 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoshiRAG: Asynchronous Knowledge Retrieval for Full-Duplex Speech Language Models
Apr 14, 2026Speech-to-speech language models have recently emerged to enhance the naturalness of conversational AI. In particular, full-duplex models are distinguished by their real-time interactivity, including handling of pauses, interruptions, and backchannels. However, improving their factuality remains an open challenge. While scaling the model size could address this gap, it would make real-time inference prohibitively expensive. In this work, we propose MoshiRAG, a modular approach that combines a compact full-duplex interface with selective retrieval to access more powerful knowledge sources. Our asynchronous framework enables the model to identify knowledge-demanding queries and ground its responses in external information. By leveraging the natural temporal gap between response onset and the delivery of core information, the retrieval process can be completed while maintaining a natural conversation flow. With this approach, MoshiRAG achieves factuality comparable to the best publicly released non-duplex speech language models while preserving the interactivity inherent to full-duplex systems. Moreover, our flexible design supports plug-and-play retrieval methods without retraining and demonstrates strong performance on out-of-domain mathematical reasoning tasks.
The ML-SUPERB 2.0 Challenge: Towards Inclusive ASR Benchmarking for All Language Varieties
Sep 08, 2025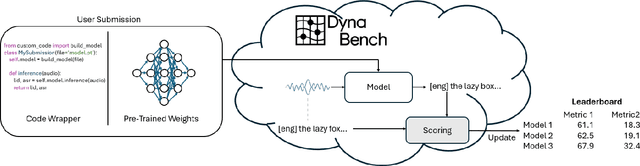
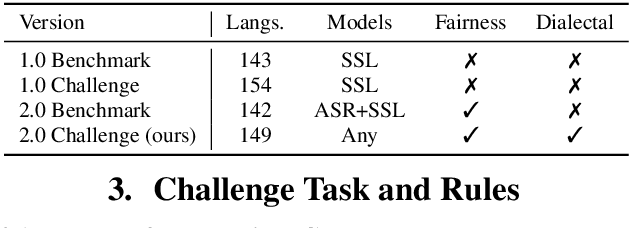
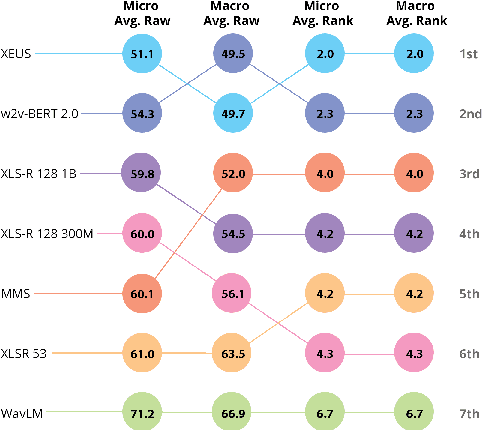
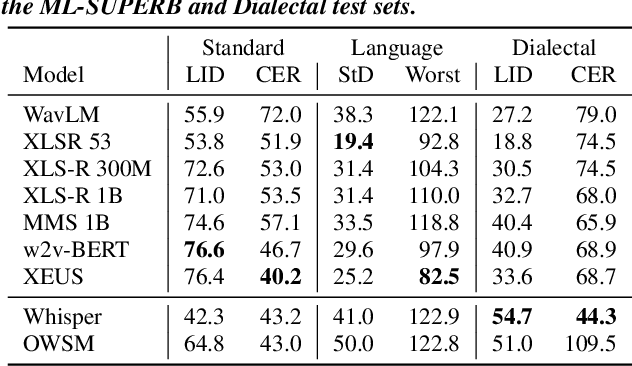
Recent improvements in multilingual ASR have not been equally distributed across languages and language varieties. To advance state-of-the-art (SOTA) ASR models, we present the Interspeech 2025 ML-SUPERB 2.0 Challenge. We construct a new test suite that consists of data from 200+ languages, accents, and dialects to evaluate SOTA multilingual speech models. The challenge also introduces an online evaluation server based on DynaBench, allowing for flexibility in model design and architecture for participants. The challenge received 5 submissions from 3 teams, all of which outperformed our baselines. The best-performing submission achieved an absolute improvement in LID accuracy of 23% and a reduction in CER of 18% when compared to the best baseline on a general multilingual test set. On accented and dialectal data, the best submission obtained 30.2% lower CER and 15.7% higher LID accuracy, showing the importance of community challenges in making speech technologies more inclusive.
