 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing the impact of contextual information in hate speech detection
Oct 05, 2022
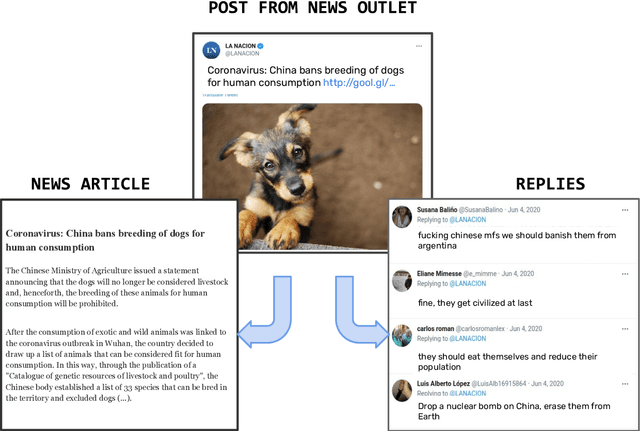
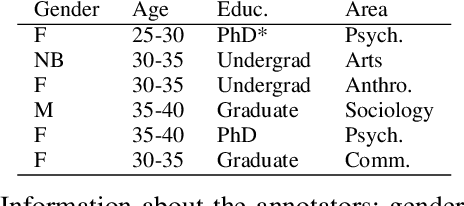
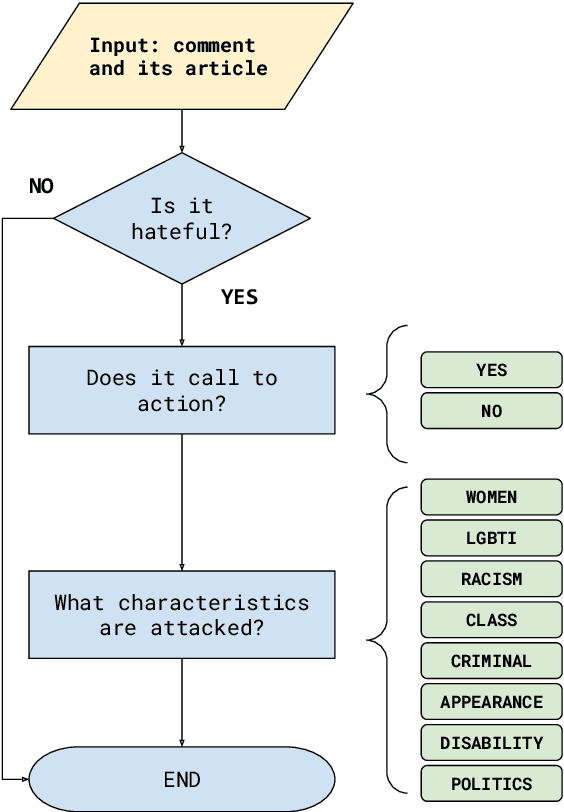
In recent years, hate speech has gained great relevance in social networks and other virtual media because of its intensity and its relationship with violent acts against members of protected groups. Due to the great amount of content generated by users, great effort has been made in the research and development of automatic tools to aid the analysis and moderation of this speech, at least in its most threatening forms. One of the limitations of current approaches to automatic hate speech detection is the lack of context. Most studies and resources are performed on data without context; that is, isolated messages without any type of conversational context or the topic being discussed. This restricts the available information to define if a post on a social network is hateful or not. In this work, we provide a novel corpus for contextualized hate speech detection based on user responses to news posts from media outlets on Twitter. This corpus was collected in the Rioplatense dialectal variety of Spanish and focuses on hate speech associated with the COVID-19 pandemic. Classification experiments using state-of-the-art techniques show evidence that adding contextual information improves hate speech detection performance for two proposed tasks (binary and multi-label prediction). We make our code, models, and corpus available for further research.
