 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo You Know Where Your Camera Is? View-Invariant Policy Learning with Camera Conditioning
Oct 02, 2025We study view-invariant imitation learning by explicitly conditioning policies on camera extrinsics. Using Plucker embeddings of per-pixel rays, we show that conditioning on extrinsics significantly improves generalization across viewpoints for standard behavior cloning policies, including ACT, Diffusion Policy, and SmolVLA. To evaluate policy robustness under realistic viewpoint shifts, we introduce six manipulation tasks in RoboSuite and ManiSkill that pair "fixed" and "randomized" scene variants, decoupling background cues from camera pose. Our analysis reveals that policies without extrinsics often infer camera pose using visual cues from static backgrounds in fixed scenes; this shortcut collapses when workspace geometry or camera placement shifts. Conditioning on extrinsics restores performance and yields robust RGB-only control without depth. We release the tasks, demonstrations, and code at https://ripl.github.io/know_your_camera/ .
FlashBack: Consistency Model-Accelerated Shared Autonomy
May 22, 2025Shared autonomy is an enabling technology that provides users with control authority over robots that would otherwise be difficult if not impossible to directly control. Yet, standard methods make assumptions that limit their adoption in practice-for example, prior knowledge of the user's goals or the objective (i.e., reward) function that they wish to optimize, knowledge of the user's policy, or query-level access to the user during training. Diffusion-based approaches to shared autonomy do not make such assumptions and instead only require access to demonstrations of desired behaviors, while allowing the user to maintain control authority. However, these advantages have come at the expense of high computational complexity, which has made real-time shared autonomy all but impossible. To overcome this limitation, we propose Consistency Shared Autonomy (CSA), a shared autonomy framework that employs a consistency model-based formulation of diffusion. Key to CSA is that it employs the distilled probability flow of ordinary differential equations (PF ODE) to generate high-fidelity samples in a single step. This results in inference speeds significantly than what is possible with previous diffusion-based approaches to shared autonomy, enabling real-time assistance in complex domains with only a single function evaluation. Further, by intervening on flawed actions at intermediate states of the PF ODE, CSA enables varying levels of assistance. We evaluate CSA on a variety of challenging simulated and real-world robot control problems, demonstrating significant improvements over state-of-the-art methods both in terms of task performance and computational efficiency.
FastMap: Revisiting Dense and Scalable Structure from Motion
May 07, 2025We propose FastMap, a new global structure from motion method focused on speed and simplicity. Previous methods like COLMAP and GLOMAP are able to estimate high-precision camera poses, but suffer from poor scalability when the number of matched keypoint pairs becomes large. We identify two key factors leading to this problem: poor parallelization and computationally expensive optimization steps. To overcome these issues, we design an SfM framework that relies entirely on GPU-friendly operations, making it easily parallelizable. Moreover, each optimization step runs in time linear to the number of image pairs, independent of keypoint pairs or 3D points. Through extensive experiments, we show that FastMap is one to two orders of magnitude faster than COLMAP and GLOMAP on large-scale scenes with comparable pose accuracy.
From Vague Instructions to Task Plans: A Feedback-Driven HRC Task Planning Framework based on LLMs
Mar 02, 2025



Recent advances in large language models (LLMs) have demonstrated their potential as planners in human-robot collaboration (HRC) scenarios, offering a promising alternative to traditional planning methods. LLMs, which can generate structured plans by reasoning over natural language inputs, have the ability to generalize across diverse tasks and adapt to human instructions. This paper investigates the potential of LLMs to facilitate planning in the context of human-robot collaborative tasks, with a focus on their ability to reason from high-level, vague human inputs, and fine-tune plans based on real-time feedback. We propose a novel hybrid framework that combines LLMs with human feedback to create dynamic, context-aware task plans. Our work also highlights how a single, concise prompt can be used for a wide range of tasks and environments, overcoming the limitations of long, detailed structured prompts typically used in prior studies. By integrating user preferences into the planning loop, we ensure that the generated plans are not only effective but aligned with human intentions.