On The Landscape of Spoken Language Models: A Comprehensive Survey
Apr 11, 2025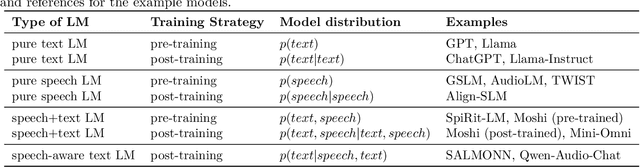
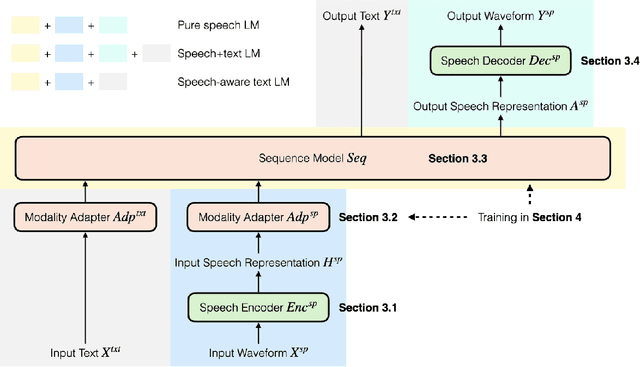
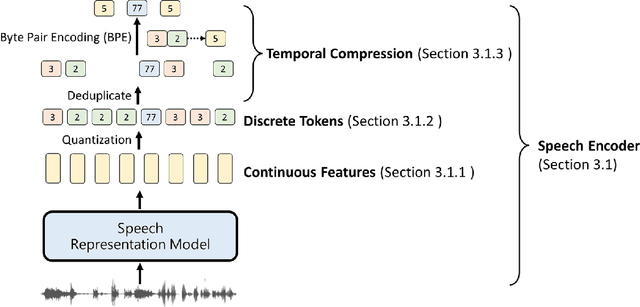
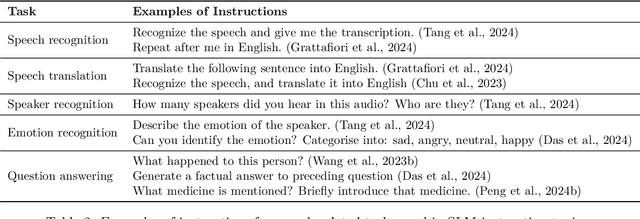
The field of spoken language processing is undergoing a shift from training custom-built, task-specific models toward using and optimizing spoken language models (SLMs) which act as universal speech processing systems. This trend is similar to the progression toward universal language models that has taken place in the field of (text) natural language processing. SLMs include both "pure" language models of speech -- models of the distribution of tokenized speech sequences -- and models that combine speech encoders with text language models, often including both spoken and written input or output. Work in this area is very diverse, with a range of terminology and evaluation settings. This paper aims to contribute an improved understanding of SLMs via a unifying literature survey of recent work in the context of the evolution of the field. Our survey categorizes the work in this area by model architecture, training, and evaluation choices, and describes some key challenges and directions for future work.
