 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Large Language Models for Hate Speech Detection in Rioplatense Spanish
Oct 16, 2024Hate speech detection deals with many language variants, slang, slurs, expression modalities, and cultural nuances. This outlines the importance of working with specific corpora, when addressing hate speech within the scope of Natural Language Processing, recently revolutionized by the irruption of Large Language Models. This work presents a brief analysis of the performance of large language models in the detection of Hate Speech for Rioplatense Spanish. We performed classification experiments leveraging chain-of-thought reasoning with ChatGPT 3.5, Mixtral, and Aya, comparing their results with those of a state-of-the-art BERT classifier. These experiments outline that, even if large language models show a lower precision compared to the fine-tuned BERT classifier and, in some cases, they find hard-to-get slurs or colloquialisms, they still are sensitive to highly nuanced cases (particularly, homophobic/transphobic hate speech). We make our code and models publicly available for future research.
MessIRve: A Large-Scale Spanish Information Retrieval Dataset
Sep 09, 2024
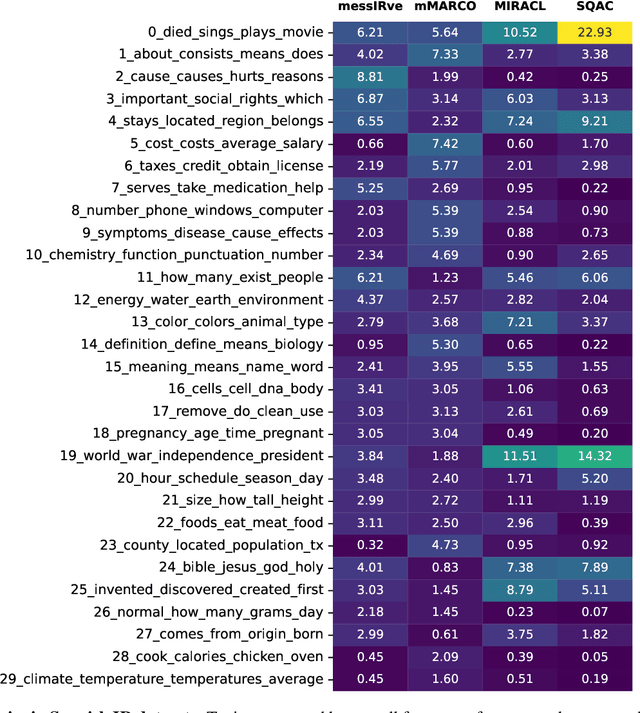

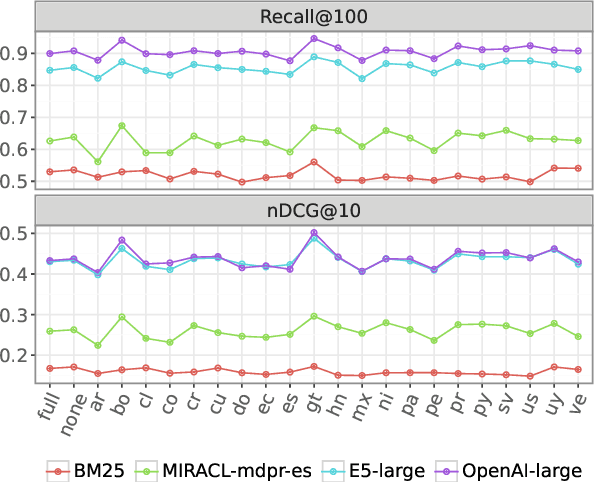
Information retrieval (IR) is the task of finding relevant documents in response to a user query. Although Spanish is the second most spoken native language, current IR benchmarks lack Spanish data, hindering the development of information access tools for Spanish speakers. We introduce MessIRve, a large-scale Spanish IR dataset with around 730 thousand queries from Google's autocomplete API and relevant documents sourced from Wikipedia. MessIRve's queries reflect diverse Spanish-speaking regions, unlike other datasets that are translated from English or do not consider dialectal variations. The large size of the dataset allows it to cover a wide variety of topics, unlike smaller datasets. We provide a comprehensive description of the dataset, comparisons with existing datasets, and baseline evaluations of prominent IR models. Our contributions aim to advance Spanish IR research and improve information access for Spanish speakers.