Active Advantage-Aligned Online Reinforcement Learning with Offline Data
Feb 11, 2025Online reinforcement learning (RL) enhances policies through direct interactions with the environment, but faces challenges related to sample efficiency. In contrast, offline RL leverages extensive pre-collected data to learn policies, but often produces suboptimal results due to limited data coverage. Recent efforts have sought to integrate offline and online RL in order to harness the advantages of both approaches. However, effectively combining online and offline RL remains challenging due to issues that include catastrophic forgetting, lack of robustness and sample efficiency. In an effort to address these challenges, we introduce A3 RL , a novel method that actively selects data from combined online and offline sources to optimize policy improvement. We provide theoretical guarantee that validates the effectiveness our active sampling strategy and conduct thorough empirical experiments showing that our method outperforms existing state-of-the-art online RL techniques that utilize offline data. Our code will be publicly available at: https://github.com/xuefeng-cs/A3RL.
PROGRESSOR: A Perceptually Guided Reward Estimator with Self-Supervised Online Refinement
Nov 26, 2024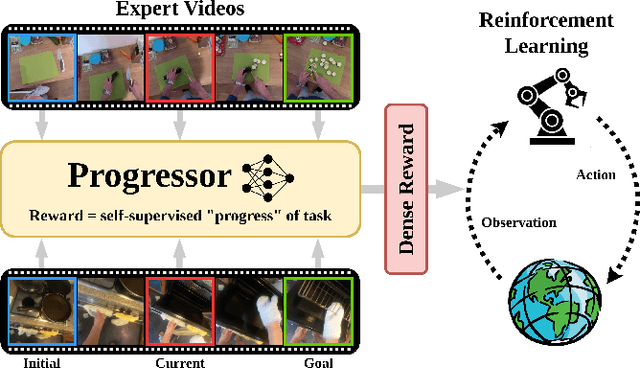
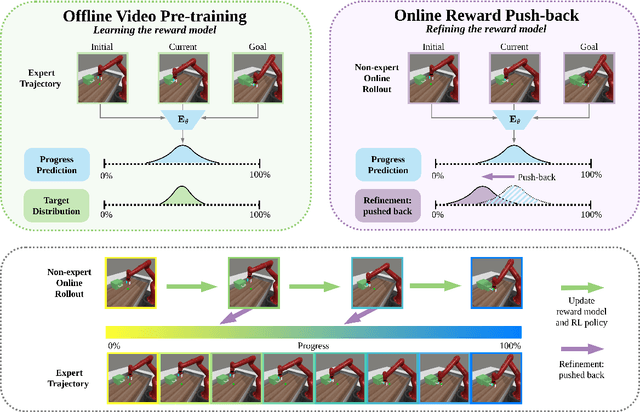

We present PROGRESSOR, a novel framework that learns a task-agnostic reward function from videos, enabling policy training through goal-conditioned reinforcement learning (RL) without manual supervision. Underlying this reward is an estimate of the distribution over task progress as a function of the current, initial, and goal observations that is learned in a self-supervised fashion. Crucially, PROGRESSOR refines rewards adversarially during online RL training by pushing back predictions for out-of-distribution observations, to mitigate distribution shift inherent in non-expert observations. Utilizing this progress prediction as a dense reward together with an adversarial push-back, we show that PROGRESSOR enables robots to learn complex behaviors without any external supervision. Pretrained on large-scale egocentric human video from EPIC-KITCHENS, PROGRESSOR requires no fine-tuning on in-domain task-specific data for generalization to real-robot offline RL under noisy demonstrations, outperforming contemporary methods that provide dense visual reward for robotic learning. Our findings highlight the potential of PROGRESSOR for scalable robotic applications where direct action labels and task-specific rewards are not readily available.
