 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHapCompass: A Rotational Haptic Device for Contact-Rich Robotic Teleoperation
Mar 31, 2026The contact-rich nature of manipulation makes it a significant challenge for robotic teleoperation. While haptic feedback is critical for contact-rich tasks, providing intuitive directional cues within wearable teleoperation interfaces remains a bottleneck. Existing solutions, such as non-directional vibrations from handheld controllers, provide limited information, while vibrotactile arrays are prone to perceptual interference. To address these limitations, we propose HapCompass, a novel, low-cost wearable haptic device that renders 2D directional cues by mechanically rotating a single linear resonant actuator (LRA). We evaluated HapCompass's ability to convey directional cues to human operators and showed that it increased the success rate, decreased the completion time and the maximum contact force for teleoperated manipulation tasks when compared to vision-only and non-directional feedback baselines. Furthermore, we conducted a preliminary imitation-learning evaluation, suggesting that the directional feedback provided by HapCompass enhances the quality of demonstration data and, in turn, the trained policy. We release the design of the HapCompass device along with the code that implements our teleoperation interface: https://ripl.github.io/HapCompass/.
The Model Says Walk: How Surface Heuristics Override Implicit Constraints in LLM Reasoning
Mar 30, 2026Large language models systematically fail when a salient surface cue conflicts with an unstated feasibility constraint. We study this through a diagnose-measure-bridge-treat framework. Causal-behavioral analysis of the ``car wash problem'' across six models reveals approximately context-independent sigmoid heuristics: the distance cue exerts 8.7 to 38 times more influence than the goal, and token-level attribution shows patterns more consistent with keyword associations than compositional inference. The Heuristic Override Benchmark (HOB) -- 500 instances spanning 4 heuristic by 5 constraint families with minimal pairs and explicitness gradients -- demonstrates generality across 14 models: under strict evaluation (10/10 correct), no model exceeds 75%, and presence constraints are hardest (44%). A minimal hint (e.g., emphasizing the key object) recovers +15 pp on average, suggesting the failure lies in constraint inference rather than missing knowledge; 12/14 models perform worse when the constraint is removed (up to -39 pp), revealing conservative bias. Parametric probes confirm that the sigmoid pattern generalizes to cost, efficiency, and semantic-similarity heuristics; goal-decomposition prompting recovers +6 to 9 pp by forcing models to enumerate preconditions before answering. Together, these results characterize heuristic override as a systematic reasoning vulnerability and provide a benchmark for measuring progress toward resolving it.
Do You Know Where Your Camera Is? View-Invariant Policy Learning with Camera Conditioning
Oct 02, 2025We study view-invariant imitation learning by explicitly conditioning policies on camera extrinsics. Using Plucker embeddings of per-pixel rays, we show that conditioning on extrinsics significantly improves generalization across viewpoints for standard behavior cloning policies, including ACT, Diffusion Policy, and SmolVLA. To evaluate policy robustness under realistic viewpoint shifts, we introduce six manipulation tasks in RoboSuite and ManiSkill that pair "fixed" and "randomized" scene variants, decoupling background cues from camera pose. Our analysis reveals that policies without extrinsics often infer camera pose using visual cues from static backgrounds in fixed scenes; this shortcut collapses when workspace geometry or camera placement shifts. Conditioning on extrinsics restores performance and yields robust RGB-only control without depth. We release the tasks, demonstrations, and code at https://ripl.github.io/know_your_camera/ .
PROGRESSOR: A Perceptually Guided Reward Estimator with Self-Supervised Online Refinement
Nov 26, 2024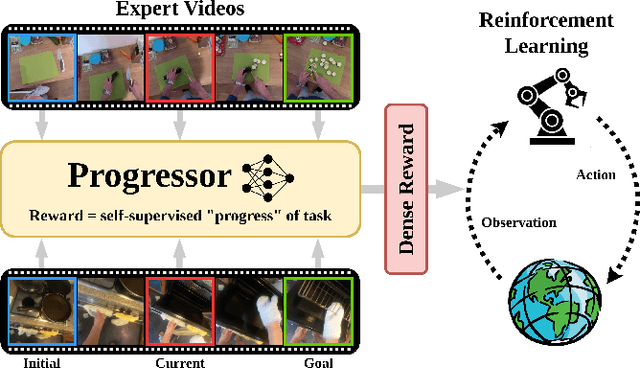
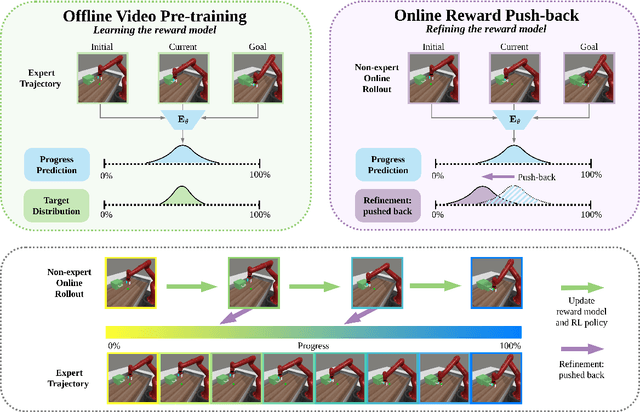

