio Classification Models
Jun 04, 2025
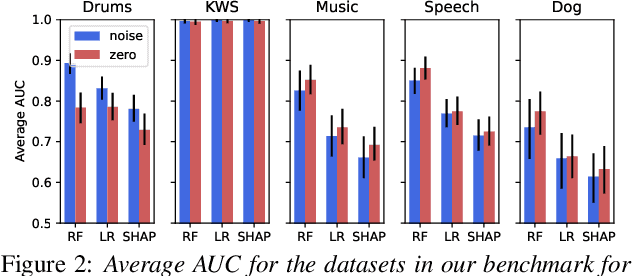
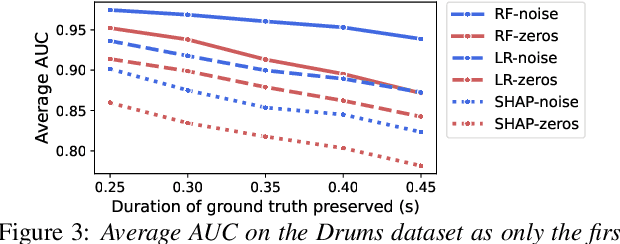
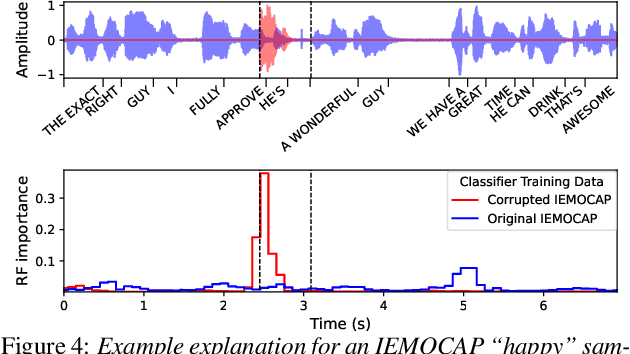
Most modern approaches for audio processing are opaque, in the sense that they do not provide an explanation for their decisions. For this reason, various methods have been proposed to explain the outputs generated by these models. Good explanations can result in interesting insights about the data or the model, as well as increase trust in the system. Unfortunately, evaluating the quality of explanations is far from trivial since, for most tasks, there is no clear ground truth explanation to use as reference. In this work, we propose a benchmark for time-localized explanations for audio classification models that uses time annotations of target events as a proxy for ground truth explanations. We use this benchmark to systematically optimize and compare various approaches for model-agnostic post-hoc explanation, obtaining, in some cases, close to perfect explanations. Finally, we illustrate the utility of the explanations for uncovering spurious correlations.
Beyond Global Metrics: A Fairness Analysis for Interpretable Voice Disorder Detection Systems
Apr 11, 2025

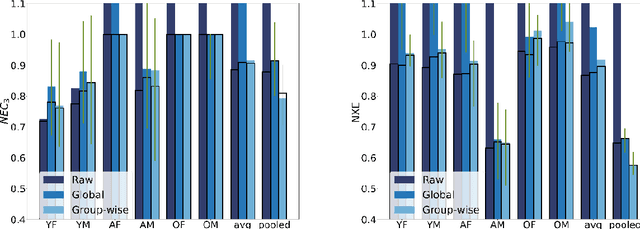

We conducted a comprehensive analysis of an Automatic Voice Disorders Detection (AVDD) system using existing voice disorder datasets with available demographic metadata. The study involved analysing system performance across various demographic groups, particularly focusing on gender and age-based cohorts. Performance evaluation was based on multiple metrics, including normalised costs and cross-entropy. We employed calibration techniques trained separately on predefined demographic groups to address group-dependent miscalibration. Analysis revealed significant performance disparities across groups despite strong global metrics. The system showed systematic biases, misclassifying healthy speakers over 55 as having a voice disorder and speakers with disorders aged 14-30 as healthy. Group-specific calibration improved posterior probability quality, reducing overconfidence. For young disordered speakers, low severity scores were identified as contributing to poor system performance. For older speakers, age-related voice characteristics and potential limitations in the pretrained Hubert model used as feature extractor likely affected results. The study demonstrates that global performance metrics are insufficient for evaluating AVDD system performance. Group-specific analysis may unmask problems in system performance which are hidden within global metrics. Further, group-dependent calibration strategies help mitigate biases, resulting in a more reliable indication of system confidence. These findings emphasize the need for demographic-specific evaluation and calibration in voice disorder detection systems, while providing a methodological framework applicable to broader biomedical classification tasks where demographic metadata is available.
Good practices for evaluation of machine learning systems
Dec 04, 2024