CTC-DRO: Robust Optimization for Reducing Language Disparities in Speech Recognition
Feb 03, 2025Modern deep learning models often achieve high overall performance, but consistently fail on specific subgroups. Group distributionally robust optimization (group DRO) addresses this problem by minimizing the worst-group loss, but it fails when group losses misrepresent performance differences between groups. This is common in domains like speech, where the widely used connectionist temporal classification (CTC) loss scales with input length and varies with linguistic and acoustic properties, leading to spurious differences between group losses. We present CTC-DRO, which addresses the shortcomings of the group DRO objective by smoothing the group weight update to prevent overemphasis on consistently high-loss groups, while using input length-matched batching to mitigate CTC's scaling issues. We evaluate CTC-DRO on the task of multilingual automatic speech recognition (ASR) across five language sets from the ML-SUPERB 2.0 benchmark. CTC-DRO consistently outperforms group DRO and CTC-based baseline models, reducing the worst-language error by up to 65.9% and the average error by up to 47.7%. CTC-DRO can be applied to ASR with minimal computational costs, and offers the potential for reducing group disparities in other domains with similar challenges.
Chunk-Distilled Language Modeling
Dec 31, 2024We introduce Chunk-Distilled Language Modeling (CD-LM), an approach to text generation that addresses two challenges in current large language models (LLMs): the inefficiency of token-level generation, and the difficulty of adapting to new data and knowledge. Our method combines deep network-based LLMs with a straightforward retrieval module, which allows the generation of multi-token text chunks at a single decoding step. Our retrieval framework enables flexible construction of model- or domain-specific datastores, either leveraging the internal knowledge of existing models, or incorporating expert insights from human-annotated corpora. This adaptability allows for enhanced control over the language model's distribution without necessitating additional training. We present the CD-LM formulation along with performance metrics demonstrating its ability to improve language model performance and efficiency across a diverse set of downstream tasks. Code and data will be made publicly available.
SHuBERT: Self-Supervised Sign Language Representation Learning via Multi-Stream Cluster Prediction
Nov 25, 2024
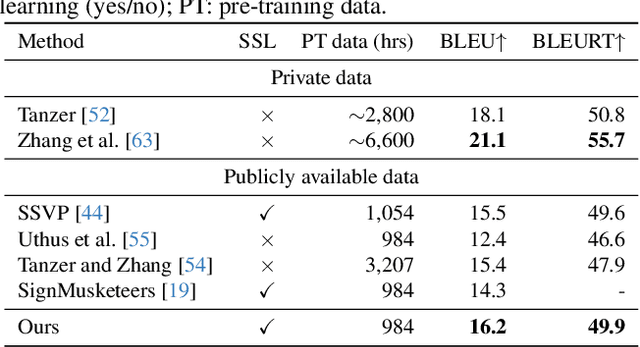

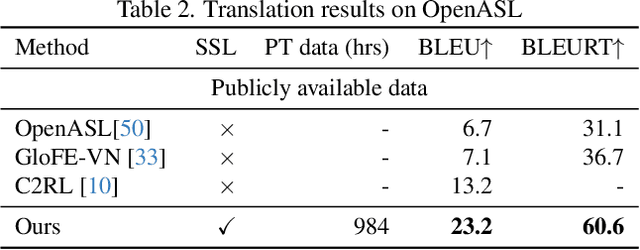
Sign language processing has traditionally relied on task-specific models,limiting the potential for transfer learning across tasks. We introduce SHuBERT (Sign Hidden-Unit BERT), a self-supervised transformer encoder that learns strong representations from approximately 1,000 hours of American Sign Language (ASL) video content. Inspired by the success of the HuBERT speech representation model, SHuBERT adapts masked prediction for multi-stream visual sign language input, learning to predict multiple targets for corresponding to clustered hand, face, and body pose streams. SHuBERT achieves state-of-the-art performance across multiple benchmarks. On sign language translation, it outperforms prior methods trained on publicly available data on the How2Sign (+0.7 BLEU), OpenASL (+10.0 BLEU), and FLEURS-ASL (+0.3 BLEU) benchmarks. Similarly for isolated sign language recognition, SHuBERT's accuracy surpasses that of specialized models on ASL-Citizen (+5\%) and SEM-LEX (+20.6\%), while coming close to them on WLASL2000 (-3\%). Ablation studies confirm the contribution of each component of the approach.
