 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlashBack: Consistency Model-Accelerated Shared Autonomy
May 22, 2025Shared autonomy is an enabling technology that provides users with control authority over robots that would otherwise be difficult if not impossible to directly control. Yet, standard methods make assumptions that limit their adoption in practice-for example, prior knowledge of the user's goals or the objective (i.e., reward) function that they wish to optimize, knowledge of the user's policy, or query-level access to the user during training. Diffusion-based approaches to shared autonomy do not make such assumptions and instead only require access to demonstrations of desired behaviors, while allowing the user to maintain control authority. However, these advantages have come at the expense of high computational complexity, which has made real-time shared autonomy all but impossible. To overcome this limitation, we propose Consistency Shared Autonomy (CSA), a shared autonomy framework that employs a consistency model-based formulation of diffusion. Key to CSA is that it employs the distilled probability flow of ordinary differential equations (PF ODE) to generate high-fidelity samples in a single step. This results in inference speeds significantly than what is possible with previous diffusion-based approaches to shared autonomy, enabling real-time assistance in complex domains with only a single function evaluation. Further, by intervening on flawed actions at intermediate states of the PF ODE, CSA enables varying levels of assistance. We evaluate CSA on a variety of challenging simulated and real-world robot control problems, demonstrating significant improvements over state-of-the-art methods both in terms of task performance and computational efficiency.
StackGen: Generating Stable Structures from Silhouettes via Diffusion
Sep 26, 2024



Humans naturally obtain intuition about the interactions between and the stability of rigid objects by observing and interacting with the world. It is this intuition that governs the way in which we regularly configure objects in our environment, allowing us to build complex structures from simple, everyday objects. Robotic agents, on the other hand, traditionally require an explicit model of the world that includes the detailed geometry of each object and an analytical model of the environment dynamics, which are difficult to scale and preclude generalization. Instead, robots would benefit from an awareness of intuitive physics that enables them to similarly reason over the stable interaction of objects in their environment. Towards that goal, we propose StackGen, a diffusion model that generates diverse stable configurations of building blocks matching a target silhouette. To demonstrate the capability of the method, we evaluate it in a simulated environment and deploy it in the real setting using a robotic arm to assemble structures generated by the model.
To the Noise and Back: Diffusion for Shared Autonomy
Feb 24, 2023



Shared autonomy is an operational concept in which a user and an autonomous agent collaboratively control a robotic system. It provides a number of advantages over the extremes of full-teleoperation and full-autonomy in many settings. Traditional approaches to shared autonomy rely on knowledge of the environment dynamics, a discrete space of user goals that is known a priori, or knowledge of the user's policy -- assumptions that are unrealistic in many domains. Recent works relax some of these assumptions by formulating shared autonomy with model-free deep reinforcement learning (RL). In particular, they no longer need knowledge of the goal space (e.g., that the goals are discrete or constrained) or environment dynamics. However, they need knowledge of a task-specific reward function to train the policy. Unfortunately, such reward specification can be a difficult and brittle process. On top of that, the formulations inherently rely on human-in-the-loop training, and that necessitates them to prepare a policy that mimics users' behavior. In this paper, we present a new approach to shared autonomy that employs a modulation of the forward and reverse diffusion process of diffusion models. Our approach does not assume known environment dynamics or the space of user goals, and in contrast to previous work, it does not require any reward feedback, nor does it require access to the user's policy during training. Instead, our framework learns a distribution over a space of desired behaviors. It then employs a diffusion model to translate the user's actions to a sample from this distribution. Crucially, we show that it is possible to carry out this process in a manner that preserves the user's control authority. We evaluate our framework on a series of challenging continuous control tasks, and analyze its ability to effectively correct user actions while maintaining their autonomy.
Decompositional Quantum Graph Neural Network
Jan 13, 2022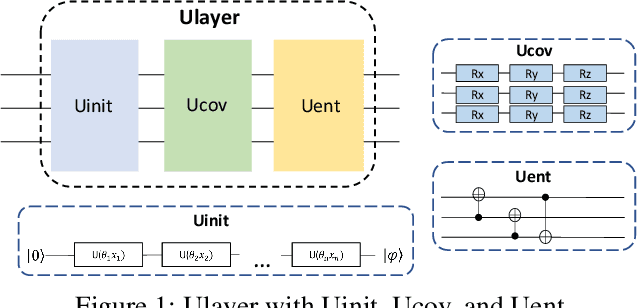
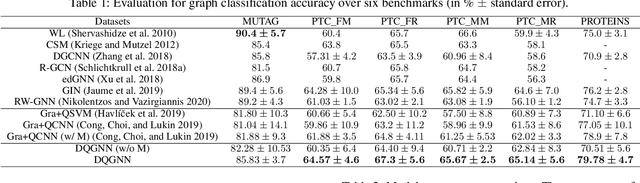
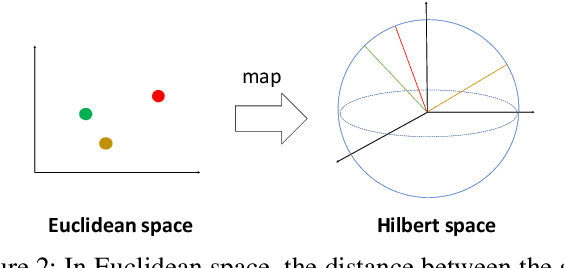
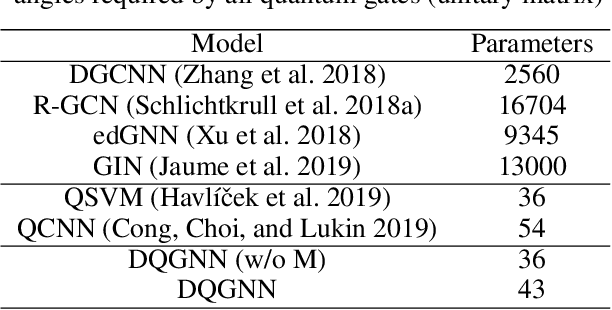
Quantum machine learning is a fast emerging field that aims to tackle machine learning using quantum algorithms and quantum computing. Due to the lack of physical qubits and an effective means to map real-world data from Euclidean space to Hilbert space, most of these methods focus on quantum analogies or process simulations rather than devising concrete architectures based on qubits. In this paper, we propose a novel hybrid quantum-classical algorithm for graph-structured data, which we refer to as the Decompositional Quantum Graph Neural Network (DQGNN). DQGNN implements the GNN theoretical framework using the tensor product and unity matrices representation, which greatly reduces the number of model parameters required. When controlled by a classical computer, DQGNN can accommodate arbitrarily sized graphs by processing substructures from the input graph using a modestly-sized quantum device. The architecture is based on a novel mapping from real-world data to Hilbert space. This mapping maintains the distance relations present in the data and reduces information loss. Experimental results show that the proposed method outperforms competitive state-of-the-art models with only 1.68\% parameters compared to those models.