Many development decisions affect the results obtained from ML experiments: training data, features, model architecture, hyperparameters, test data, etc. Among these aspects, arguably the most important design decisions are those that involve the evaluation procedure. This procedure is what determines whether the conclusions drawn from the experiments will or will not generalize to unseen data and whether they will be relevant to the application of interest. If the data is incorrectly selected, the wrong metric is chosen for evaluation or the significance of the comparisons between models is overestimated, conclusions may be misleading or result in suboptimal development decisions. To avoid such problems, the evaluation protocol should be very carefully designed before experimentation starts. In this work we discuss the main aspects involved in the design of the evaluation protocol: data selection, metric selection, and statistical significance. This document is not meant to be an exhaustive tutorial on each of these aspects. Instead, the goal is to explain the main guidelines that should be followed in each case. We include examples taken from the speech processing field, and provide a list of common mistakes related to each aspect.
Evaluating Posterior Probabilities: Decision Theory, Proper Scoring Rules, and Calibration
Aug 05, 2024



Most machine learning classifiers are designed to output posterior probabilities for the classes given the input sample. These probabilities may be used to make the categorical decision on the class of the sample; provided as input to a downstream system; or provided to a human for interpretation. Evaluating the quality of the posteriors generated by these system is an essential problem which was addressed decades ago with the invention of proper scoring rules (PSRs). Unfortunately, much of the recent machine learning literature uses calibration metrics -- most commonly, the expected calibration error (ECE) -- as a proxy to assess posterior performance. The problem with this approach is that calibration metrics reflect only one aspect of the quality of the posteriors, ignoring the discrimination performance. For this reason, we argue that calibration metrics should play no role in the assessment of posterior quality. Expected PSRs should instead be used for this job, preferably normalized for ease of interpretation. In this work, we first give a brief review of PSRs from a practical perspective, motivating their definition using Bayes decision theory. We discuss why expected PSRs provide a principled measure of the quality of a system's posteriors and why calibration metrics are not the right tool for this job. We argue that calibration metrics, while not useful for performance assessment, may be used as diagnostic tools during system development. With this purpose in mind, we discuss a simple and practical calibration metric, called calibration loss, derived from a decomposition of expected PSRs. We compare this metric with the ECE and with the expected score divergence calibration metric from the PSR literature and argue, using theoretical and empirical evidence, that calibration loss is superior to these two metrics.
Fusion approaches for emotion recognition from speech using acoustic and text-based features
Mar 27, 2024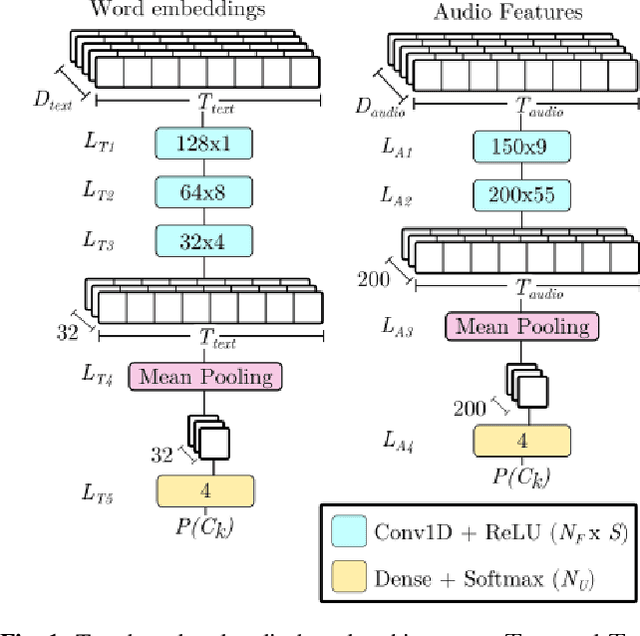
In this paper, we study different approaches for classifying emotions from speech using acoustic and text-based features. We propose to obtain contextualized word embeddings with BERT to represent the information contained in speech transcriptions and show that this results in better performance than using Glove embeddings. We also propose and compare different strategies to combine the audio and text modalities, evaluating them on IEMOCAP and MSP-PODCAST datasets. We find that fusing acoustic and text-based systems is beneficial on both datasets, though only subtle differences are observed across the evaluated fusion approaches. Finally, for IEMOCAP, we show the large effect that the criteria used to define the cross-validation folds have on results. In particular, the standard way of creating folds for this dataset results in a highly optimistic estimation of performance for the text-based system, suggesting that some previous works may overestimate the advantage of incorporating transcriptions.
On the Convergence of Semi Unsupervised Calibration through Prior Adaptation Algorithm
Jan 05, 2024



