 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Clinical Diagnosis with Counterfactual Multi-Agent Reasoning
Mar 29, 2026Clinical diagnosis is a complex reasoning process in which clinicians gather evidence, form hypotheses, and test them against alternative explanations. In medical training, this reasoning is explicitly developed through counterfactual questioning--e.g., asking how a diagnosis would change if a key symptom were absent or altered--to strengthen differential diagnosis skills. As large language model (LLM)-based systems are increasingly used for diagnostic support, ensuring the interpretability of their recommendations becomes critical. However, most existing LLM-based diagnostic agents reason over fixed clinical evidence without explicitly testing how individual findings support or weaken competing diagnoses. In this work, we propose a counterfactual multi-agent diagnostic framework inspired by clinician training that makes hypothesis testing explicit and evidence-grounded. Our framework introduces counterfactual case editing to modify clinical findings and evaluate how these changes affect competing diagnoses. We further define the Counterfactual Probability Gap, a method that quantifies how strongly individual findings support a diagnosis by measuring confidence shifts under these edits. These counterfactual signals guide multi-round specialist discussions, enabling agents to challenge unsupported hypotheses, refine differential diagnoses, and produce more interpretable reasoning trajectories. Across three diagnostic benchmarks and seven LLMs, our method consistently improves diagnostic accuracy over prompting and prior multi-agent baselines, with the largest gains observed in complex and ambiguous cases. Human evaluation further indicates that our framework produces more clinically useful, reliable, and coherent reasoning. These results suggest that incorporating counterfactual evidence verification is an important step toward building reliable AI systems for clinical decision support.
MEMO: Memory-Augmented Model Context Optimization for Robust Multi-Turn Multi-Agent LLM Games
Mar 09, 2026Multi-turn, multi-agent LLM game evaluations often exhibit substantial run-to-run variance. In long-horizon interactions, small early deviations compound across turns and are amplified by multi-agent coupling. This biases win rate estimates and makes rankings unreliable across repeated tournaments. Prompt choice worsens this further by producing different effective policies. We address both instability and underperformance with MEMO (Memory-augmented MOdel context optimization), a self-play framework that optimizes inference-time context by coupling retention and exploration. Retention maintains a persistent memory bank that stores structured insights from self-play trajectories and injects them as priors during later play. Exploration runs tournament-style prompt evolution with uncertainty-aware selection via TrueSkill, and uses prioritized replay to revisit rare and decisive states. Across five text-based games, MEMO raises mean win rate from 25.1% to 49.5% for GPT-4o-mini and from 20.9% to 44.3% for Qwen-2.5-7B-Instruct, using $2,000$ self-play games per task. Run-to-run variance also drops, giving more stable rankings across prompt variations. These results suggest that multi-agent LLM game performance and robustness have substantial room for improvement through context optimization. MEMO achieves the largest gains in negotiation and imperfect-information games, while RL remains more effective in perfect-information settings.
$ abla$-Reasoner: LLM Reasoning via Test-Time Gradient Descent in Latent Space
Mar 05, 2026Scaling inference-time compute for Large Language Models (LLMs) has unlocked unprecedented reasoning capabilities. However, existing inference-time scaling methods typically rely on inefficient and suboptimal discrete search algorithms or trial-and-error prompting to improve the online policy. In this paper, we propose $\nabla$-Reasoner, an iterative generation framework that integrates differentiable optimization over token logits into the decoding loop to refine the policy on the fly. Our core component, Differentiable Textual Optimization (DTO), leverages gradient signals from both the LLM's likelihood and a reward model to refine textual representations. $\nabla$-Reasoner further incorporates rejection sampling and acceleration design to robustify and speed up decoding. Theoretically, we show that performing inference-time gradient descent in the sample space to maximize reward is dual to aligning an LLM policy via KL-regularized reinforcement learning. Empirically, $\nabla$-Reasoner achieves over 20% accuracy improvement on a challenging mathematical reasoning benchmark, while reducing number of model calls by approximately 10-40% compared to strong baselines. Overall, our work introduces a paradigm shift from zeroth-order search to first-order optimization at test time, offering a cost-effective path to amplify LLM reasoning.