StackGen: Generating Stable Structures from Silhouettes via Diffusion
Sep 26, 2024



Humans naturally obtain intuition about the interactions between and the stability of rigid objects by observing and interacting with the world. It is this intuition that governs the way in which we regularly configure objects in our environment, allowing us to build complex structures from simple, everyday objects. Robotic agents, on the other hand, traditionally require an explicit model of the world that includes the detailed geometry of each object and an analytical model of the environment dynamics, which are difficult to scale and preclude generalization. Instead, robots would benefit from an awareness of intuitive physics that enables them to similarly reason over the stable interaction of objects in their environment. Towards that goal, we propose StackGen, a diffusion model that generates diverse stable configurations of building blocks matching a target silhouette. To demonstrate the capability of the method, we evaluate it in a simulated environment and deploy it in the real setting using a robotic arm to assemble structures generated by the model.
Approaching Deep Learning through the Spectral Dynamics of Weights
Aug 21, 2024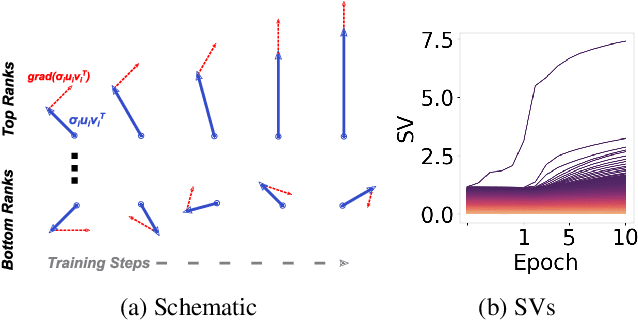
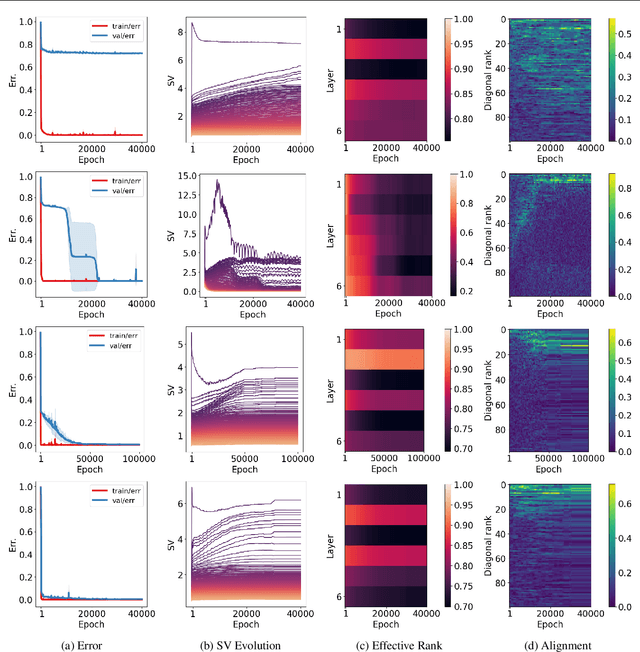
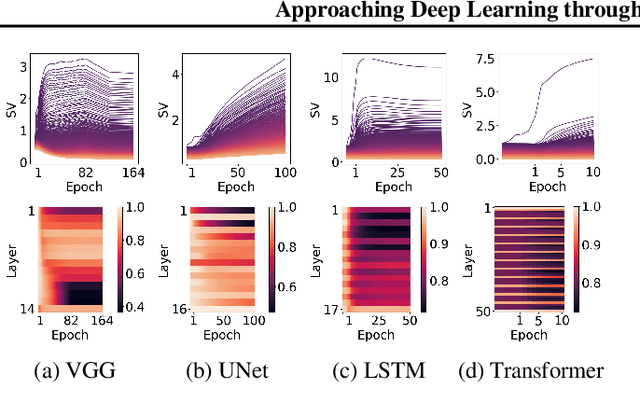
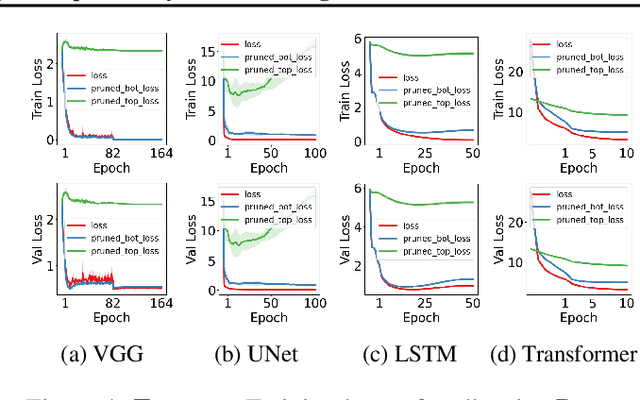
We propose an empirical approach centered on the spectral dynamics of weights -- the behavior of singular values and vectors during optimization -- to unify and clarify several phenomena in deep learning. We identify a consistent bias in optimization across various experiments, from small-scale ``grokking'' to large-scale tasks like image classification with ConvNets, image generation with UNets, speech recognition with LSTMs, and language modeling with Transformers. We also demonstrate that weight decay enhances this bias beyond its role as a norm regularizer, even in practical systems. Moreover, we show that these