Calibration is an essential key in machine leaning. Semi Unsupervised Calibration through Prior Adaptation (SUCPA) is a calibration algorithm used in (but not limited to) large-scale language models defined by a {system of first-order difference equation. The map derived by this system} has the peculiarity of being non-hyperbolic {with a non-bounded set of non-isolated fixed points}. In this work, we prove several convergence properties of this algorithm from the perspective of dynamical systems. For a binary classification problem, it can be shown that the algorithm always converges, {more precisely, the map is globally asymptotically stable, and the orbits converge} to a single line of fixed points. Finally, we perform numerical experiments on real-world application to support the presented results. Experiment codes are available online.
EnCodecMAE: Leveraging neural codecs for universal audio representation learning
Sep 14, 2023

The goal of universal audio representation learning is to obtain foundational models that can be used for a variety of downstream tasks involving speech, music or environmental sounds. To approach this problem, methods inspired by self-supervised models from NLP, like BERT, are often used and adapted to audio. These models rely on the discrete nature of text, hence adopting this type of approach for audio processing requires either a change in the learning objective or mapping the audio signal to a set of discrete classes. In this work, we explore the use of EnCodec, a neural audio codec, to generate discrete targets for learning an universal audio model based on a masked autoencoder (MAE). We evaluate this approach, which we call EncodecMAE, on a wide range of audio tasks spanning speech, music and environmental sounds, achieving performances comparable or better than leading audio representation models.
Mispronunciation detection using self-supervised speech representations
Jul 30, 2023In recent years, self-supervised learning (SSL) models have produced promising results in a variety of speech-processing tasks, especially in contexts of data scarcity. In this paper, we study the use of SSL models for the task of mispronunciation detection for second language learners. We compare two downstream approaches: 1) training the model for phone recognition (PR) using native English data, and 2) training a model directly for the target task using non-native English data. We compare the performance of these two approaches for various SSL representations as well as a representation extracted from a traditional DNN-based speech recognition model. We evaluate the models on L2Arctic and EpaDB, two datasets of non-native speech annotated with pronunciation labels at the phone level. Overall, we find that using a downstream model trained for the target task gives the best performance and that most upstream models perform similarly for the task.
Deployment of Image Analysis Algorithms under Prevalence Shifts
Mar 22, 2023