A Study on the Manifestation of Trust in Speech
Feb 09, 2021



Research has shown that trust is an essential aspect of human-computer interaction directly determining the degree to which the person is willing to use a system. An automatic prediction of the level of trust that a user has on a certain system could be used to attempt to correct potential distrust by having the system take relevant actions like, for example, apologizing or explaining its decisions. In this work, we explore the feasibility of automatically detecting the level of trust that a user has on a virtual assistant (VA) based on their speech. We developed a novel protocol for collecting speech data from subjects induced to have different degrees of trust in the skills of a VA. The protocol consists of an interactive session where the subject is asked to respond to a series of factual questions with the help of a virtual assistant. In order to induce subjects to either trust or distrust the VA's skills, they are first informed that the VA was previously rated by other users as being either good or bad; subsequently, the VA answers the subjects' questions consistently to its alleged abilities. All interactions are speech-based, with subjects and VAs communicating verbally, which allows the recording of speech produced under different trust conditions. Using this protocol, we collected a speech corpus in Argentine Spanish. We show clear evidence that the protocol effectively succeeded in influencing subjects into the desired mental state of either trusting or distrusting the agent's skills, and present results of a perceptual study of the degree of trust performed by expert listeners. Finally, we found that the subject's speech can be used to detect which type of VA they were using, which could be considered a proxy for the user's trust toward the VA's abilities, with an accuracy up to 76%, compared to a random baseline of 50%.
Detecting Distrust Towards the Skills of a Virtual Assistant Using Speech
Jul 30, 2020
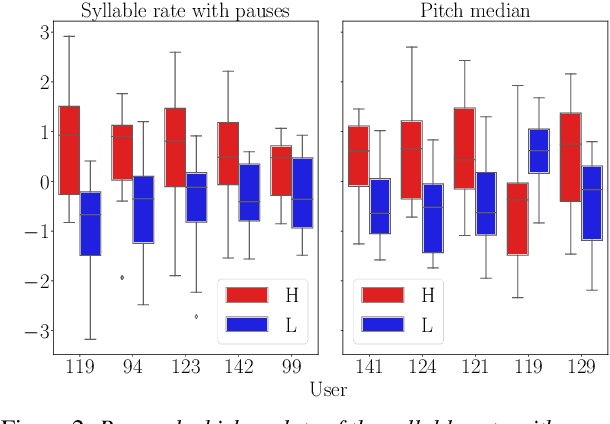
Research has shown that trust is an essential aspect of human-computer interaction directly determining the degree to which the person is willing to use the system. An automatic prediction of the level of trust that a user has on a certain system could be used to attempt to correct potential distrust by having the system take relevant actions like, for example, explaining its actions more thoroughly. In this work, we explore the feasibility of automatically detecting the level of trust that a user has on a virtual assistant (VA) based on their speech. We use a dataset collected for this purpose, containing human-computer speech interactions where subjects were asked to answer various factual questions with the help of a virtual assistant, which they were led to believe was either very reliable or unreliable. We find that the subject's speech can be used to detect which type of VA they were using, which could be considered a proxy for the user's trust toward the VA's abilities, with an accuracy up to 76\%, compared to a random baseline of 50\%. These results are obtained using features that have been previously found useful for detecting speech directed to infants and non-native speakers.
Exploiting user-frequency information for mining regionalisms from Social Media texts
Jul 10, 2019



The task of detecting regionalisms (expressions or words used in certain regions) has traditionally relied on the use of questionnaires and surveys, and has also heavily depended on the expertise and intuition of the surveyor. The irruption of Social Media and its microblogging services has produced an unprecedented wealth of content, mainly informal text generated by users, opening new opportunities for linguists to extend their studies of language variation. Previous work on automatic detection of regionalisms depended mostly on word frequencies. In this work, we present a novel metric based on Information Theory that incorporates user frequency. We tested this metric on a corpus of Argentinian Spanish tweets in two ways: via manual annotation of the relevance of the retrieved terms, and also as a feature selection method for geolocation of users. In either case, our metric outperformed other techniques based solely in word frequency, suggesting that measuring the amount of users that produce a word is informative. This tool has helped lexicographers discover several unregistered words of Argentinian Spanish, as well as different meanings assigned to registered words.