Assessing the impact of contextual information in hate speech detection
Oct 05, 2022
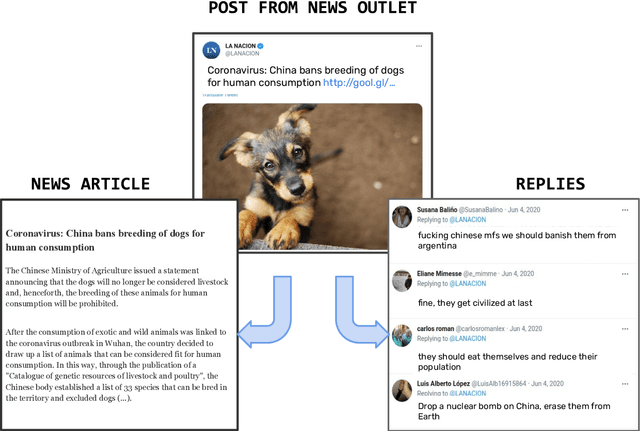
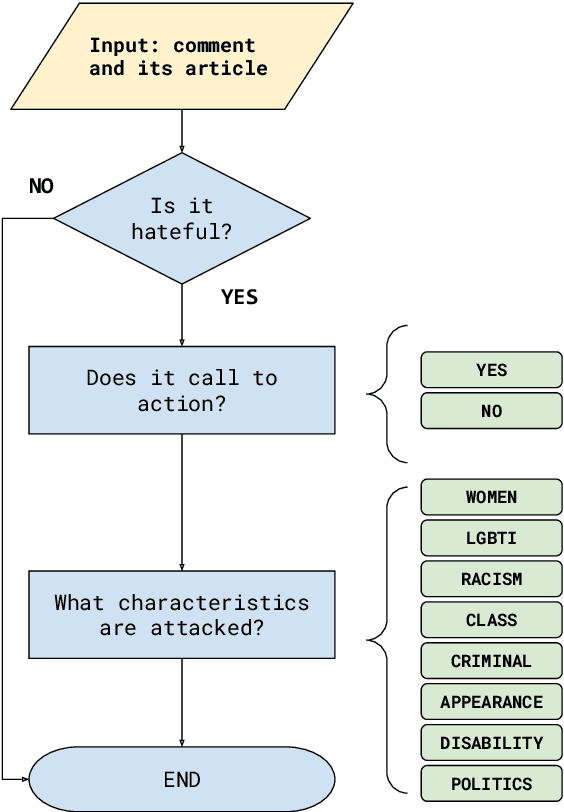
In recent years, hate speech has gained great relevance in social networks and other virtual media because of its intensity and its relationship with violent acts against members of protected groups. Due to the great amount of content generated by users, great effort has been made in the research and development of automatic tools to aid the analysis and moderation of this speech, at least in its most threatening forms. One of the limitations of current approaches to automatic hate speech detection is the lack of context. Most studies and resources are performed on data without context; that is, isolated messages without any type of conversational context or the topic being discussed. This restricts the available information to define if a post on a social network is hateful or not. In this work, we provide a novel corpus for contextualized hate speech detection based on user responses to news posts from media outlets on Twitter. This corpus was collected in the Rioplatense dialectal variety of Spanish and focuses on hate speech associated with the COVID-19 pandemic. Classification experiments using state-of-the-art techniques show evidence that adding contextual information improves hate speech detection performance for two proposed tasks (binary and multi-label prediction). We make our code, models, and corpus available for further research.
