 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynchronization and Turn-Taking in Full-Duplex Speech Dialogue Models
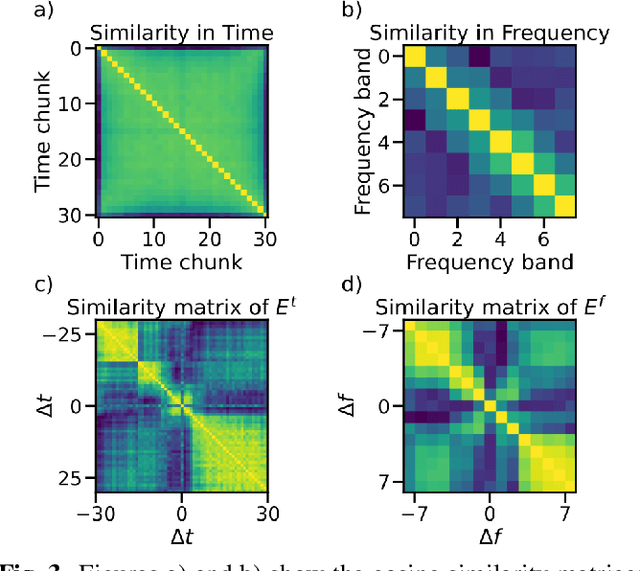
May 19, 2026Full-duplex spoken dialogue models (SDMs) can listen and speak simultaneously, enabling interaction dynamics closer to human conversation than turn-based systems. Inspired by neural coupling in human communication, we study how such models coordinate their internal representations during interaction. We simulate full-duplex dialogues between two instances of the pretrained \textit{Moshi} model under controlled conditions, manipulating channel noise and decoding bias. Synchronization is measured using Centered Kernel Alignment (CKA) across temporal lags, while anticipatory turn-taking cues are probed from delayed internal activations using causal LSTM models, from both speaker and listener perspectives. We find strong representational synchronization under no noise conditions, peaking near zero lag and degrading with noise, and we show that internal states encode anticipatory information that supports turn-taking prediction ahead of time.
Fusion approaches for emotion recognition from speech using acoustic and text-based features
Mar 27, 2024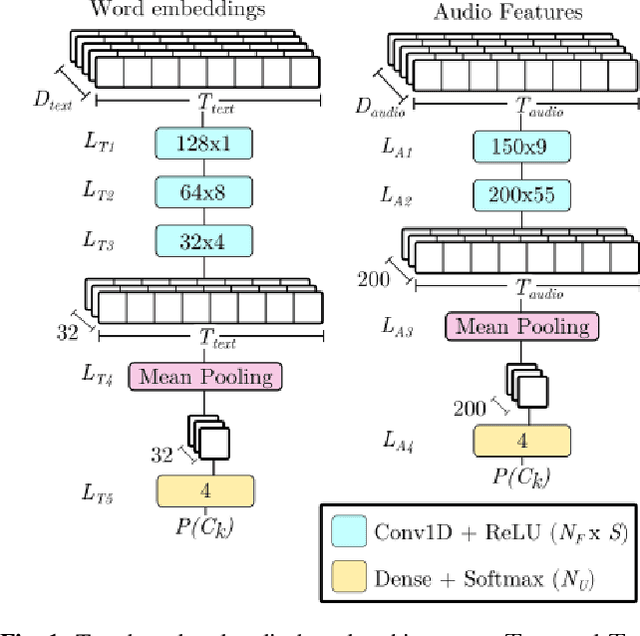
In this paper, we study different approaches for classifying emotions from speech using acoustic and text-based features. We propose to obtain contextualized word embeddings with BERT to represent the information contained in speech transcriptions and show that this results in better performance than using Glove embeddings. We also propose and compare different strategies to combine the audio and text modalities, evaluating them on IEMOCAP and MSP-PODCAST datasets. We find that fusing acoustic and text-based systems is beneficial on both datasets, though only subtle differences are observed across the evaluated fusion approaches. Finally, for IEMOCAP, we show the large effect that the criteria used to define the cross-validation folds have on results. In particular, the standard way of creating folds for this dataset results in a highly optimistic estimation of performance for the text-based system, suggesting that some previous works may overestimate the advantage of incorporating transcriptions.