spectral dynamics distinguish memorizing networks from generalizing ones, offering a novel perspective on this longstanding conundrum. Additionally, we leverage spectral dynamics to explore the emergence of well-performing sparse subnetworks (lottery tickets) and the structure of the loss surface through linear mode connectivity. Our findings suggest that spectral dynamics provide a coherent framework to better understand the behavior of neural networks across diverse settings.
Learning Actionable Counterfactual Explanations in Large State Spaces
Apr 25, 2024

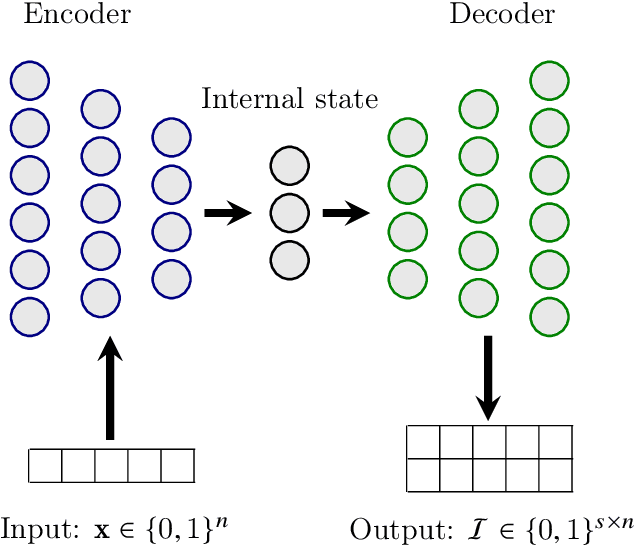

Counterfactual explanations (CFEs) are sets of actions that an agent with a negative classification could take to achieve a (desired) positive classification, for consequential decisions such as loan applications, hiring, admissions, etc. In this work, we consider settings where optimal CFEs correspond to solutions of weighted set cover problems. In particular, there is a collection of actions that agents can perform that each have their own cost and each provide the agent with different sets of capabilities. The agent wants to perform the cheapest subset of actions that together provide all the needed capabilities to achieve a positive classification. Since this is an NP-hard optimization problem, we are interested in the question: can we, from training data (instances of agents and their optimal CFEs) learn a CFE generator that will quickly provide optimal sets of actions for new agents? In this work, we provide a deep-network learning procedure that we show experimentally is able to achieve strong performance at this task. We consider several problem formulations, including formulations in which the underlying "capabilities" and effects of actions are not explicitly provided, and so there is an informational challenge in addition to the computational challenge. Our problem can also be viewed as one of learning an optimal policy in a family of large but deterministic Markov Decision Processes (MDPs).