Generalization of RLVR Using Causal Reasoning as a Testbed
Dec 23, 2025Reinforcement learning with verifiable rewards (RLVR) has emerged as a promising paradigm for post-training large language models (LLMs) on complex reasoning tasks. Yet, the conditions under which RLVR yields robust generalization remain poorly understood. This paper provides an empirical study of RLVR generalization in the setting of probabilistic inference over causal graphical models. This setting offers two natural axes along which to examine generalization: (i) the level of the probabilistic query -- associational, interventional, or counterfactual -- and (ii) the structural complexity of the query, measured by the size of its relevant subgraph. We construct datasets of causal graphs and queries spanning these difficulty axes and fine-tune Qwen-2.5-Instruct models using RLVR or supervised fine-tuning (SFT). We vary both the model scale (3B-32B) and the query level included in training. We find that RLVR yields stronger within-level and across-level generalization than SFT, but only for specific combinations of model size and training query level. Further analysis shows that RLVR's effectiveness depends on the model's initial reasoning competence. With sufficient initial competence, RLVR improves an LLM's marginalization strategy and reduces errors in intermediate probability calculations, producing substantial accuracy gains, particularly on more complex queries. These findings show that RLVR can improve specific causal reasoning subskills, with its benefits emerging only when the model has sufficient initial competence.
Executable Counterfactuals: Improving LLMs' Causal Reasoning Through Code
Oct 02, 2025Counterfactual reasoning, a hallmark of intelligence, consists of three steps: inferring latent variables from observations (abduction), constructing alternatives (interventions), and predicting their outcomes (prediction). This skill is essential for advancing LLMs' causal understanding and expanding their applications in high-stakes domains such as scientific research. However, existing efforts in assessing LLM's counterfactual reasoning capabilities tend to skip the abduction step, effectively reducing to interventional reasoning and leading to overestimation of LLM performance. To address this, we introduce executable counterfactuals, a novel framework that operationalizes causal reasoning through code and math problems. Our framework explicitly requires all three steps of counterfactual reasoning and enables scalable synthetic data creation with varying difficulty, creating a frontier for evaluating and improving LLM's reasoning. Our results reveal substantial drop in accuracy (25-40%) from interventional to counterfactual reasoning for SOTA models like o4-mini and Claude-4-Sonnet. To address this gap, we construct a training set comprising counterfactual code problems having if-else condition and test on out-of-domain code structures (e.g. having while-loop); we also test whether a model trained on code would generalize to counterfactual math word problems. While supervised finetuning on stronger models' reasoning traces improves in-domain performance of Qwen models, it leads to a decrease in accuracy on OOD tasks such as counterfactual math problems. In contrast, reinforcement learning induces the core cognitive behaviors and generalizes to new domains, yielding gains over the base model on both code (improvement of 1.5x-2x) and math problems. Analysis of the reasoning traces reinforces these findings and highlights the promise of RL for improving LLMs' counterfactual reasoning.
FlowRL: Matching Reward Distributions for LLM Reasoning
Sep 18, 2025We propose FlowRL: matching the full reward distribution via flow balancing instead of maximizing rewards in large language model (LLM) reinforcement learning (RL). Recent advanced reasoning models adopt reward-maximizing methods (\eg, PPO and GRPO), which tend to over-optimize dominant reward signals while neglecting less frequent but valid reasoning paths, thus reducing diversity. In contrast, we transform scalar rewards into a normalized target distribution using a learnable partition function, and then minimize the reverse KL divergence between the policy and the target distribution. We implement this idea as a flow-balanced optimization method that promotes diverse exploration and generalizable reasoning trajectories. We conduct experiments on math and code reasoning tasks: FlowRL achieves a significant average improvement of $10.0\%$ over GRPO and $5.1\%$ over PPO on math benchmarks, and performs consistently better on code reasoning tasks. These results highlight reward distribution-matching as a key step toward efficient exploration and diverse reasoning in LLM reinforcement learning.
