 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMessIRve: A Large-Scale Spanish Information Retrieval Dataset
Sep 09, 2024
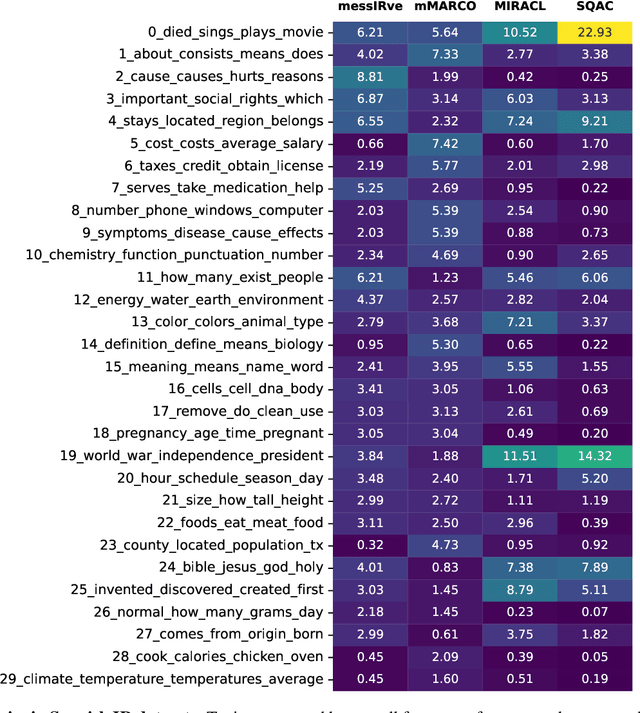

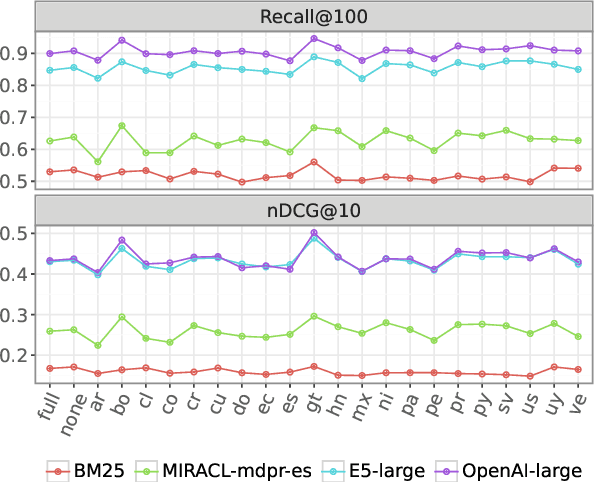
Information retrieval (IR) is the task of finding relevant documents in response to a user query. Although Spanish is the second most spoken native language, current IR benchmarks lack Spanish data, hindering the development of information access tools for Spanish speakers. We introduce MessIRve, a large-scale Spanish IR dataset with around 730 thousand queries from Google's autocomplete API and relevant documents sourced from Wikipedia. MessIRve's queries reflect diverse Spanish-speaking regions, unlike other datasets that are translated from English or do not consider dialectal variations. The large size of the dataset allows it to cover a wide variety of topics, unlike smaller datasets. We provide a comprehensive description of the dataset, comparisons with existing datasets, and baseline evaluations of prominent IR models. Our contributions aim to advance Spanish IR research and improve information access for Spanish speakers.
Which Argumentative Aspects of Hate Speech in Social Media can be reliably identified?
Jun 05, 2023With the increasing diversity of use cases of large language models, a more informative treatment of texts seems necessary. An argumentative analysis could foster a more reasoned usage of chatbots, text completion mechanisms or other applications. However, it is unclear which aspects of argumentation can be reliably identified and integrated in language models. In this paper, we present an empirical assessment of the reliability with which different argumentative aspects can be automatically identified in hate speech in social media. We have enriched the Hateval corpus (Basile et al. 2019) with a manual annotation of some argumentative components, adapted from Wagemans (2016)'s Periodic Table of Arguments. We show that some components can be identified with reasonable reliability. For those that present a high error ratio, we analyze the patterns of disagreement between expert annotators and errors in automatic procedures, and we propose adaptations of those categories that can be more reliably reproduced.
A Spanish dataset for Targeted Sentiment Analysis of political headlines
Aug 30, 2022
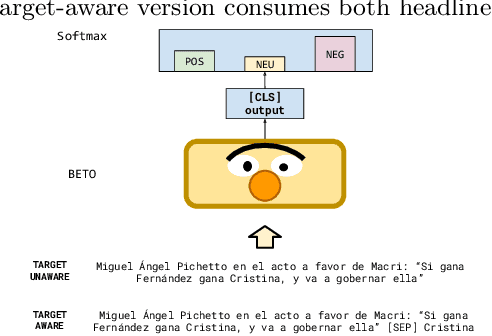
Subjective texts have been studied by several works as they can induce certain behaviours in their users. Most work focuses on user-generated texts in social networks, but some other texts also comprise opinions on certain topics and could influence judgement criteria during political decisions. In this work, we address the task of Targeted Sentiment Analysis for the domain of news headlines, published by the main outlets during the 2019 Argentinean Presidential Elections. For this purpose, we present a polarity dataset of 1,976 headlines mentioning candidates in the 2019 elections at the target level. Preliminary experiments with state-of-the-art classification algorithms based on pre-trained linguistic models suggest that target information is helpful for this task. We make our data and pre-trained models publicly available.