MANGO: A Benchmark for Evaluating Mapping and Navigation Abilities of Large Language Models
Mar 29, 2024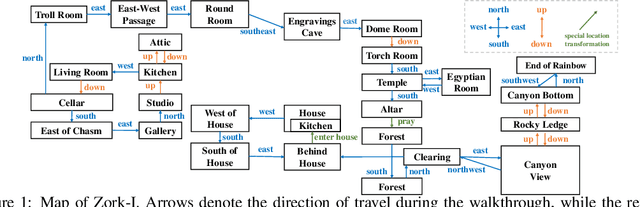
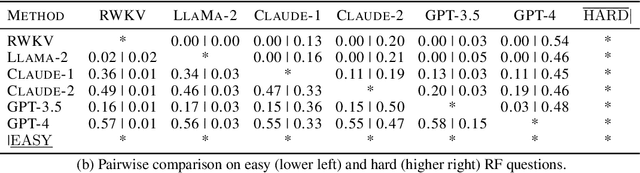
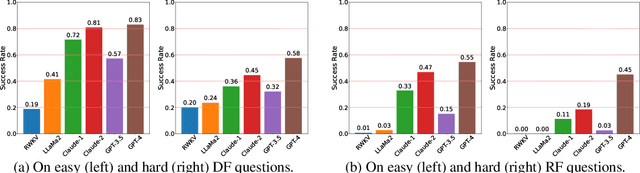
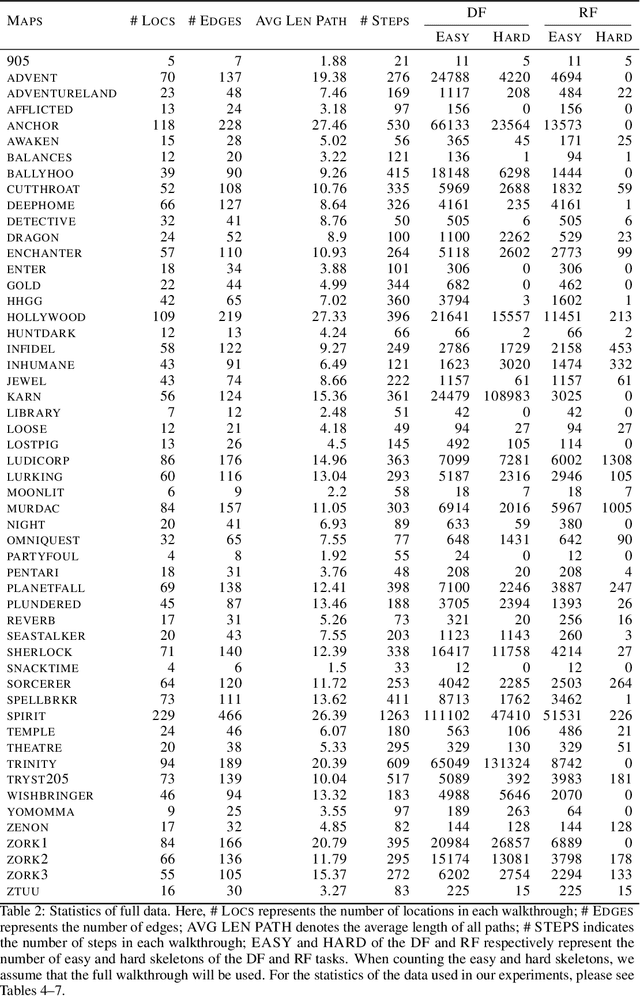
Large language models such as ChatGPT and GPT-4 have recently achieved astonishing performance on a variety of natural language processing tasks. In this paper, we propose MANGO, a benchmark to evaluate their capabilities to perform text-based mapping and navigation. Our benchmark includes 53 mazes taken from a suite of textgames: each maze is paired with a walkthrough that visits every location but does not cover all possible paths. The task is question-answering: for each maze, a large language model reads the walkthrough and answers hundreds of mapping and navigation questions such as "How should you go to Attic from West of House?" and "Where are we if we go north and east from Cellar?". Although these questions are easy to humans, it turns out that even GPT-4, the best-to-date language model, performs poorly at answering them. Further, our experiments suggest that a strong mapping and navigation ability would benefit large language models in performing relevant downstream tasks, such as playing textgames. Our MANGO benchmark will facilitate future research on methods that improve the mapping and navigation capabilities of language models. We host our leaderboard, data, code, and evaluation program at https://mango.ttic.edu and https://github.com/oaklight/mango/.