A Spanish dataset for Targeted Sentiment Analysis of political headlines
Aug 30, 2022
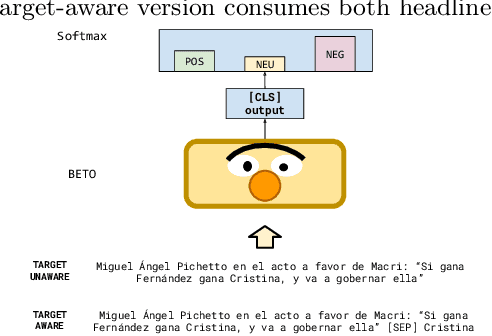
Subjective texts have been studied by several works as they can induce certain behaviours in their users. Most work focuses on user-generated texts in social networks, but some other texts also comprise opinions on certain topics and could influence judgement criteria during political decisions. In this work, we address the task of Targeted Sentiment Analysis for the domain of news headlines, published by the main outlets during the 2019 Argentinean Presidential Elections. For this purpose, we present a polarity dataset of 1,976 headlines mentioning candidates in the 2019 elections at the target level. Preliminary experiments with state-of-the-art classification algorithms based on pre-trained linguistic models suggest that target information is helpful for this task. We make our data and pre-trained models publicly available.
RoBERTuito: a pre-trained language model for social media text in Spanish
Nov 18, 2021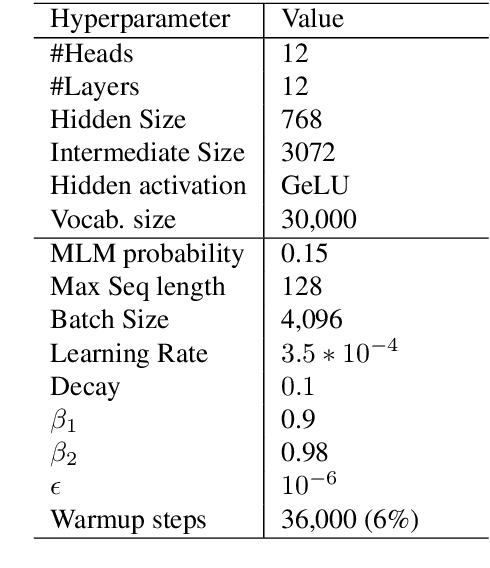


Since BERT appeared, Transformer language models and transfer learning have become state-of-the-art for Natural Language Understanding tasks. Recently, some works geared towards pre-training, specially-crafted models for particular domains, such as scientific papers, medical documents, and others. In this work, we present RoBERTuito, a pre-trained language model for user-generated content in Spanish. We trained RoBERTuito on 500 million tweets in Spanish. Experiments on a benchmark of 4 tasks involving user-generated text showed that RoBERTuito outperformed other pre-trained language models for Spanish. In order to help further research, we make RoBERTuito publicly available at the HuggingFace model hub.
pysentimiento: A Python Toolkit for Sentiment Analysis and SocialNLP tasks
Jun 17, 2021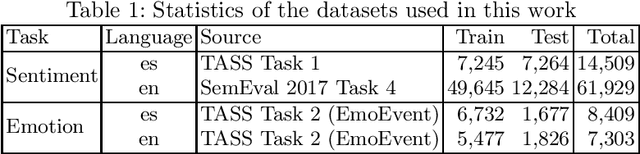
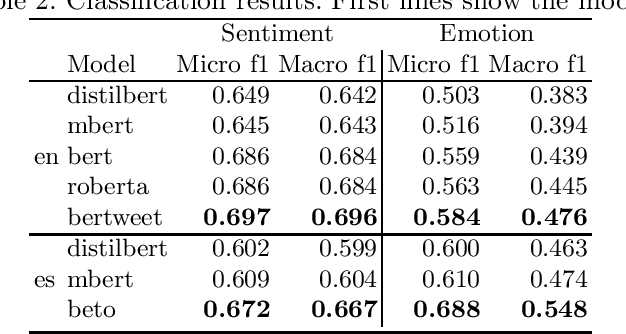
Extracting opinions from texts has gathered a lot of interest in the last years, as we are experiencing an unprecedented volume of user-generated content in social networks and other places. A problem that social researchers find in using opinion mining tools is that they are usually behind commercial APIs and unavailable for other languages than English. To address these issues, we present pysentimiento, a multilingual Python toolkit for Sentiment Analysis and other Social NLP tasks. This open-source library brings state-of-the-art models for Spanish and English in a black-box fashion, allowing researchers to easily access these techniques.