EnCodecMAE: Leveraging neural codecs for universal audio representation learning
Sep 14, 2023

The goal of universal audio representation learning is to obtain foundational models that can be used for a variety of downstream tasks involving speech, music or environmental sounds. To approach this problem, methods inspired by self-supervised models from NLP, like BERT, are often used and adapted to audio. These models rely on the discrete nature of text, hence adopting this type of approach for audio processing requires either a change in the learning objective or mapping the audio signal to a set of discrete classes. In this work, we explore the use of EnCodec, a neural audio codec, to generate discrete targets for learning an universal audio model based on a masked autoencoder (MAE). We evaluate this approach, which we call EncodecMAE, on a wide range of audio tasks spanning speech, music and environmental sounds, achieving performances comparable or better than leading audio representation models.
Mispronunciation detection using self-supervised speech representations
Jul 30, 2023In recent years, self-supervised learning (SSL) models have produced promising results in a variety of speech-processing tasks, especially in contexts of data scarcity. In this paper, we study the use of SSL models for the task of mispronunciation detection for second language learners. We compare two downstream approaches: 1) training the model for phone recognition (PR) using native English data, and 2) training a model directly for the target task using non-native English data. We compare the performance of these two approaches for various SSL representations as well as a representation extracted from a traditional DNN-based speech recognition model. We evaluate the models on L2Arctic and EpaDB, two datasets of non-native speech annotated with pronunciation labels at the phone level. Overall, we find that using a downstream model trained for the target task gives the best performance and that most upstream models perform similarly for the task.
Phone and speaker spatial organization in self-supervised speech representations
Feb 24, 2023
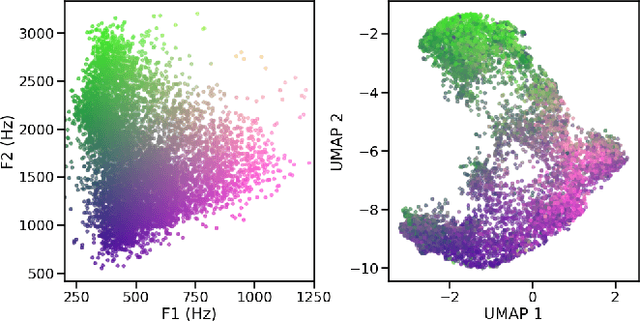
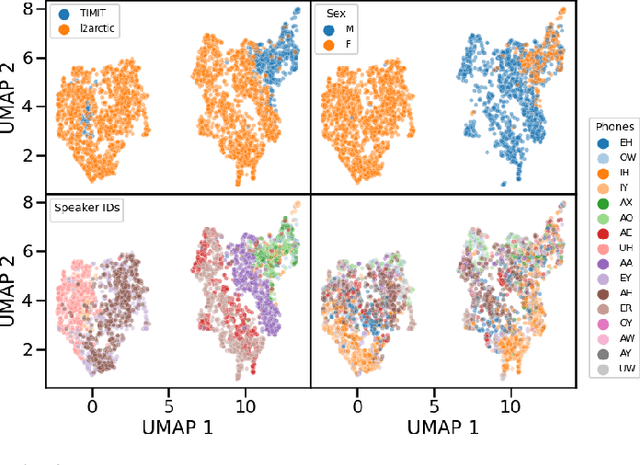
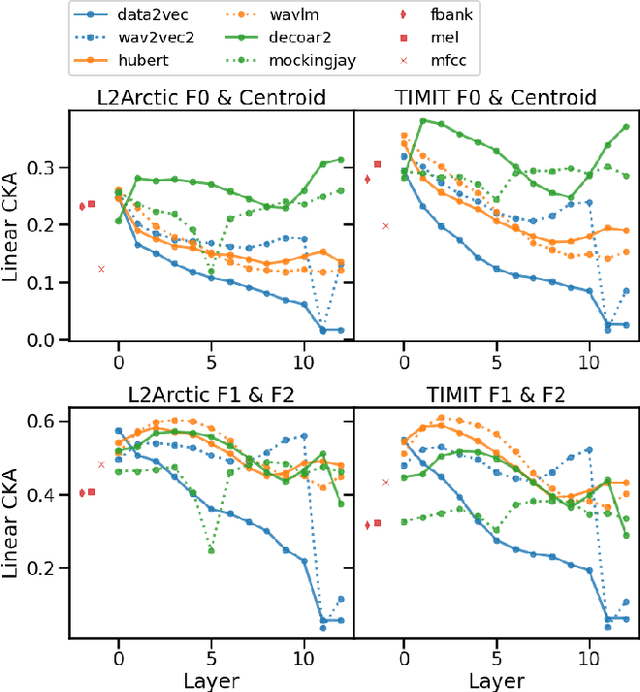
Self-supervised representations of speech are currently being widely used for a large number of applications. Recently, some efforts have been made in trying to analyze the type of information present in each of these representations. Most such work uses downstream models to test whether the representations can be successfully used for a specific task. The downstream models, though, typically perform nonlinear operations on the representation extracting information that may not have been readily available in the original representation. In this work, we analyze the spatial organization of phone and speaker information in several state-of-the-art speech representations using methods that do not require a downstream model. We measure how different layers encode basic acoustic parameters such as formants and pitch using representation similarity analysis. Further, we study the extent to which each representation clusters the speech samples by phone or speaker classes using non-parametric statistical testing. Our results indicate that models represent these speech attributes differently depending on the target task used during pretraining.