Creativity or Brute Force? Using Brainteasers as a Window into the Problem-Solving Abilities of Large Language Models
May 16, 2025
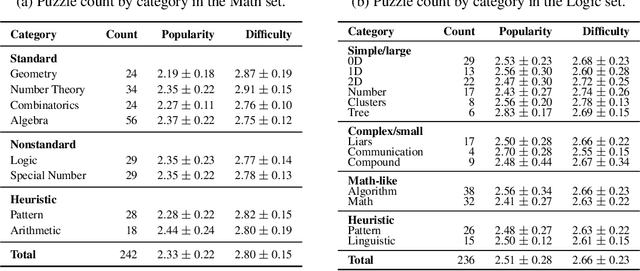

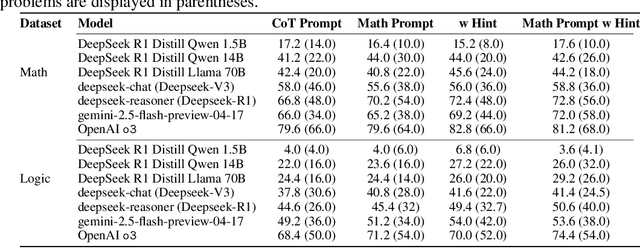
Accuracy remains a standard metric for evaluating AI systems, but it offers limited insight into how models arrive at their solutions. In this work, we introduce a benchmark based on brainteasers written in long narrative form to probe more deeply into the types of reasoning strategies that models use. Brainteasers are well-suited for this goal because they can be solved with multiple approaches, such as a few-step solution that uses a creative insight or a longer solution that uses more brute force. We investigate large language models (LLMs) across multiple layers of reasoning, focusing not only on correctness but also on the quality and creativity of their solutions. We investigate many aspects of the reasoning process: (1) semantic parsing of the brainteasers into precise mathematical competition style formats; (2) generating solutions from these mathematical forms; (3) self-correcting solutions based on gold solutions; (4) producing step-by-step sketches of solutions; and (5) making use of hints. We find that LLMs are in many cases able to find creative, insightful solutions to brainteasers, suggesting that they capture some of the capacities needed to solve novel problems in creative ways. Nonetheless, there also remain situations where they rely on brute force despite the availability of more efficient, creative solutions, highlighting a potential direction for improvement in the reasoning abilities of LLMs.
CaseSumm: A Large-Scale Dataset for Long-Context Summarization from U.S. Supreme Court Opinions
Dec 30, 2024This paper introduces CaseSumm, a novel dataset for long-context summarization in the legal domain that addresses the need for longer and more complex datasets for summarization evaluation. We collect 25.6K U.S. Supreme Court (SCOTUS) opinions and their official summaries, known as "syllabuses." Our dataset is the largest open legal case summarization dataset, and is the first to include summaries of SCOTUS decisions dating back to 1815. We also present a comprehensive evaluation of LLM-generated summaries using both automatic metrics and expert human evaluation, revealing discrepancies between these assessment methods. Our evaluation shows Mistral 7b, a smaller open-source model, outperforms larger models on most automatic metrics and successfully generates syllabus-like summaries. In contrast, human expert annotators indicate that Mistral summaries contain hallucinations. The annotators consistently rank GPT-4 summaries as clearer and exhibiting greater sensitivity and specificity. Further, we find that LLM-based evaluations are not more correlated with human evaluations than traditional automatic metrics. Furthermore, our analysis identifies specific hallucinations in generated summaries, including precedent citation errors and misrepresentations of case facts. These findings demonstrate the limitations of current automatic evaluation methods for legal summarization and highlight the critical role of human evaluation in assessing summary quality, particularly in complex, high-stakes domains. CaseSumm is available at https://huggingface.co/datasets/ChicagoHAI/CaseSumm
FAMMA: A Benchmark for Financial Domain Multilingual Multimodal Question Answering
Oct 06, 2024



In this paper, we introduce FAMMA, an open-source benchmark for financial multilingual multimodal question answering (QA). Our benchmark aims to evaluate the abilities of multimodal large language models (MLLMs) in answering questions that require advanced financial knowledge and sophisticated reasoning. It includes 1,758 meticulously collected question-answer pairs from university textbooks and exams, spanning 8 major subfields in finance including corporate finance, asset management, and financial engineering. Some of the QA pairs are written in Chinese or French, while a majority of them are in English. These questions are presented in a mixed format combining text and heterogeneous image types, such as charts, tables, and diagrams. We evaluate a range of state-of-the-art MLLMs on our benchmark, and our analysis shows that FAMMA poses a significant challenge for these models. Even advanced systems like GPT-4o and Claude-35-Sonnet achieve only 42\% accuracy. Additionally, the open-source Qwen2-VL lags notably behind its proprietary counterparts. Lastly, we explore GPT o1-style reasoning chains to enhance the models' reasoning capabilities, which significantly improve error correction. Our FAMMA benchmark will facilitate future research to develop expert systems in financial QA. The leaderboard is available at https://famma-bench.github.io/famma/ .