Dynamic-SUPERB Phase-2: A Collaboratively Expanding Benchmark for Measuring the Capabilities of Spoken Language Models with 180 Tasks
Nov 08, 2024



Multimodal foundation models, such as Gemini and ChatGPT, have revolutionized human-machine interactions by seamlessly integrating various forms of data. Developing a universal spoken language model that comprehends a wide range of natural language instructions is critical for bridging communication gaps and facilitating more intuitive interactions. However, the absence of a comprehensive evaluation benchmark poses a significant challenge. We present Dynamic-SUPERB Phase-2, an open and evolving benchmark for the comprehensive evaluation of instruction-based universal speech models. Building upon the first generation, this second version incorporates 125 new tasks contributed collaboratively by the global research community, expanding the benchmark to a total of 180 tasks, making it the largest benchmark for speech and audio evaluation. While the first generation of Dynamic-SUPERB was limited to classification tasks, Dynamic-SUPERB Phase-2 broadens its evaluation capabilities by introducing a wide array of novel and diverse tasks, including regression and sequence generation, across speech, music, and environmental audio. Evaluation results indicate that none of the models performed well universally. SALMONN-13B excelled in English ASR, while WavLLM demonstrated high accuracy in emotion recognition, but current models still require further innovations to handle a broader range of tasks. We will soon open-source all task data and the evaluation pipeline.
Speech Recognition for Analysis of Police Radio Communication
Sep 17, 2024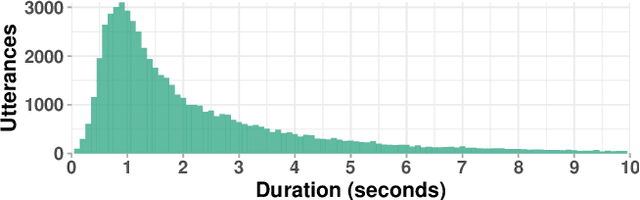
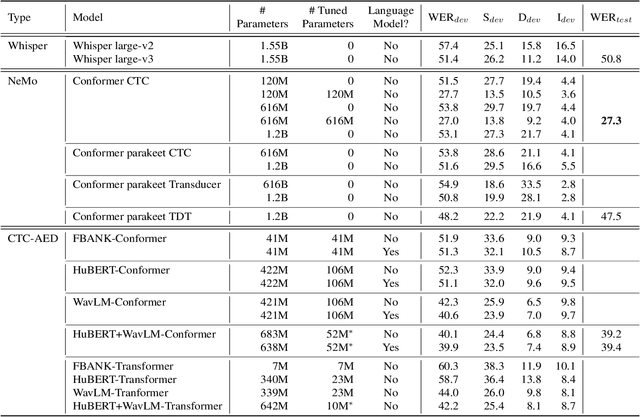

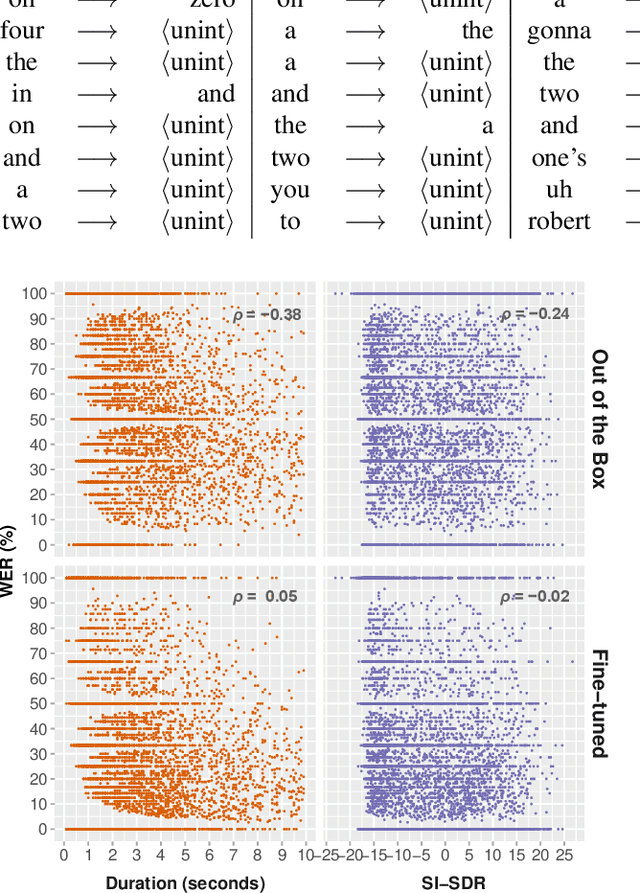