Study of positional encoding approaches for Audio Spectrogram Transformers
Oct 13, 2021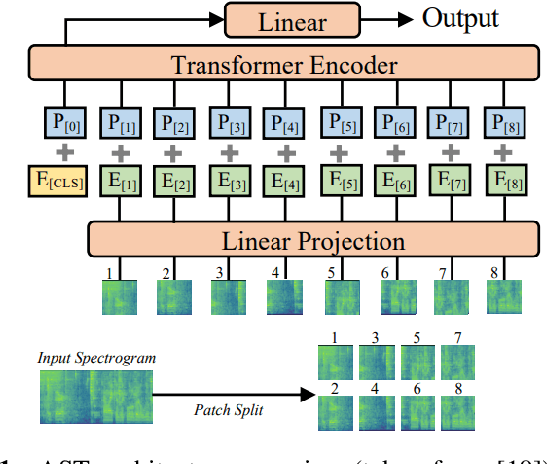
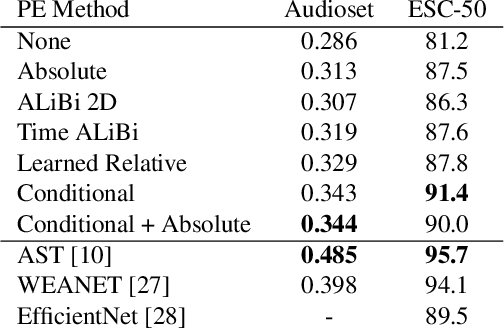
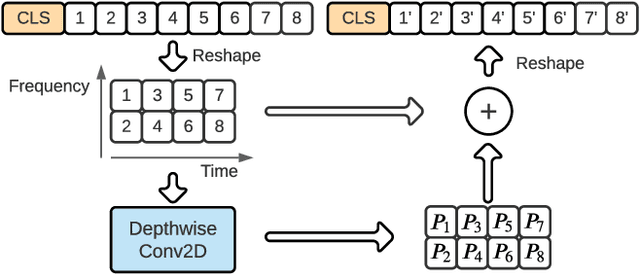
Transformers have revolutionized the world of deep learning, specially in the field of natural language processing. Recently, the Audio Spectrogram Transformer (AST) was proposed for audio classification, leading to state of the art results in several datasets. However, in order for ASTs to outperform CNNs, pretraining with ImageNet is needed. In this paper, we study one component of the AST, the positional encoding, and propose several variants to improve the performance of ASTs trained from scratch, without ImageNet pretraining. Our best model, which incorporates conditional positional encodings, significantly improves performance on Audioset and ESC-50 compared to the original AST.
