 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Neural Retrievers Prefer Certain Documents? Evidence of Learned Relevance Priors
Jun 01, 2026Neural retrievers are trained to estimate query-document relevance from annotated query-document pairs. Yet annotation protocols may not purely reflect relevance: they select only a subset of documents for labeling, and this selection can favor certain document types over others. We investigate whether supervised bi-encoder retrievers implicitly learn a document-level relevance prior: a query-independent signal encoded in their representation space as a side effect of training on annotated data. We estimate this prior by training simple classifiers on frozen document embeddings and evaluate three state-of-the-art retrievers across multiple IR benchmarks. We find that supervised neural retrievers encode relevance priors that generalize to unseen documents and are consistent across models. These priors create a findability gap: documents with lower prior are systematically harder to retrieve, even when genuinely relevant. This effect appears in supervised dense retrievers but is weaker and less consistent in BM25, and it persists under controlled matched-document comparisons. Using LLM-based explanations, we find that judged-relevant documents tend to be comprehensive, self-contained summaries of mainstream topics, while niche, fragmentary, or highly technical content is often left unjudged. Retrievers internalize this bias, ranking documents with these favored features higher than documents that lack them, independently of their actual relevance. Our findings expose a structural limitation of supervised retrieval: models trained on annotated data do not just learn relevance, but also the implicit document preferences in their training data.
MessIRve: A Large-Scale Spanish Information Retrieval Dataset
Sep 09, 2024
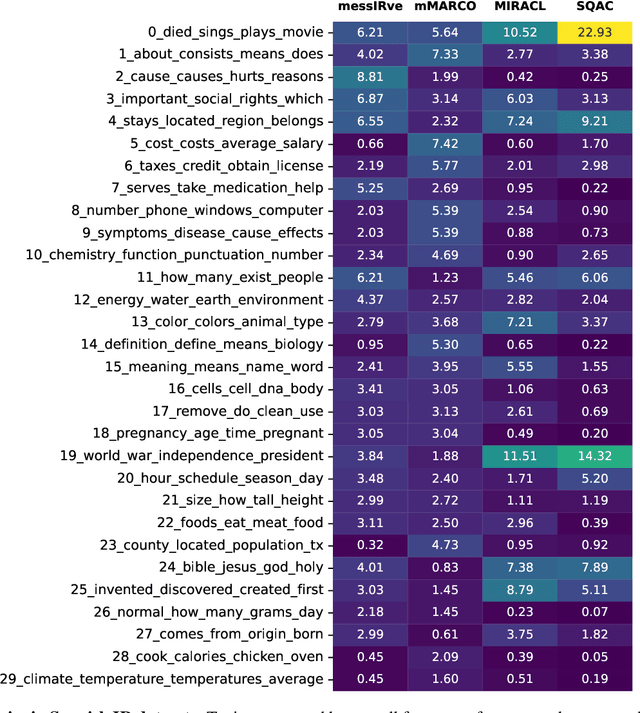

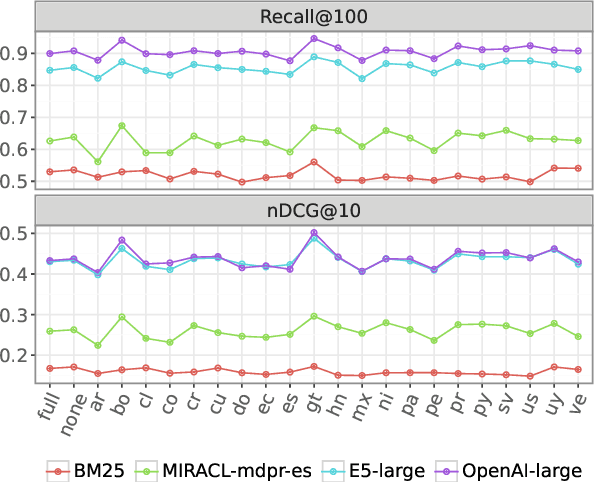
Information retrieval (IR) is the task of finding relevant documents in response to a user query. Although Spanish is the second most spoken native language, current IR benchmarks lack Spanish data, hindering the development of information access tools for Spanish speakers. We introduce MessIRve, a large-scale Spanish IR dataset with around 730 thousand queries from Google's autocomplete API and relevant documents sourced from Wikipedia. MessIRve's queries reflect diverse Spanish-speaking regions, unlike other datasets that are translated from English or do not consider dialectal variations. The large size of the dataset allows it to cover a wide variety of topics, unlike smaller datasets. We provide a comprehensive description of the dataset, comparisons with existing datasets, and baseline evaluations of prominent IR models. Our contributions aim to advance Spanish IR research and improve information access for Spanish speakers.
