 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLUE: New Benchmark Tasks for Spoken Language Understanding Evaluation on Natural Speech
Nov 19, 2021
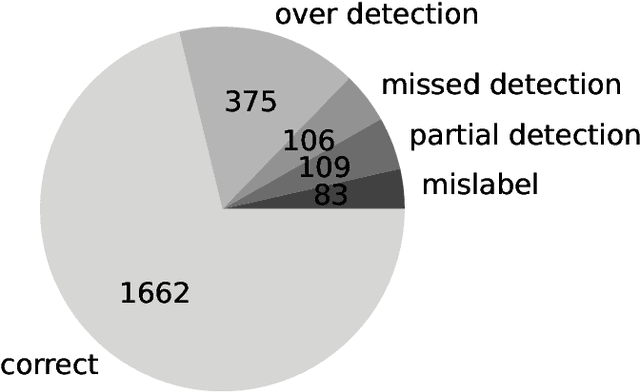

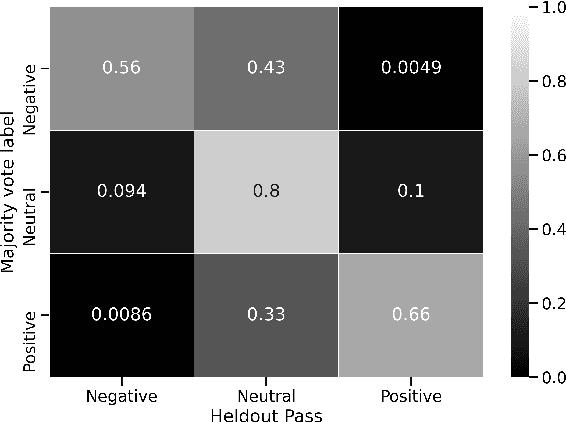
Progress in speech processing has been facilitated by shared datasets and benchmarks. Historically these have focused on automatic speech recognition (ASR), speaker identification, or other lower-level tasks. Interest has been growing in higher-level spoken language understanding tasks, including using end-to-end models, but there are fewer annotated datasets for such tasks. At the same time, recent work shows the possibility of pre-training generic representations and then fine-tuning for several tasks using relatively little labeled data. We propose to create a suite of benchmark tasks for Spoken Language Understanding Evaluation (SLUE) consisting of limited-size labeled training sets and corresponding evaluation sets. This resource would allow the research community to track progress, evaluate pre-trained representations for higher-level tasks, and study open questions such as the utility of pipeline versus end-to-end approaches. We present the first phase of the SLUE benchmark suite, consisting of named entity recognition, sentiment analysis, and ASR on the corresponding datasets. We focus on naturally produced (not read or synthesized) speech, and freely available datasets. We provide new transcriptions and annotations on subsets of the VoxCeleb and VoxPopuli datasets, evaluation metrics and results for baseline models, and an open-source toolkit to reproduce the baselines and evaluate new models.
Leveraging Pre-trained Language Model for Speech Sentiment Analysis
Jun 11, 2021

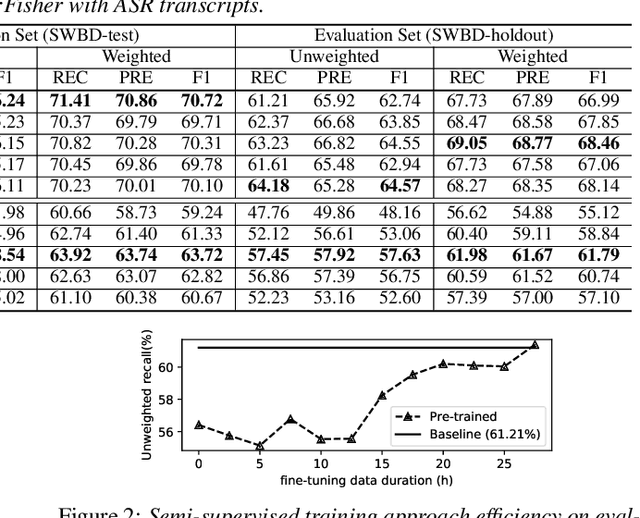

In this paper, we explore the use of pre-trained language models to learn sentiment information of written texts for speech sentiment analysis. First, we investigate how useful a pre-trained language model would be in a 2-step pipeline approach employing Automatic Speech Recognition (ASR) and transcripts-based sentiment analysis separately. Second, we propose a pseudo label-based semi-supervised training strategy using a language model on an end-to-end speech sentiment approach to take advantage of a large, but unlabeled speech dataset for training. Although spoken and written texts have different linguistic characteristics, they can complement each other in understanding sentiment. Therefore, the proposed system can not only model acoustic characteristics to bear sentiment-specific information in speech signals, but learn latent information to carry sentiments in the text representation. In these experiments, we demonstrate the proposed approaches improve F1 scores consistently compared to systems without a language model. Moreover, we also show that the proposed framework can reduce 65% of human supervision by leveraging a large amount of data without human sentiment annotation and boost performance in a low-resource condition where the human sentiment annotation is not available enough.
Zero-shot Multi-Domain Dialog State Tracking Using Descriptive Rules
Sep 17, 2020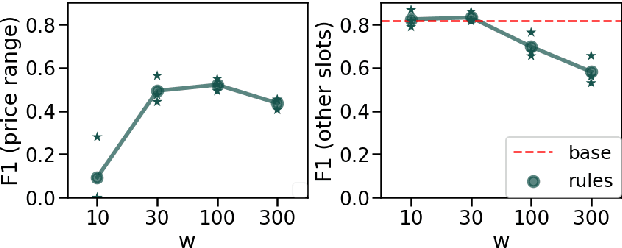
In this work, we present a framework for incorporating descriptive logical rules in state-of-the-art neural networks, enabling them to learn how to handle unseen labels without the introduction of any new training data. The rules are integrated into existing networks without modifying their architecture, through an additional term in the network's loss function that penalizes states of the network that do not obey the designed rules. As a case of study, the framework is applied to an existing neural-based Dialog State Tracker. Our experiments demonstrate that the inclusion of logical rules allows the prediction of unseen labels, without deteriorating the predictive capacity of the original system.