Simple and Cheap Setup for Timing Tapping Responses Synchronized to Auditory Stimuli
Apr 30, 2021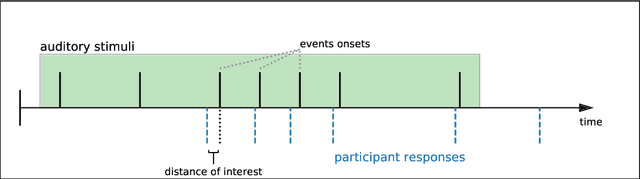
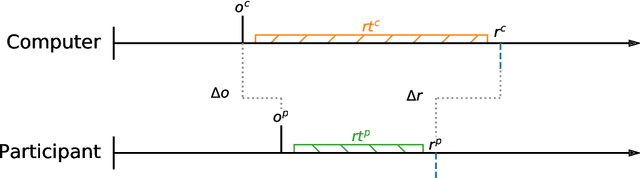

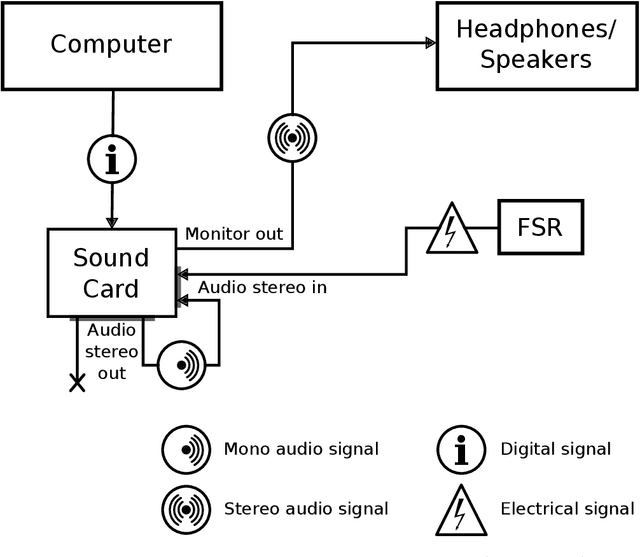
Measuring human capabilities to synchronize in time, adapt to perturbations to timing sequences or reproduce time intervals often require experimental setups that allow recording response times with millisecond precision. Most setups present auditory stimuli using either MIDI devices or specialized hardware such as Arduino and are often expensive or require calibration and advanced programming skills. Here, we present in detail an experimental setup that only requires an external sound card and minor electronic skills, works on a conventional PC, is cheaper than alternatives and requires almost no programming skills. It is intended for presenting any auditory stimuli and recording tapping response times with within 2 milliseconds precision (up to -2ms lag). This paper shows why desired accuracy in recording response times against auditory stimuli is difficult to achieve in conventional computer setups, presents an experimental setup to overcome this and explains in detail how to set it up and use the provided code. Finally, the code for analyzing the recorded tapping responses was evaluated, showing that no spurious or missing events were found in 94% of the analyzed recordings.
Emotion Recognition from Speech Using Wav2vec 2.0 Embeddings
Apr 08, 2021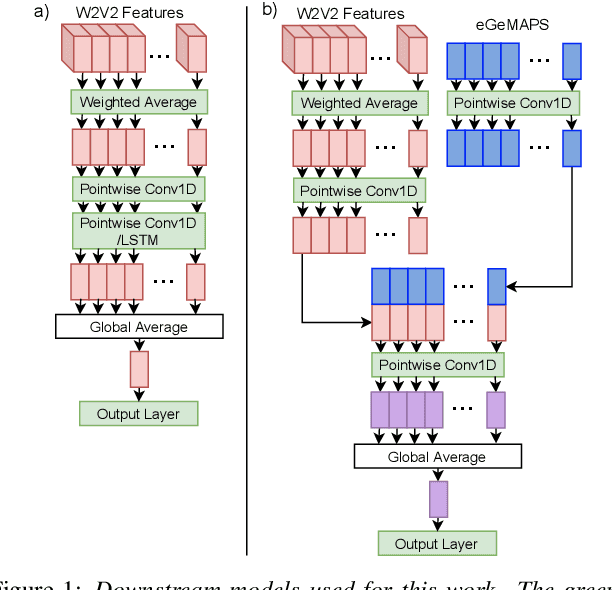
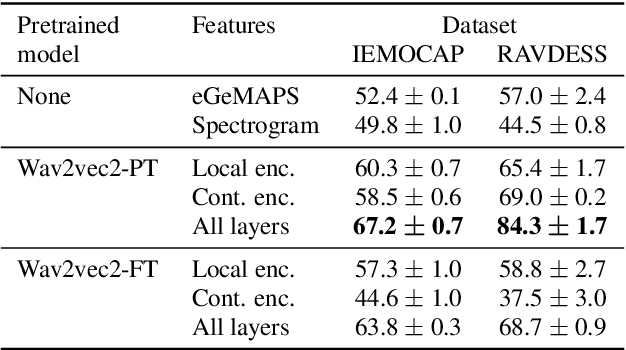
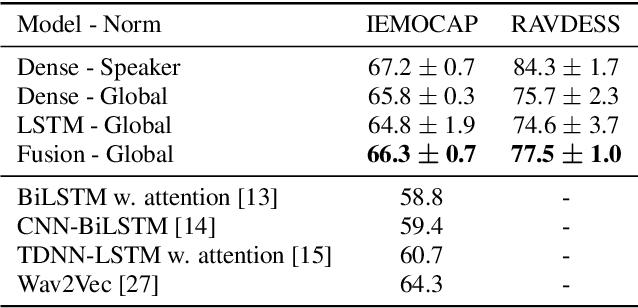
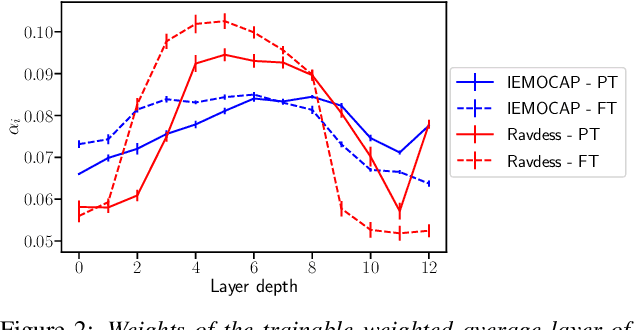
Emotion recognition datasets are relatively small, making the use of the more sophisticated deep learning approaches challenging. In this work, we propose a transfer learning method for speech emotion recognition where features extracted from pre-trained wav2vec 2.0 models are modeled using simple neural networks. We propose to combine the output of several layers from the pre-trained model using trainable weights which are learned jointly with the downstream model. Further, we compare performance using two different wav2vec 2.0 models, with and without finetuning for speech recognition. We evaluate our proposed approaches on two standard emotion databases IEMOCAP and RAVDESS, showing superior performance compared to results in the literature.
A Study on the Manifestation of Trust in Speech
Feb 09, 2021