Mining Reasons For And Against Vaccination From Unstructured Data Using Nichesourcing and AI Data Augmentation
Jun 28, 2024



We present Reasons For and Against Vaccination (RFAV), a dataset for predicting reasons for and against vaccination, and scientific authorities used to justify them, annotated through nichesourcing and augmented using GPT4 and GPT3.5-Turbo. We show how it is possible to mine these reasons in non-structured text, under different task definitions, despite the high level of subjectivity involved and explore the impact of artificially augmented data using in-context learning with GPT4 and GPT3.5-Turbo. We publish the dataset and the trained models along with the annotation manual used to train annotators and define the task.
The Undesirable Dependence on Frequency of Gender Bias Metrics Based on Word Embeddings
Jan 02, 2023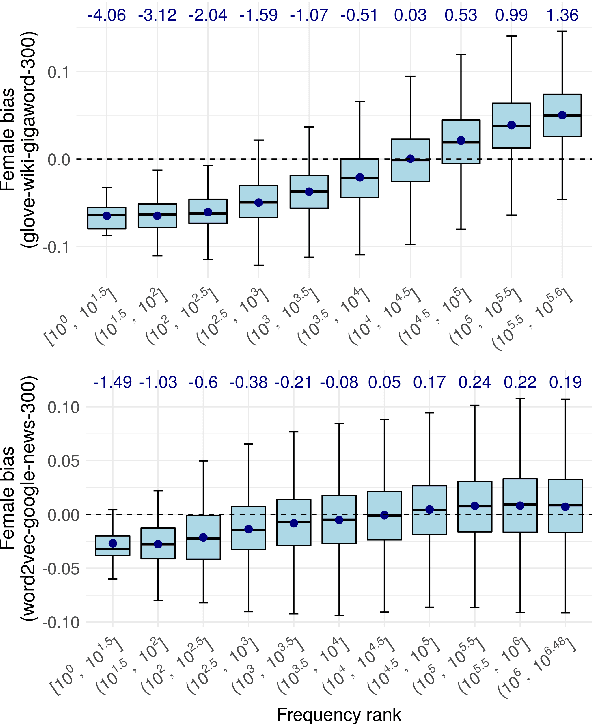

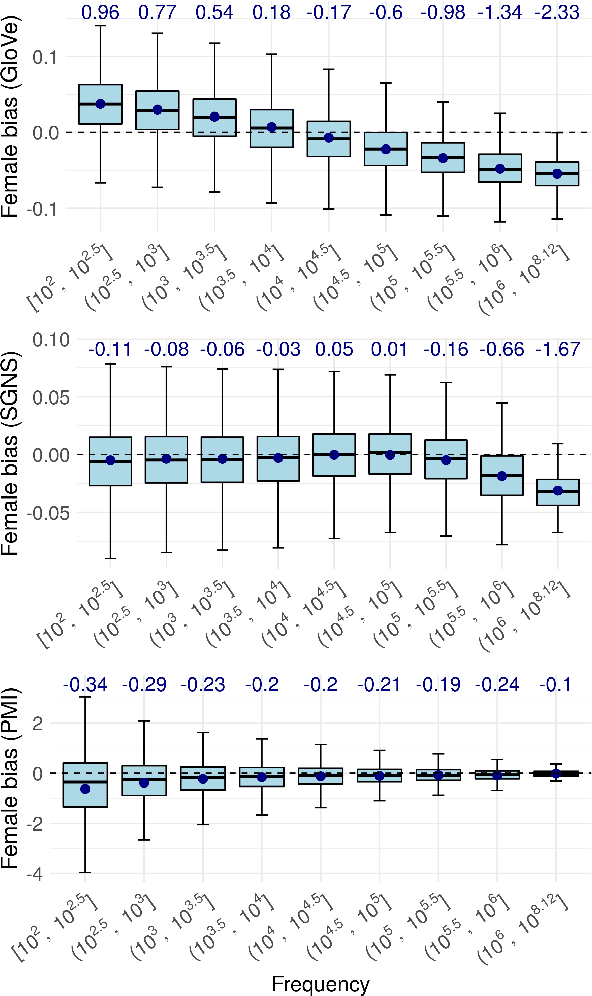

Numerous works use word embedding-based metrics to quantify societal biases and stereotypes in texts. Recent studies have found that word embeddings can capture semantic similarity but may be affected by word frequency. In this work we study the effect of frequency when measuring female vs. male gender bias with word embedding-based bias quantification methods. We find that Skip-gram with negative sampling and GloVe tend to detect male bias in high frequency words, while GloVe tends to return female bias in low frequency words. We show these behaviors still exist when words are randomly shuffled. This proves that the frequency-based effect observed in unshuffled corpora stems from properties of the metric rather than from word associations. The effect is spurious and problematic since bias metrics should depend exclusively on word co-occurrences and not individual word frequencies. Finally, we compare these results with the ones obtained with an alternative metric based on Pointwise Mutual Information. We find that this metric does not show a clear dependence on frequency, even though it is slightly skewed towards male bias across all frequencies.