Police departments around the world use two-way radio for coordination. These broadcast police communications (BPC) are a unique source of information about everyday police activity and emergency response. Yet BPC are not transcribed, and their naturalistic audio properties make automatic transcription challenging. We collect a corpus of roughly 62,000 manually transcribed radio transmissions (~46 hours of audio) to evaluate the feasibility of automatic speech recognition (ASR) using modern recognition models. We evaluate the performance of off-the-shelf speech recognizers, models fine-tuned on BPC data, and customized end-to-end models. We find that both human and machine transcription is challenging in this domain. Large off-the-shelf ASR models perform poorly, but fine-tuned models can reach the approximate range of human performance. Our work suggests directions for future work, including analysis of short utterances and potential miscommunication in police radio interactions. We make our corpus and data annotation pipeline available to other researchers, to enable further research on recognition and analysis of police communication.
Approaching Deep Learning through the Spectral Dynamics of Weights
Aug 21, 2024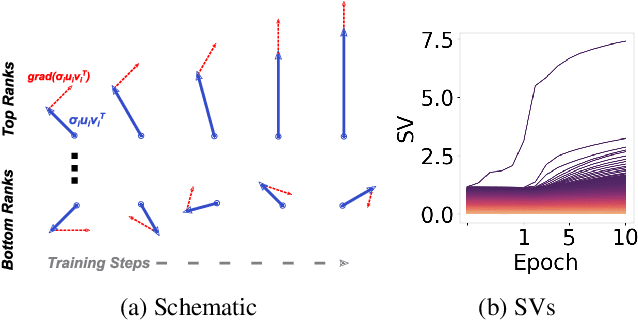
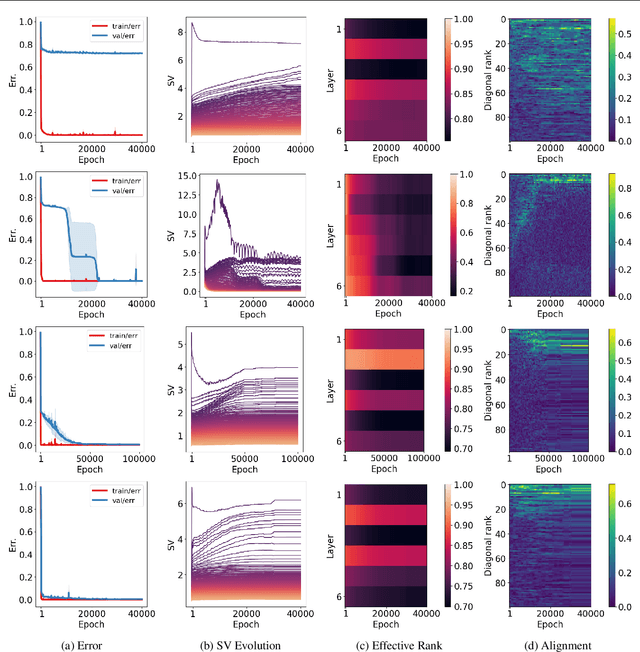
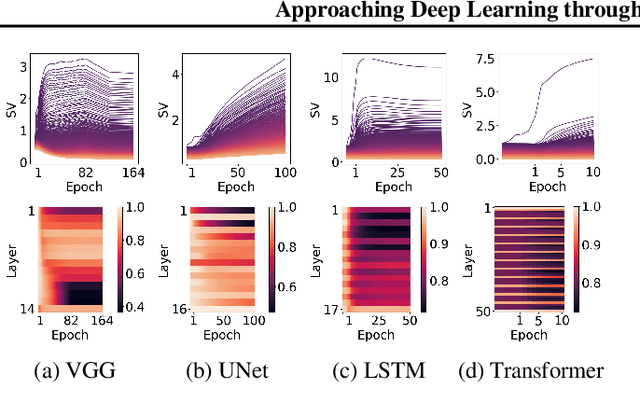
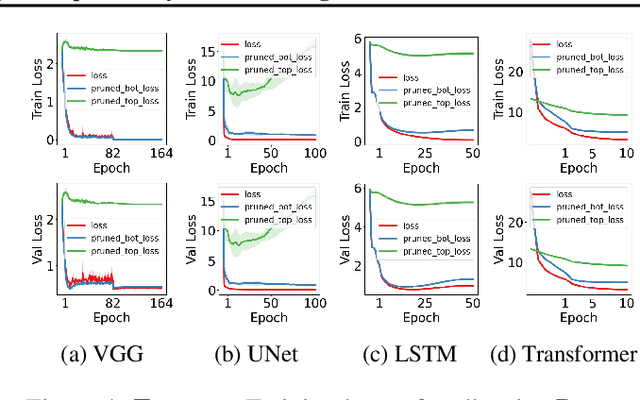
We propose an empirical approach centered on the spectral dynamics of weights -- the behavior of singular values and vectors during optimization -- to unify and clarify several phenomena in deep learning. We identify a consistent bias in optimization across various experiments, from small-scale ``grokking'' to large-scale tasks like image classification with ConvNets, image generation with UNets, speech recognition with LSTMs, and language modeling with Transformers. We also demonstrate that weight