We present PROGRESSOR, a novel framework that learns a task-agnostic reward function from videos, enabling policy training through goal-conditioned reinforcement learning (RL) without manual supervision. Underlying this reward is an estimate of the distribution over task progress as a function of the current, initial, and goal observations that is learned in a self-supervised fashion. Crucially, PROGRESSOR refines rewards adversarially during online RL training by pushing back predictions for out-of-distribution observations, to mitigate distribution shift inherent in non-expert observations. Utilizing this progress prediction as a dense reward together with an adversarial push-back, we show that PROGRESSOR enables robots to learn complex behaviors without any external supervision. Pretrained on large-scale egocentric human video from EPIC-KITCHENS, PROGRESSOR requires no fine-tuning on in-domain task-specific data for generalization to real-robot offline RL under noisy demonstrations, outperforming contemporary methods that provide dense visual reward for robotic learning. Our findings highlight the potential of PROGRESSOR for scalable robotic applications where direct action labels and task-specific rewards are not readily available.
StackGen: Generating Stable Structures from Silhouettes via Diffusion
Sep 26, 2024



Humans naturally obtain intuition about the interactions between and the stability of rigid objects by observing and interacting with the world. It is this intuition that governs the way in which we regularly configure objects in our environment, allowing us to build complex structures from simple, everyday objects. Robotic agents, on the other hand, traditionally require an explicit model of the world that includes the detailed geometry of each object and an analytical model of the environment dynamics, which are difficult to scale and preclude generalization. Instead, robots would benefit from an awareness of intuitive physics that enables them to similarly reason over the stable interaction of objects in their environment. Towards that goal, we propose StackGen, a diffusion model that generates diverse stable configurations of building blocks matching a target silhouette. To demonstrate the capability of the method, we evaluate it in a simulated environment and deploy it in the real setting using a robotic arm to assemble structures generated by the model.
6-DoF Stability Field via Diffusion Models
Oct 26, 2023A core capability for robot manipulation is reasoning over where and how to stably place objects in cluttered environments. Traditionally, robots have relied on object-specific, hand-crafted heuristics in order to perform such reasoning, with limited generalizability beyond a small number of object instances and object interaction patterns. Recent approaches instead learn notions of physical interaction, namely motion prediction, but require supervision in the form of labeled object information or come at the cost of high sample complexity, and do not directly reason over stability or object placement. We present 6-DoFusion, a generative model capable of generating 3D poses of an object that produces a stable configuration of a given scene. Underlying 6-DoFusion is a diffusion model that incrementally refines a randomly initialized SE(3) pose to generate a sample from a learned, context-dependent distribution over stable poses. We evaluate our model on different object placement and stacking tasks, demonstrating its ability to construct stable scenes that involve novel object classes as well as to improve the accuracy of state-of-the-art 3D pose estimation methods.
Statler: State-Maintaining Language Models for Embodied Reasoning
Jul 03, 2023



Large language models (LLMs) provide a promising tool that enable robots to perform complex robot reasoning tasks. However, the limited context window of contemporary LLMs makes reasoning over long time horizons difficult. Embodied tasks such as those that one might expect a household robot to perform typically require that the planner consider information acquired a long time ago (e.g., properties of the many objects that the robot previously encountered in the environment). Attempts to capture the world state using an LLM's implicit internal representation is complicated by the paucity of task- and environment-relevant information available in a robot's action history, while methods that rely on the ability to convey information via the prompt to the LLM are subject to its limited context window. In this paper, we propose Statler, a framework that endows LLMs with an explicit representation of the world state as a form of ``memory'' that is maintained over time. Integral to Statler is its use of two instances of general LLMs -- a world-model reader and a world-model writer -- that interface with and maintain the world state. By providing access to this world state ``memory'', Statler improves the ability of existing LLMs to reason over longer time horizons without the constraint of context length. We evaluate the effectiveness of our approach on three simulated table-top manipulation domains and a real robot domain, and show that it improves the state-of-the-art in LLM-based robot reasoning. Project website: https://statler-lm.github.io/