The Dependence on Frequency of Word Embedding Similarity Measures
Nov 15, 2022



Recent research has shown that static word embeddings can encode word frequency information. However, little has been studied about this phenomenon and its effects on downstream tasks. In the present work, we systematically study the association between frequency and semantic similarity in several static word embeddings. We find that Skip-gram, GloVe and FastText embeddings tend to produce higher semantic similarity between high-frequency words than between other frequency combinations. We show that the association between frequency and similarity also appears when words are randomly shuffled. This proves that the patterns found are not due to real semantic associations present in the texts, but are an artifact produced by the word embeddings. Finally, we provide an example of how word frequency can strongly impact the measurement of gender bias with embedding-based metrics. In particular, we carry out a controlled experiment that shows that biases can even change sign or reverse their order by manipulating word frequencies.
On the interpretation and significance of bias metrics in texts: a PMI-based approach
Apr 13, 2021
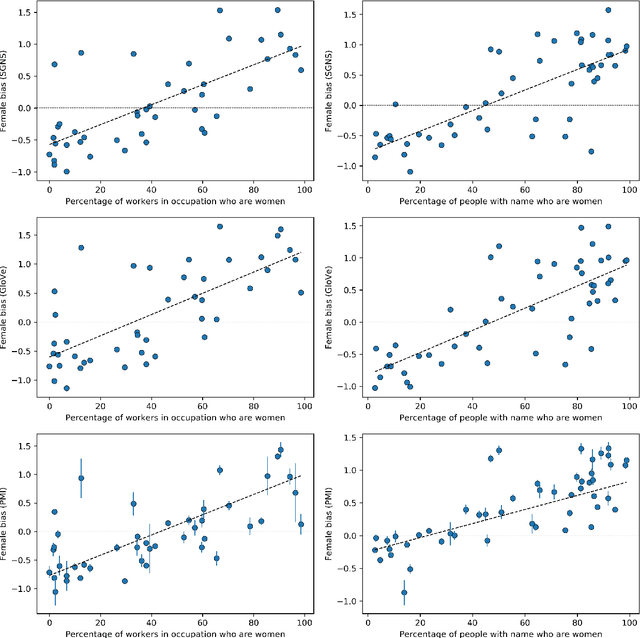

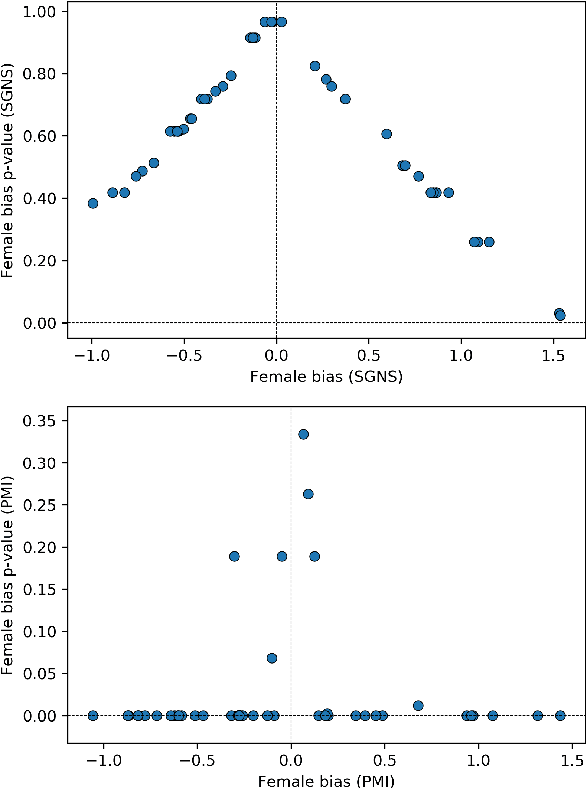
In recent years, the use of word embeddings has become popular to measure the presence of biases in texts. Despite the fact that these measures have been shown to be effective in detecting a wide variety of biases, metrics based on word embeddings lack transparency, explainability and interpretability. In this study, we propose a PMI-based metric to quantify biases in texts. We show that this metric can be approximated by an odds ratio, which allows estimating the confidence interval and statistical significance of textual bias. We also show that this PMI-based measure can be expressed as a function of conditional probabilities, providing a simple interpretation in terms of word