decay enhances this bias beyond its role as a norm regularizer, even in practical systems. Moreover, we show that these spectral dynamics distinguish memorizing networks from generalizing ones, offering a novel perspective on this longstanding conundrum. Additionally, we leverage spectral dynamics to explore the emergence of well-performing sparse subnetworks (lottery tickets) and the structure of the loss surface through linear mode connectivity. Our findings suggest that spectral dynamics provide a coherent framework to better understand the behavior of neural networks across diverse settings.
Towards Robust Speech Representation Learning for Thousands of Languages
Jul 02, 2024Self-supervised learning (SSL) has helped extend speech technologies to more languages by reducing the need for labeled data. However, models are still far from supporting the world's 7000+ languages. We propose XEUS, a Cross-lingual Encoder for Universal Speech, trained on over 1 million hours of data across 4057 languages, extending the language coverage of SSL models 4-fold. We combine 1 million hours of speech from existing publicly accessible corpora with a newly created corpus of 7400+ hours from 4057 languages, which will be publicly released. To handle the diverse conditions of multilingual speech data, we augment the typical SSL masked prediction approach with a novel dereverberation objective, increasing robustness. We evaluate XEUS on several benchmarks, and show that it consistently outperforms or achieves comparable results to state-of-the-art (SOTA) SSL models across a variety of tasks. XEUS sets a new SOTA on the ML-SUPERB benchmark: it outperforms MMS 1B and w2v-BERT 2.0 v2 by 0.8% and 4.4% respectively, despite having less parameters or pre-training data. Checkpoints, code, and data are found in https://www.wavlab.org/activities/2024/xeus/.