GMP-AR: Granularity Message Passing and Adaptive Reconciliation for Temporal Hierarchy Forecasting
Jun 18, 2024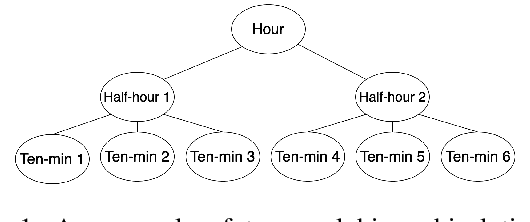
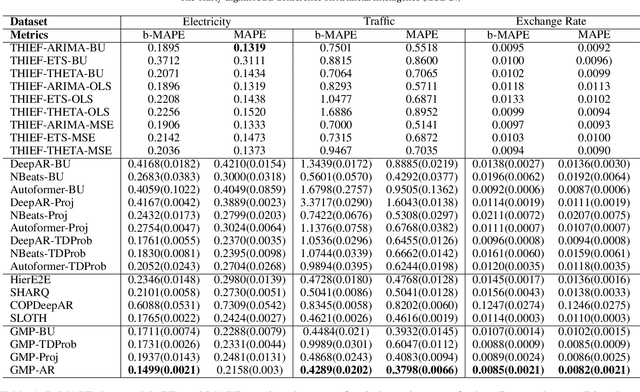
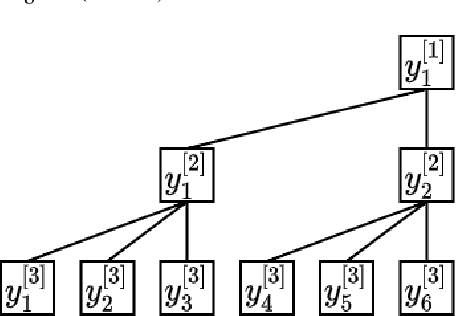
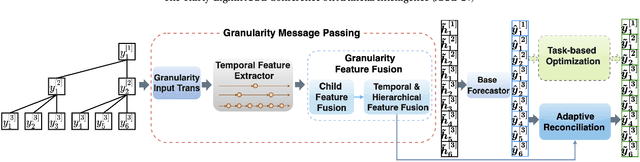
Time series forecasts of different temporal granularity are widely used in real-world applications, e.g., sales prediction in days and weeks for making different inventory plans. However, these tasks are usually solved separately without ensuring coherence, which is crucial for aligning downstream decisions. Previous works mainly focus on ensuring coherence with some straightforward methods, e.g., aggregation from the forecasts of fine granularity to the coarse ones, and allocation from the coarse granularity to the fine ones. These methods merely take the temporal hierarchical structure to maintain coherence without improving the forecasting accuracy. In this paper, we propose a novel granularity message-passing mechanism (GMP) that leverages temporal hierarchy information to improve forecasting performance and also utilizes an adaptive reconciliation (AR) strategy to maintain coherence without performance loss. Furthermore, we introduce an optimization module to achieve task-based targets while adhering to more real-world constraints. Experiments on real-world datasets demonstrate that our framework (GMP-AR) achieves superior performances on temporal hierarchical forecasting tasks compared to state-of-the-art methods. In addition, our framework has been successfully applied to a real-world task of payment traffic management in Alipay by integrating with the task-based optimization module.