co-occurrences. Our approach produces a performance comparable to GloVe-based and Skip-gram-based metrics in experiments of gender-occupation and gender-name associations. We discuss the advantages and disadvantages of using methods based on first-order vs second-order co-occurrences, from the point of view of the interpretability of the metric and the sparseness of the data.
Gender bias in magazines oriented to men and women: a computational approach
Nov 24, 2020

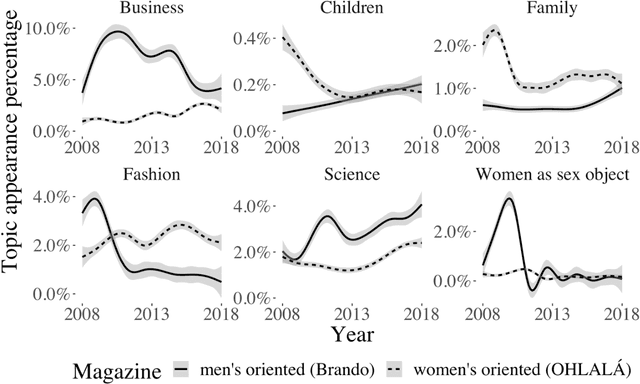

Cultural products are a source to acquire individual values and behaviours. Therefore, the differences in the content of the magazines aimed specifically at women or men are a means to create and reproduce gender stereotypes. In this study, we compare the content of a women-oriented magazine with that of a men-oriented one, both produced by the same editorial group, over a decade (2008-2018). With Topic Modelling techniques we identify the main themes discussed in the magazines and quantify how much the presence of these topics differs between magazines over time. Then, we performed a word-frequency analysis to validate this methodology and extend the analysis to other subjects that did not emerge automatically. Our results show that the frequency of appearance of the topics Family, Business and Women as sex objects, present an initial bias that tends to disappear over time. Conversely, in Fashion and Science topics, the initial differences between both magazines are maintained. Besides, we show that in 2012, the content associated with horoscope increased in the women-oriented magazine, generating a new gap that remained open over time. Also, we show a strong increase in the use of words associated with feminism since 2015 and specifically the word abortion in 2018. Overall, these computational tools allowed us to analyse more than 24,000 articles. Up to our knowledge, this is the first study to compare magazines in such a large dataset, a task that would have been prohibitive using manual content analysis methodologies.
