 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContact-Anchored Policies: Contact Conditioning Creates Strong Robot Utility Models
Feb 09, 2026The prevalent paradigm in robot learning attempts to generalize across environments, embodiments, and tasks with language prompts at runtime. A fundamental tension limits this approach: language is often too abstract to guide the concrete physical understanding required for robust manipulation. In this work, we introduce Contact-Anchored Policies (CAP), which replace language conditioning with points of physical contact in space. Simultaneously, we structure CAP as a library of modular utility models rather than a monolithic generalist policy. This factorization allows us to implement a real-to-sim iteration cycle: we build EgoGym, a lightweight simulation benchmark, to rapidly identify failure modes and refine our models and datasets prior to real-world deployment. We show that by conditioning on contact and iterating via simulation, CAP generalizes to novel environments and embodiments out of the box on three fundamental manipulation skills while using only 23 hours of demonstration data, and outperforms large, state-of-the-art VLAs in zero-shot evaluations by 56%. All model checkpoints, codebase, hardware, simulation, and datasets will be open-sourced. Project page: https://cap-policy.github.io/
PROGRESSOR: A Perceptually Guided Reward Estimator with Self-Supervised Online Refinement
Nov 26, 2024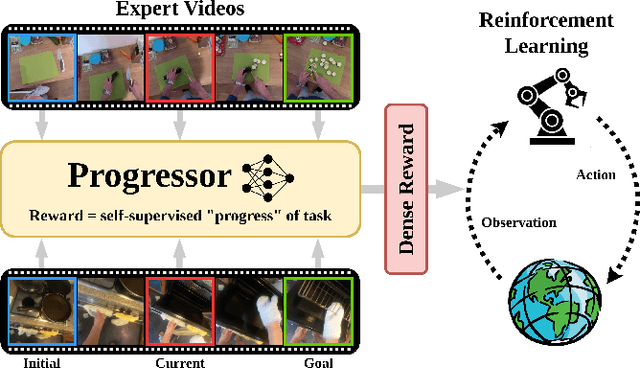
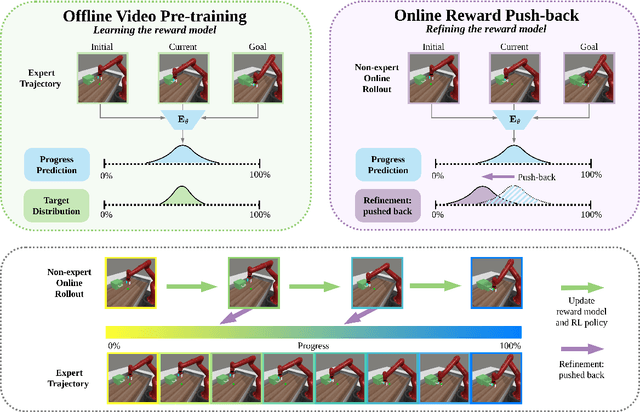

We present PROGRESSOR, a novel framework that learns a task-agnostic reward function from videos, enabling policy training through goal-conditioned reinforcement learning (RL) without manual supervision. Underlying this reward is an estimate of the distribution over task progress as a function of the current, initial, and goal observations that is learned in a self-supervised fashion. Crucially, PROGRESSOR refines rewards adversarially during online RL training by pushing back predictions for out-of-distribution observations, to mitigate distribution shift inherent in non-expert observations. Utilizing this progress prediction as a dense reward together with an adversarial push-back, we show that PROGRESSOR enables robots to learn complex behaviors without any external supervision. Pretrained on large-scale egocentric human video from EPIC-KITCHENS, PROGRESSOR requires no fine-tuning on in-domain task-specific data for generalization to real-robot offline RL under noisy demonstrations, outperforming contemporary methods that provide dense visual reward for robotic learning. Our findings highlight the potential of PROGRESSOR for scalable robotic applications where direct action labels and task-specific rewards are not readily available.
Emergenet: A Digital Twin of Sequence Evolution for Scalable Emergence Risk Assessment of Animal Influenza A Strains
Nov 26, 2024Despite having triggered devastating pandemics in the past, our ability to quantitatively assess the emergence potential of individual strains of animal influenza viruses remains limited. This study introduces Emergenet, a tool to infer a digital twin of sequence evolution to chart how new variants might emerge in the wild. Our predictions based on Emergenets built only using 220,151 Hemagglutinnin (HA) sequences consistently outperform WHO seasonal vaccine recommendations for H1N1/H3N2 subtypes over two decades (average match-improvement: 3.73 AAs, 28.40\%), and are at par with state-of-the-art approaches that use more detailed phenotypic annotations. Finally, our generative models are used to scalably calculate the current odds of emergence of animal strains not yet in human circulation, which strongly correlates with CDC's expert-assessed Influenza Risk Assessment Tool (IRAT) scores (Pearson's $r = 0.721, p = 10^{-4}$). A minimum five orders of magnitude speedup over CDC's assessment (seconds vs months) then enabled us to analyze 6,354 animal strains collected post-2020 to identify 35 strains with high emergence scores ($> 7.7$). The Emergenet framework opens the door to preemptive pandemic mitigation through targeted inoculation of animal hosts before the first human infection.