Research has shown that trust is an essential aspect of human-computer interaction directly determining the degree to which the person is willing to use a system. An automatic prediction of the level of trust that a user has on a certain system could be used to attempt to correct potential distrust by having the system take relevant actions like, for example, apologizing or explaining its decisions. In this work, we explore the feasibility of automatically detecting the level of trust that a user has on a virtual assistant (VA) based on their speech. We developed a novel protocol for collecting speech data from subjects induced to have different degrees of trust in the skills of a VA. The protocol consists of an interactive session where the subject is asked to respond to a series of factual questions with the help of a virtual assistant. In order to induce subjects to either trust or distrust the VA's skills, they are first informed that the VA was previously rated by other users as being either good or bad; subsequently, the VA answers the subjects' questions consistently to its alleged abilities. All interactions are speech-based, with subjects and VAs communicating verbally, which allows the recording of speech produced under different trust conditions. Using this protocol, we collected a speech corpus in Argentine Spanish. We show clear evidence that the protocol effectively succeeded in influencing subjects into the desired mental state of either trusting or distrusting the agent's skills, and present results of a perceptual study of the degree of trust performed by expert listeners. Finally, we found that the subject's speech can be used to detect which type of VA they were using, which could be considered a proxy for the user's trust toward the VA's abilities, with an accuracy up to 76%, compared to a random baseline of 50%.
Detecting Distrust Towards the Skills of a Virtual Assistant Using Speech
Jul 30, 2020
Research has shown that trust is an essential aspect of human-computer interaction directly determining the degree to which the person is willing to use the system. An automatic prediction of the level of trust that a user has on a certain system could be used to attempt to correct potential distrust by having the system take relevant actions like, for example, explaining its actions more thoroughly. In this work, we explore the feasibility of automatically detecting the level of trust that a user has on a virtual assistant (VA) based on their speech. We use a dataset collected for this purpose, containing human-computer speech interactions where subjects were asked to answer various factual questions with the help of a virtual assistant, which they were led to believe was either very reliable or unreliable. We find that the subject's speech can be used to detect which type of VA they were using, which could be considered a proxy for the user's trust toward the VA's abilities, with an accuracy up to 76\%, compared to a random baseline of 50\%. These results are obtained using features that have been previously found useful for detecting speech directed to infants and non-native speakers.