Zero-shot Multi-Domain Dialog State Tracking Using Descriptive Rules
Sep 17, 2020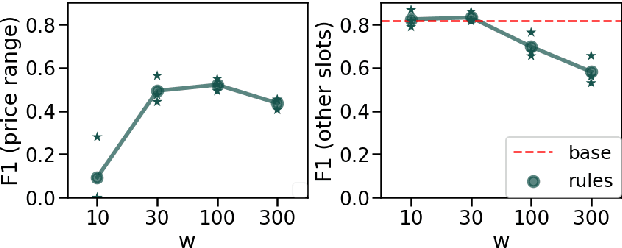
In this work, we present a framework for incorporating descriptive logical rules in state-of-the-art neural networks, enabling them to learn how to handle unseen labels without the introduction of any new training data. The rules are integrated into existing networks without modifying their architecture, through an additional term in the network's loss function that penalizes states of the network that do not obey the designed rules. As a case of study, the framework is applied to an existing neural-based Dialog State Tracker. Our experiments demonstrate that the inclusion of logical rules allows the prediction of unseen labels, without deteriorating the predictive capacity of the original system.
Corpus specificity in LSA and Word2vec: the role of out-of-domain documents
Dec 28, 2017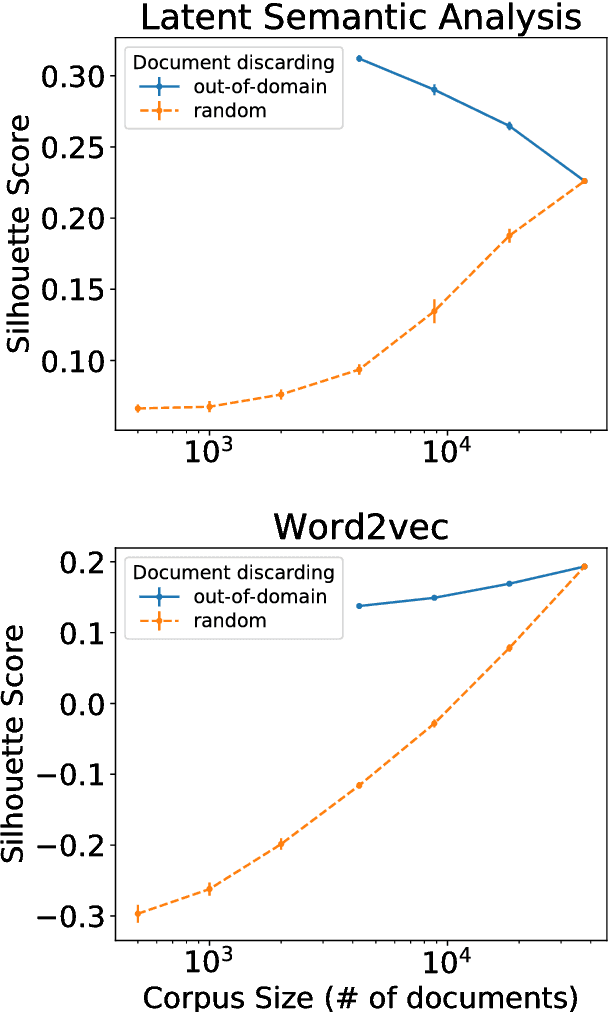
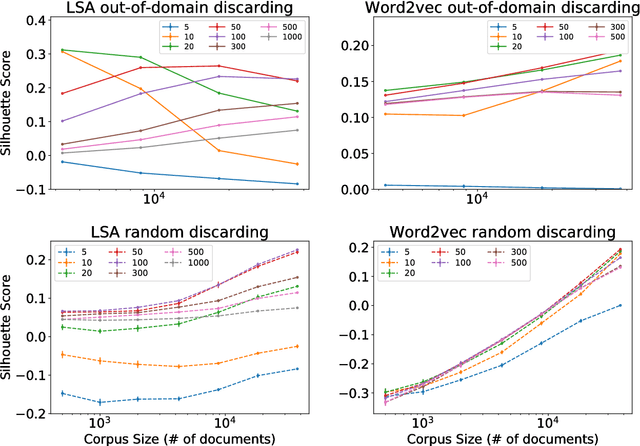
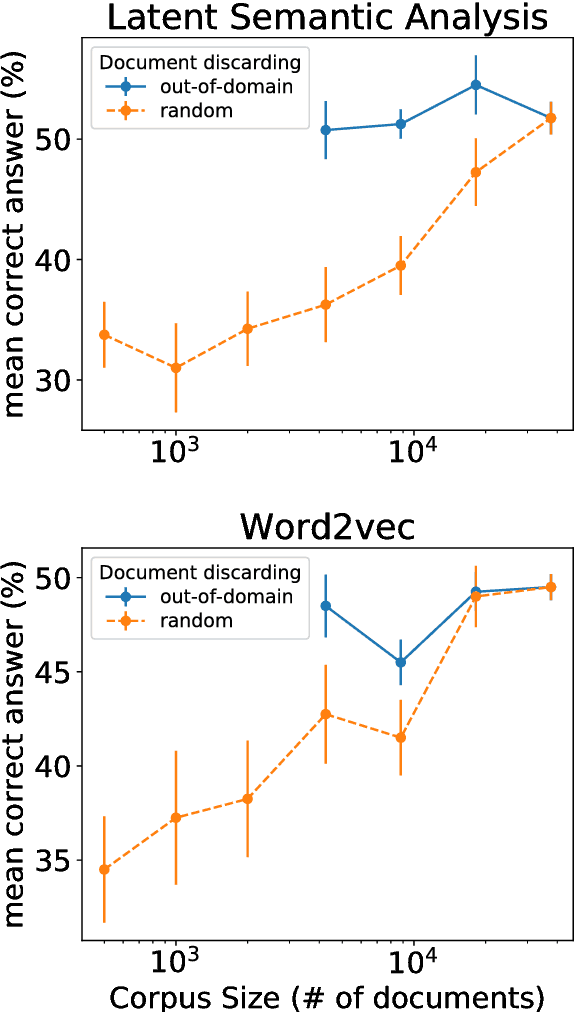
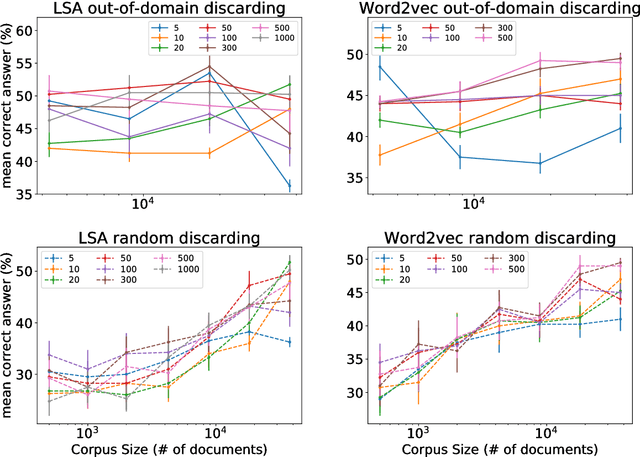
Latent Semantic Analysis (LSA) and Word2vec are some of the most widely used word embeddings. Despite the popularity of these techniques, the precise mechanisms by which they acquire new semantic relations between words remain unclear. In the present article we investigate whether LSA and Word2vec capacity to identify relevant semantic dimensions increases with size of corpus. One intuitive hypothesis is that the capacity to identify relevant dimensions should increase as the amount of data increases. However, if corpus size grow in topics which are not specific to the domain of interest, signal to noise ratio may weaken. Here we set to examine and distinguish these alternative hypothesis. To investigate the effect of corpus specificity and size in word-embeddings we study two ways for progressive elimination of documents: the elimination of random documents vs. the elimination of documents unrelated to a specific task. We show that Word2vec can take advantage of all the documents, obtaining its best performance when it is trained with the whole corpus. On the contrary, the specialization (removal of out-of-domain documents) of the training corpus, accompanied by a decrease of dimensionality, can increase LSA word-representation quality while speeding up the processing time. Furthermore, we show that the specialization without the decrease in LSA dimensionality can produce a strong performance reduction in specific tasks. From a cognitive-modeling point of view, we point out that LSA's word-knowledge acquisitions may not be efficiently exploiting higher-order co-occurrences and global relations, whereas Word2vec does.