Domain gaps are among the most relevant roadblocks in the clinical translation of machine learning (ML)-based solutions for medical image analysis. While current research focuses on new training paradigms and network architectures, little attention is given to the specific effect of prevalence shifts on an algorithm deployed in practice. Such discrepancies between class frequencies in the data used for a method's development/validation and that in its deployment environment(s) are of great importance, for example in the context of artificial intelligence (AI) democratization, as disease prevalences may vary widely across time and location. Our contribution is twofold. First, we empirically demonstrate the potentially severe consequences of missing prevalence handling by analyzing (i) the extent of miscalibration, (ii) the deviation of the decision threshold from the optimum, and (iii) the ability of validation metrics to reflect neural network performance on the deployment population as a function of the discrepancy between development and deployment prevalence. Second, we propose a workflow for prevalence-aware image classification that uses estimated deployment prevalences to adjust a trained classifier to a new environment, without requiring additional annotated deployment data. Comprehensive experiments based on a diverse set of 30 medical classification tasks showcase the benefit of the proposed workflow in generating better classifier decisions and more reliable performance estimates compared to current practice.
Phone and speaker spatial organization in self-supervised speech representations
Feb 24, 2023
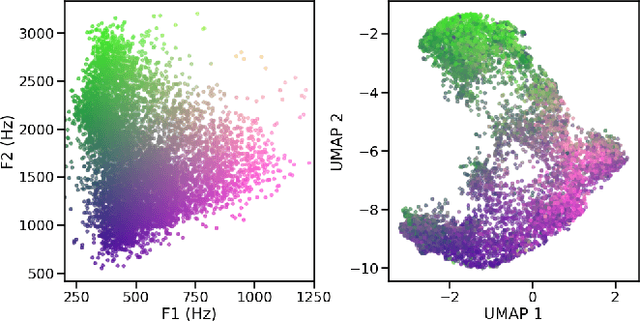
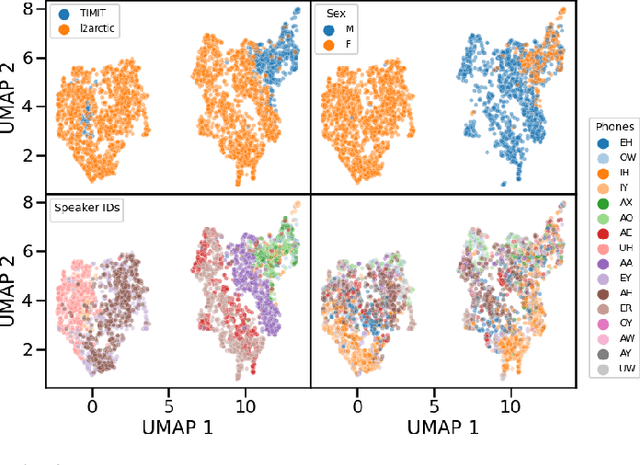
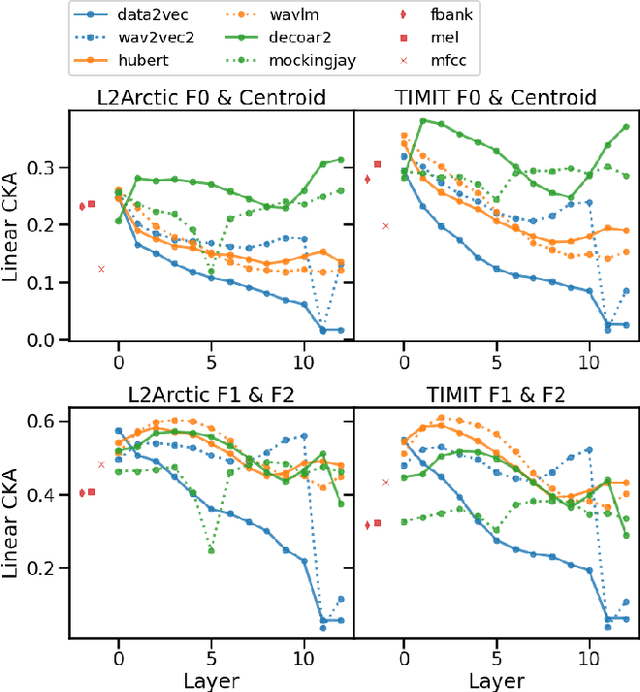
Self-supervised representations of speech are currently being widely used for a large number of applications. Recently, some efforts have been made in trying to analyze the type of information present in each of these representations. Most such work uses downstream models to test whether the representations can be successfully used for a specific task. The downstream models, though, typically perform nonlinear operations on the representation extracting information that may not have been readily available in the original representation. In this work, we analyze the spatial organization of phone and speaker information in several state-of-the-art speech representations using methods that do not require a downstream model. We measure how different layers encode basic acoustic parameters such as formants and pitch using representation similarity analysis. Further, we study the extent to which each representation clusters the speech samples by phone or speaker classes using non-parametric statistical testing. Our results indicate that models represent these speech attributes differently depending on the target task used during pretraining.