ANDES at SemEval-2020 Task 12: A jointly-trained BERT multilingual model for offensive language detection
Aug 13, 2020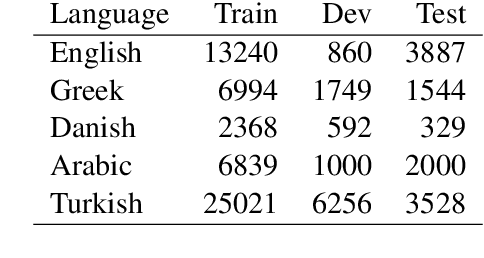
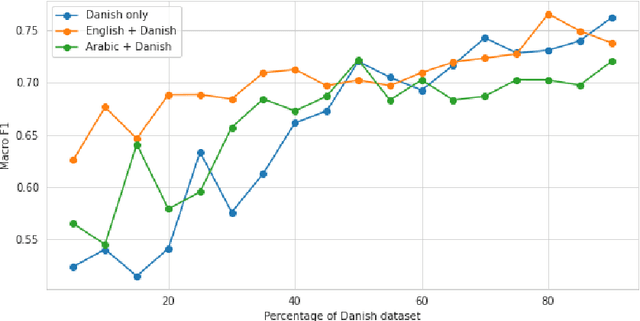
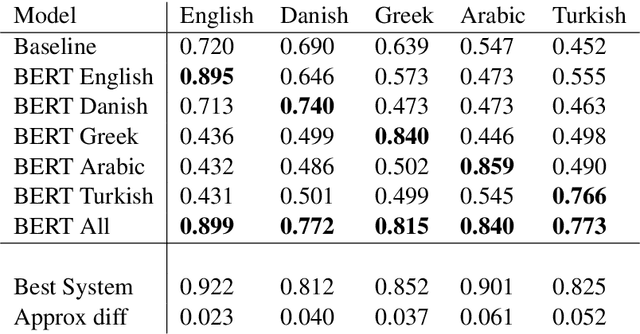
This paper describes our participation in SemEval-2020 Task 12: Multilingual Offensive Language Detection. We jointly-trained a single model by fine-tuning Multilingual BERT to tackle the task across all the proposed languages: English, Danish, Turkish, Greek and Arabic. Our single model had competitive results, with a performance close to top-performing systems in spite of sharing the same parameters across all languages. Zero-shot and few-shot experiments were also conducted to analyze the transference performance among these languages. We make our code public for further research
Exploiting user-frequency information for mining regionalisms from Social Media texts
Jul 10, 2019



The task of detecting regionalisms (expressions or words used in certain regions) has traditionally relied on the use of questionnaires and surveys, and has also heavily depended on the expertise and intuition of the surveyor. The irruption of Social Media and its microblogging services has produced an unprecedented wealth of content, mainly informal text generated by users, opening new opportunities for linguists to extend their studies of language variation. Previous work on automatic detection of regionalisms depended mostly on word frequencies. In this work, we present a novel metric based on Information Theory that incorporates user frequency. We tested this metric on a corpus of Argentinian Spanish tweets in two ways: via manual annotation of the relevance of the retrieved terms, and also as a feature selection method for geolocation of users. In either case, our metric outperformed other techniques based solely in word frequency, suggesting that measuring the amount of users that produce a word is informative. This tool has helped lexicographers discover several unregistered words of Argentinian Spanish, as well as different meanings assigned to registered words.