Comparative study of LSA vs Word2vec embeddings in small corpora: a case study in dreams database
Apr 11, 2017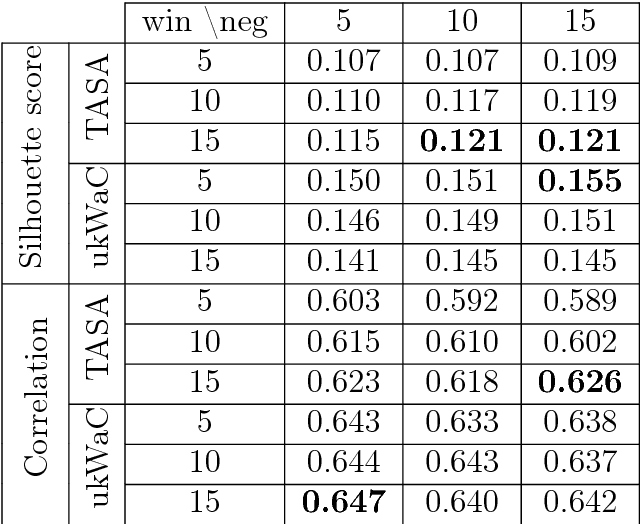
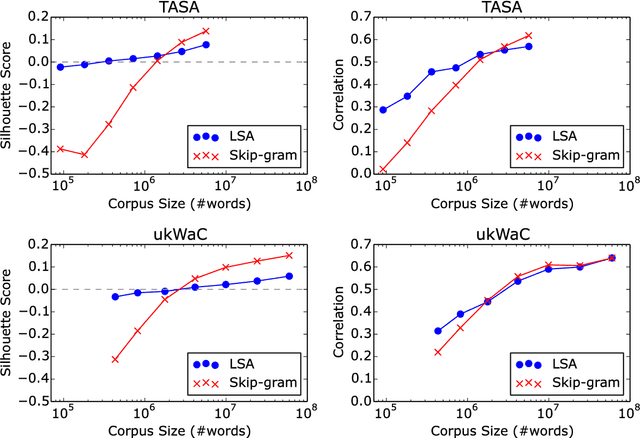
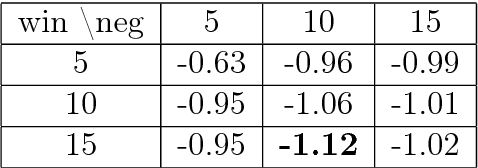
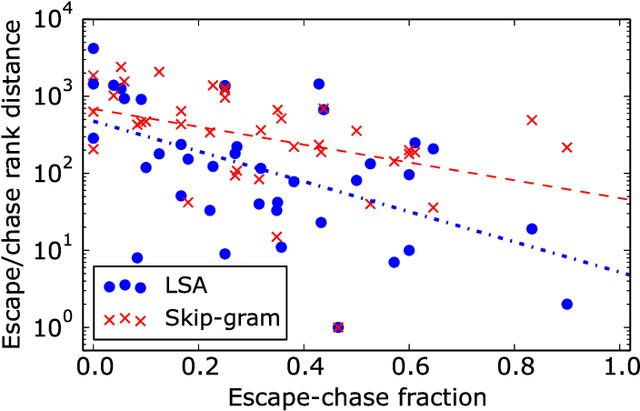
Word embeddings have been extensively studied in large text datasets. However, only a few studies analyze semantic representations of small corpora, particularly relevant in single-person text production studies. In the present paper, we compare Skip-gram and LSA capabilities in this scenario, and we test both techniques to extract relevant semantic patterns in single-series dreams reports. LSA showed better performance than Skip-gram in small size training corpus in two semantic tests. As a study case, we show that LSA can capture relevant words associations in dream reports series, even in cases of small number of dreams or low-frequency words. We propose that LSA can be used to explore words associations in dreams reports, which could bring new insight into this classic research area of psychology